Scrapy实践-爬取当当网书籍信息
Python Scrapy库爬虫——爬取当当网书籍
实现爬虫获得豆瓣书籍信息存入数据库中,学习记录
- 根据分类获取书籍信息,包括书籍名字、作者、出版社、出版日期、价格等信息
- 根据书籍类别存入数据库
完整爬取步骤
一. 设计数据库结构
二. 分析当当网页结构
三. 编写Spider类,抽取关键内容
四. 编写ItemPipeline实现保存数据数据到数据库
五. 开始爬取
一.数据库设计
- 主表books保存书籍信息
- Authors保存作者信息
- types保存书籍的类别信息
- comment保存书籍的评论等信息
books
CREATE TABLE books
(
book_tag VARCHAR(100) NOT NULL #book标识符,唯一主键
PRIMARY KEY,
a_tag VARCHAR(100) NULL, #作者标识符,Authors表外键
t_type VARCHAR(100) NULL, #类型标识符,types表外键
b_name VARCHAR(100) NULL, #书籍名称
publishing_company VARCHAR(100) NULL, #出版社
time DATE NULL, #出版时间
star_level INT NULL, #星级
price FLOAT(8, 2) NULL, #价格
isbn VARCHAR(20) NULL, #isbn
brief VARCHAR(1000) NULL, #描述
info LONGTEXT NULL, #简要信息
link VARCHAR(100) NULL, #链接
CONSTRAINT FK_Relationship_1
FOREIGN KEY (a_tag) REFERENCES Authors (a_tag)
ON UPDATE CASCADE
ON DELETE CASCADE,
CONSTRAINT FK_Relationship_2
FOREIGN KEY (t_type) REFERENCES types (t_type)
ON UPDATE CASCADE
ON DELETE CASCADE
)
ENGINE = InnoDB;
CREATE INDEX FK_Relationship_1
ON books (a_tag);
CREATE INDEX FK_Relationship_2
ON books (t_type);
Authors
CREATE TABLE Authors
(
a_tag VARCHAR(100) NOT NULL #作者标识符,唯一主键
PRIMARY KEY,
a_name VARCHAR(100) NULL, #作者名称
a_info TEXT NULL #作者信息
)
ENGINE = InnoDB;
types
CREATE TABLE types
(
t_type VARCHAR(100) NOT NULL #类型标识符,唯一主键
PRIMARY KEY,
t_name VARCHAR(100) NULL #类型的中文标志 ,like 计算机>>算法
)
ENGINE = InnoDB;comment
CREATE TABLE comment
(
c_id INT NOT NULL #评论id
PRIMARY KEY,
book_tag VARCHAR(100) NULL, #书籍标识符,books外键
c_name VARCHAR(100) NULL, #评论者id
c_time DATE NULL, #评论时间
c_level SMALLINT(6) NULL, #评论等级
c_mes VARCHAR(1000) NULL, #评论内容
CONSTRAINT FK_Relationship_3
FOREIGN KEY (book_tag) REFERENCES books (book_tag)
)
ENGINE = InnoDB;
CREATE INDEX FK_Relationship_3
ON comment (book_tag);二. 分析当当网结构

当当书籍二级类别
可以通过判断网页内是否有书籍子类别标签来找到最小类别标签。
当到达最小类别以后,通过网页源码来判断该类别有多少页,

翻到第二页时该页面的网址变为
http://category.dangdang.com/pg2-cp01.43.70.03.00.00.html
可以通过http://category.dangdang.com/pg{页码}-cp01.43.70.03.00.00.html来处理。
处理到最后一级类型页面后,就开始处理该类型下面书籍的信息,通过观察网页源码
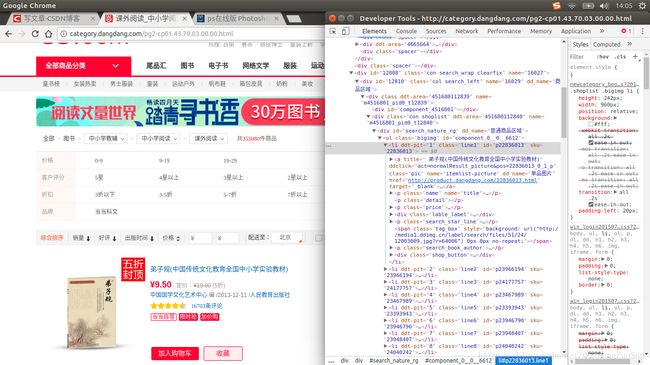
发现该页面的每一本书都在//div[@id=”search_nature_rg”]/ul/li标签包含,其中:
a[1]标签包含图片信息,
p[1]包含书籍名称和地址,
p[3]标签包含价格信息,
p[5]标签包含星级和评论相关内容,
p[6]标签包含书籍作者和出版社名称以及出版时间信息。
至于书籍的详细信息包括isbn编号和书籍作者介绍都在该书对应的详细信息网页中显示。

该书的isbn编号在信息信息页面的//ul[@class=”key clearfix”]/li中包含
通过分析网页机构,结合scrapy的爬取机机制可以写出下面的伪代码
GET dangdang.index
get all types
if types:
for type in types:
parse type_page >>request.meta
yield parse type.url
else:
parse min_type_page
get meta.type
for x in sum_page:
parse x
def index_page_parse
get info
yield book_page_parse
def book_page_parse
get info三. 创建Scrapy 工程,编写Item类
class BookDangdangItem(scrapy.Item):
def __repr__(self):
return "Book{0} link{1} isbn{2}".format(self.get('name'), self.get('link'), self.get('isbn', None))
# define the fields for your item here like:
# name = scrapy.Field()
author_tag = scrapy.Field()
type_tag = scrapy.Field()
name = scrapy.Field()
image_url=scrapy.Field()
publish_company = scrapy.Field()
time = scrapy.Field()
star_level = scrapy.Field()
price = scrapy.Field()
isbn = scrapy.Field()
brief = scrapy.Field()
info = scrapy.Field()
book_tag = scrapy.Field()
link = scrapy.Field()
#这里使用twisted异步操作数据库,由于从在主外键约束,使用了yield分三次提交数据库插入操作。
@property
def get_insert_sql(self):
t = time.time()
commit1 = """INSERT INTO `types` (`t_type`, `t_name`) SELECT MD5(%s), %s
FROM DUAL
WHERE NOT EXISTS ( SELECT * FROM types t WHERE t.t_type = MD5(%s))"""
commit2 = """INSERT INTO `Authors` (`a_tag`, `a_name`, `a_info`) SELECT MD5(%s), %s, %s
FROM DUAL
WHERE NOT EXISTS ( SELECT * FROM Authors a WHERE a.a_tag =MD5(%s))"""
commit3 = """INSERT INTO `books` (`book_tag`, `a_tag`, `t_type`, `b_name`, `publishing_company`, `time`, `star_level`, `price`, `isbn`, `brief`, `info`, `link`)
VALUES (MD5(%s), MD5(%s), MD5(%s), %s, %s, %s, %s, %s, %s, %s, %s, %s);"""
params1 = (self.get('type_tag', None), self.get('type_tag', None), self.get('type_tag', None))
params2 = (self.get('author_tag', t), self.get('author_tag', None), " ", self.get('author_tag', t))
params3 = (
self.get('book_tag'), self.get('author_tag', None), self.get('type_tag', None), self.get('name', None),
self.get('publish_company', None),
self.get('time', None), self.get('star_level', 0), self.get('price', 0), self.get('isbn',None),
self.get('brief', None), self.get('info', None), self.get('link', None))
yield commit1, params1
yield commit2, params2
yield commit3, params3编写spider类
class DangdangSpider(scrapy.Spider):
name = 'dangdang'
allowed_domains = ['dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.00.00.00.00.00.html']
dom = 'http://category.dangdang.com'
def start_requests(self):
return [scrapy.Request(url=self.start_urls[0], callback=self.parse, headers=DEFAULT_ERQUEST_HEADER)]
def parse(self, response):
try:
typestr = response.meta['type']
except(KeyError):
typestr = ""
types = response.xpath('//*[@id="navigation"]/ul/li[1]/div[2]/div[ 1]/div/span/a')
tyname = response.xpath('//*[@id="navigation"]/ul/li[1]').xpath('@dd_name').pop().extract()
if types and tyname == '分类': # 到分类终止递归
for type in types:
url = self.dom + type.xpath('@href').pop().extract()
typestr_new = typestr + "{0}>>".format(type.xpath('text()').pop().extract()) # 多级分类
scrapy.Spider.log(self, "Find url:{0},type{1}".format(url, typestr_new), logging.INFO)
yield scrapy.Request(url=url, callback=self.parse, meta={'type': typestr_new},
headers=DEFAULT_ERQUEST_HEADER)
else:
n_y = int(response.xpath('//*[@id="go_sort"]/div/div[2]/span[1]/text()').pop().extract()) # 当前页
c_y = int(response.xpath('//*[@id="go_sort"]/div/div[2]/span[2]/text()').pop().extract().lstrip('/')) # 总页数
for x in range(n_y, c_y): # 处理分页
yield scrapy.Request(url=self.dom + '/pg{0}-'.format(x) + response.url.split('/')[-1],
callback=self.parse_page, headers=DEFAULT_ERQUEST_HEADER,
meta={'type': typestr})
def parse_page(self, response):
for item in response.xpath('//*[@id="search_nature_rg"]/ul[@class="bigimg"]/li'):
# 所有图书
book = BookDangdangItem()
# try:
book['price'] = float(item.xpath('./p[@class="price"]/span[1]/text()').pop().extract().lstrip('¥'))
book['type_tag'] = response.meta['type']
book['name'] = item.xpath('./p[@class="name"]/a/text()').pop().extract().strip()
book['book_tag'] = str(time.time()) + book.get('name', None)
book['image_url'] = item.xpath('./a/img/@src').pop().extract()
book['link'] = item.xpath('./p[1]/a/@href').pop().extract()
book['star_level'] = \
int(item.xpath('./p[@class="search_star_line"]/span/span/@style').pop().extract().split(' ')[-1].rstrip(
'%;'))
try:
book['time'] = item.xpath('./p[@class="search_book_author"]/span[2]/text()').pop().extract().split('/')[
-1]
book['author_tag'] = ','.join(
item.xpath('./p[@class="search_book_author"]/span[1]/a/text()').extract()).strip()
book['publish_company'] = item.xpath(
'./p[@class="search_book_author"]/span[3]/a/text()').pop().extract().strip()
book['brief'] = item.xpath('./p[2]/text()').pop().extract().strip()
except:
scrapy.Spider.log(self, "Error:{} , url {}:".format(book['name'], response.url))
finally:
yield book
# yield scrapy.Request(callback=self.parse_book, cookies=self.cookir, headers=DEFAULT_ERQUEST_HEADER,
# meta={'item':book},url=book['link'])
def parse_book(self, response):
book = response.meta['item']
try:
book['isbn'] = int(
response.xpath('//ul[@class="key clearfix"]/li')[-2].xpath('text()').pop().extract().split(':')[-1])
except:
scrapy.Spider.log(self, "Book {0} Can't open.and url is:{1}".format(book['name'], book['link']),
logging.ERROR)
return
return book四. 编写ItemPipiLine实现Item数据插入数据库中
class BookDangdangPipeline(object):
def __init__(self, dpool):
self._dpool = dpool
#类方法,创建数据库实例
@classmethod
def from_settings(cls, setting):
db = dict(host=setting['MYSQL_HOST'], #从setting文件获取信息
port=setting['MYSQL_PORT'],
user=setting['MYSQL_USER'],
passwd=setting['MYSQL_PASSWD'],
db=setting['MYSQL_DBNAME'],
charset='utf8',
use_unicode=True,
cursorclass=cursors.DictCursor)
dpool = adbapi.ConnectionPool('pymysql', **db)
return cls(dpool)
def insert(self, cursor, item):
for insert_sql, params in item.get_insert_sql:
cursor.execute(insert_sql, params)
def process_item(self, item, spider):
self._dpool.runInteraction(self.insert, item)setting.py
# -*- coding: utf-8 -*-
#设置下载延迟
DOWNLOAD_DELAY = 0.2
#配置请求头文件
DEFAULT_ERQUEST_HEADER = {
"authority": " www.dangdang.com",
"method": "GET",
"path": "/",
"scheme": "http",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"accept-encoding": 'gzip, deflate, br',
"accept-language": 'en-US,en;q=0.9',
"referer": None,
"upgrade-insecure-requests": 1,
"User-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.22 \
Safari/537.36 SE 2.X MetaSr 1.0'
}
# Obey robots.txt rules
#关闭robots协议
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
#启用pipeline
ITEM_PIPELINES = {
'book_dangdang.pipelines.BookDangdangPipeline': 300,
}五. 开始爬取信息
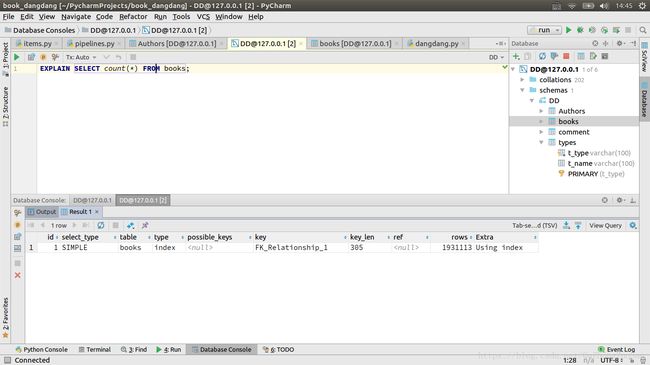
调试以后连续运行5小时,获取到190万条书籍信息,后由于内存占用过大导致程序运行缓慢强行停止。