分钟K线数据重构 ATR自适应通道 请高手来迭代
今天我们构建的量化模型,尝试用python搭建,首先它把数据拆分重构,使用15分钟或者更低颗粒度的K线,重构成为1小时线或者半日线。然后在重构的K线上,搭建ATR自适应通道交易模型。
如果说后半部分模型开发是很多软件都可以做的,前半部分就并非如此了。我们要以每天中午12点,下午15点为切分点,把每天的时间序列切分成3段。
让我们从最简单的模型本体交易逻辑开始讲。
一、模型本体——ATR自适应通道
很多做期货动量交易的人都明白,通道突破类策略是典型的趋势策略,这类策略指导构建的交易模型也比较简单清晰,并且将标准差等波动率表达方式考虑到模型中,有助于提升绩效。这里说的提升绩效,一方面是通过通道的中轨确定大致方向,另一方面是通过标准差等波动率指标,确认通道宽度。
首当其中的就是布林带,这个经典指标已经几十年被使用,基本上没人敢说这套系统不能用,但是它毕竟太过于古老,需要改进,这是共识。

典型的通道突破类策略是Aberration,实际上就是布林带,它被翻译理解为“失常、离开正路、越轨”等含义。该模型在均线上,构建了上下两个通道,通过波动率高低调节通道大小,如果价格突破上轨,就做多,如果价格突破下轨,就做空,价格回到中轨平仓,达到一定的自适应突破效果。
它的原理是这样:
// 中轨AverageMA,此处的Length是计算均线的窗口期
AverageMA = Average(Close1,Length);
// 价格序列的标准差
StdValue = StandardDev(Close1,Length);
// 上轨和下轨,此处的StdDev是标准差倍数
UpperBand = Avema StdDev StdValue;
LowerBand = Avema - StdDev StdValue;
今天的改进针对标准差部分,我们发现ATR比标准差更能够反应波动率的真伪,毕竟ATR采用的时间序列信息含量更高。
标准差是一个统计工具,不再叙述。ATR概念由威尔德(J. Welles Wilder)1978年于《New Concepts in Technical Trading Systems》书中提出,它取一定时间周期内的价格波动幅度的移动平均值,和你看到的网络上的注解不同,它并不是主要用于研判买卖时机,也不是做什么反趋势指标,它能感知到波动率。
海通证券测试了ATR和标准差的性能差异,这四种情况虽然特殊,但是以极端方式,体现了标准差和ATR的区别。
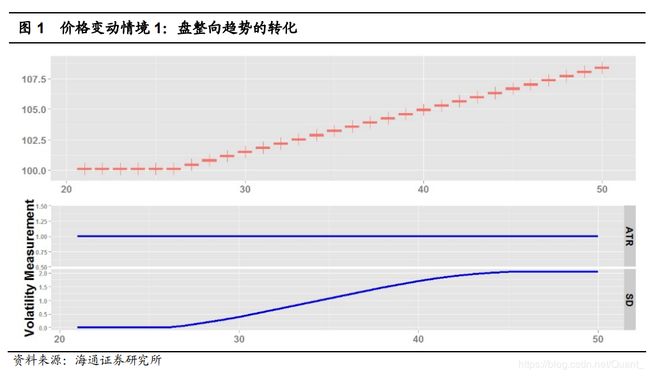
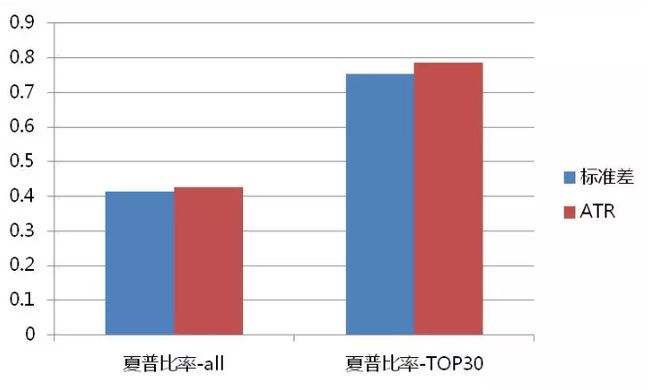
图1,标准差的表现力更强,因为价格确实出现了波动幅度变化。

图2,和研报观点相同,ATR可以稳定的保持着较高的水平,能对新的价格运行方向上的波动状态进行有效的刻画,但是标准差不行。
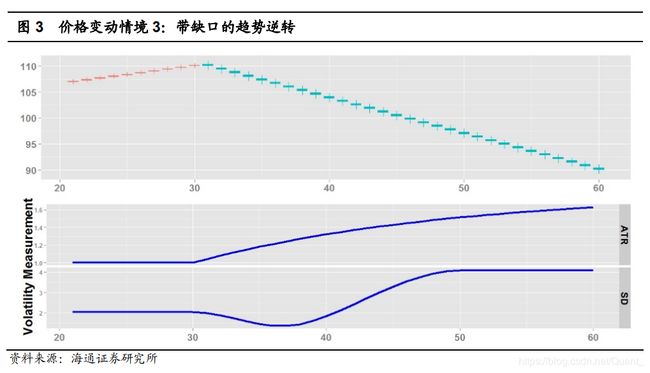
图3,标准差在适应新趋势时又一次表现出对趋势逆转时波动率提升的错误描述,它在新趋势刚开始出现时先缓慢下降,此时很容易造成通道类突破系统做出错误判断。
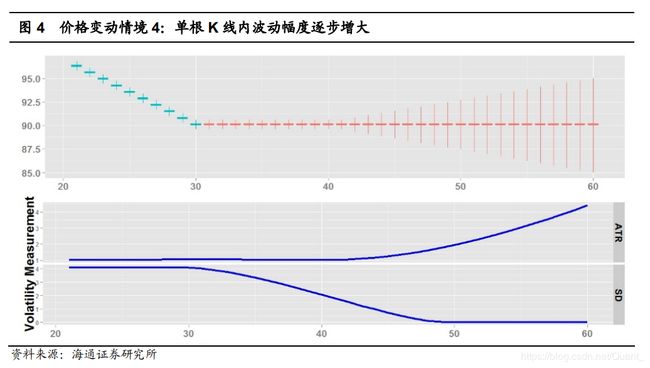
图4,很罕见的情况,但是ATR采用了最高最低价,而标准差没有,所以它对于波动率的分析显然错了。
所以,我们要使用ATR改进布林带了,改进完的这套系统,应该被称作肯特纳通道,网上会有很多资料,这里使用公众号《量化投资训练营》的结果,来体现两者的细微差距。
我们关闭掉模型中其他条件,仅以布林带或者说使用ATR为逻辑的Keltner Band作为开平仓条件进行测试。测试目标是螺纹钢RB000,2010年开始指数合约,沪深300指数2010年开始时间序列。频率都在1小时。
为了公平起见,参数统一为20周日ATR或者标准差。且为了得到均等的参数面绩效,我们令中轨周期参数Length在30~200之间波动,间隔5,。令Offset上下轨宽度参数在1~3之间波动,间隔0.5.。这样既可得到一个约180组绩效。
TOP组的意思是取按净利润排列,前30个绩效。ALL组的意思是所有绩效。
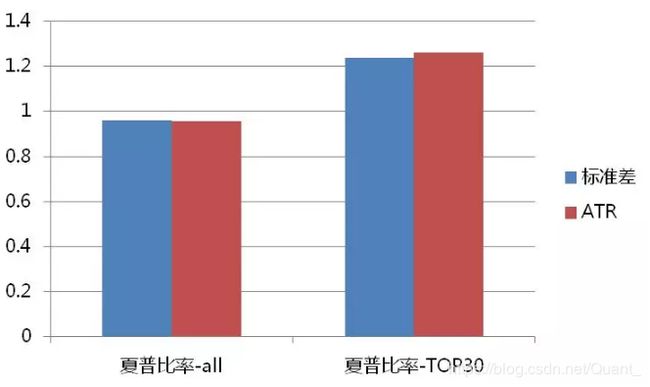
螺纹钢参数面测试结果
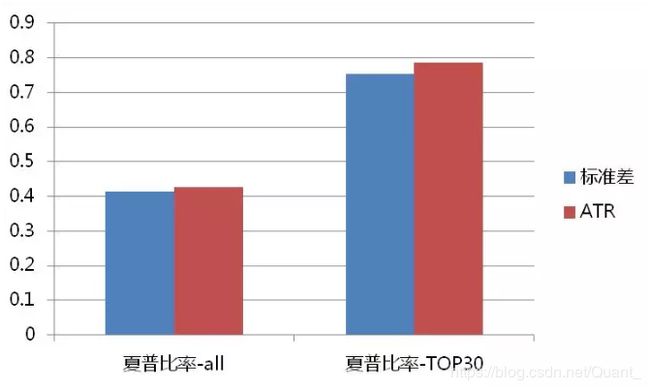
沪深300参数面测试结果
经过测试发现,商品期货上性能差异不够明显,但是到了股指方面,ATR的优势进一步显现。这其中最核心的因素恰巧是交易次数,带来的绩效IR提升,这里我们定义的IR和信息广度有关,我们认为信号数量是对于绩效可信度的考察方式。
ATR通道,在螺纹钢和沪深300指数上,信号数量是标准差的1.14倍和1.05倍,且同时绩效略好,所以导致这里定义的绩效IR = 绩效*SQRT(交易次数)差别更显著。
该部分逻辑,使用python语言撰写效果如下:
# ATR计算
g.low = g.AM[IndexFuture].exportArray('low')[-g.TodayBar[IndexFuture]*g.Window-1:]
g.high = g.AM[IndexFuture].exportArray('high')[-g.TodayBar[IndexFuture]*g.Window-1:]
g.close = g.AM[IndexFuture].exportArray('close')[-g.TodayBar[IndexFuture]*g.Window-1:]
# 为了防止ATR误算,如果出现大面积的空数据,则不计算ATR
if 0 in g.close:
pass
else:
g.ATR[IndexFuture] = talib.ATR(g.high,g.low,g.close, timeperiod = g.TodayBar[IndexFuture]*g.Window)[-1]
print(g.ATR[IndexFuture])
# 布林带计算
g.MidLine = g.close[-g.Window*g.TodayBar[IndexFuture]:].mean()
g.BollUp = g.MidLine g.offset*g.ATR[IndexFuture]
g.BollDown = g.MidLine - g.offset*g.ATR[IndexFuture]
# 交易信号计算
if g.close[-1] > g.BollUp:
g.Cross = 1
elif g.close[-1] < g.BollDown:
g.Cross = -1
else:
g.Cross = 0
#判断交易信号:布林带突破 可二次入场条件成立
if g.Cross == 1 and g.Reentry_long == False:
g.Signal = 1
elif g.Cross == -1 and g.Reentry_short == False:
g.Signal = -1
else:
g.Signal = 0
# 执行交易
Trade(context,RealFuture,IndexFuture)
# 运行防止充入模块
Dont_Re_entry(context,IndexFuture,ins)
# 计数器 1
g.Times[IndexFuture] = 1需要注意的是,我们肯定要在模型中放入止损逻辑,也肯定要放入止损后的防止重入逻辑,这两部分大家应该都熟悉了。
还有一个重点变量计算:TodayBar,它可以帮助我们获取每天的bar数量,以此来得到均线的参数,ATR的参数。
# 吊灯止损模块
def TrailingStop(context,RealFuture,IndexFuture):
# 仓位状态
long_positions = context.portfolio.long_positions
short_positions = context.portfolio.short_positions
# 多头进场后最高价 空头进场后最低价
g.HighPrice[IndexFuture] = max(g.HighPrice[IndexFuture],g.close[-1])
g.LowPrice[IndexFuture] = min(g.LowPrice[IndexFuture],g.close[-1])
if RealFuture in long_positions.keys():
if long_positions[RealFuture].total_amount > 0:
if g.HighPrice[IndexFuture]:
if g.close[-1] < g.HighPrice[IndexFuture] - g.NATRstop*g.ATR[IndexFuture]:
log.info('多头止损:\t' RealFuture)
order_target(RealFuture,0,side = 'long')
g.Reentry_long = True
if RealFuture in short_positions.keys():
if short_positions[RealFuture].total_amount > 0:
if g.LowPrice[IndexFuture]:
if g.close[-1] > g.LowPrice[IndexFuture] g.NATRstop*g.ATR[IndexFuture]:
log.info('空头止损:\t' RealFuture)
order_target(RealFuture,0,side = 'short')
g.Reentry_short = True还有就是移仓换月,我在比较早的帖子里已经写了它的逻辑,大家可以通过源码理解,其实不难,但是刚开始写确实有难度,好在以后聚宽会把这部分做成官方函数,各位就不用费心思写了。
二、数据重构——分钟线拼接为半日线
数据重构是量化交易中的重要工作,我觉得有这样几个原因:
1、大部分交易者在关键时间点上发单,会产生交易拥挤。 2、很多K线并不是我们想要的长度,因为其时间含金量不同。比如夜盘从21点到某些品种的凌晨2点半,交易清淡,但是依然占据等时间划分的K线并不科学。 3、除了改变时间颗粒度之外,还可以通过成交量、波动率等方法,重构K线,带来非常意外的超额收益。
这些功能,基本上是传统的期货软件不具备的,它们都需要使用更精密地编程语言完成,python就是这样一个工具,这里有它的价值,也是我们和身边很多朋友都要转移到python平台上开发交易策略的原因。
我们可以在【研究】平台打印出某品种的15分钟K线看看效果:
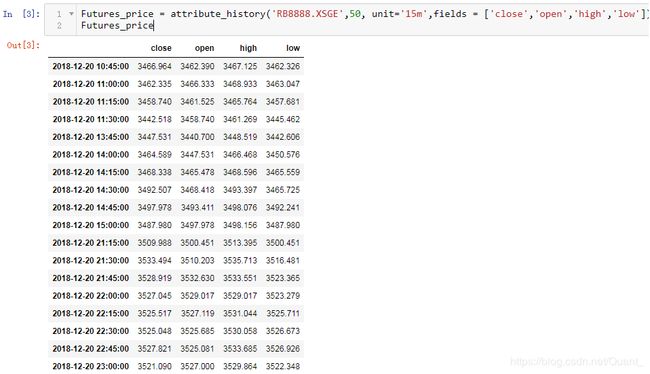
之后我们和聚宽技术客服沟通了解到:使用get_bars函数能够更好地获取到每天都是9点开始的数据,这样使用较大粒度的K线,如1小时线,也可以完成拼接,且效率更高。
这套模型中,我们首先在DataPrepare函数中,读取了15分钟K线,每次取50个样本进入之后要介绍的ArrayManager模块。
g.LastPrice[IndexFuture] = attribute_history(IndexFuture,50, unit='15m',fields = ['close','open','high','low'])然后构建了ArrayManager,该模块用于拼接K线的类,该策略基于不均匀的K线完成,在固定时间输出bar(日内,如早盘收盘时)。而当前平台未推出该功能,因而自定义ArrayManager类来实现,完整代码在模型中可看到。
class ArrayManager(object):
# 初始化函数,设定基准等等
def __init__(self, size=100):
# 设定Array的缓存大小
self.size = size
# 基本指标与基本指标的Array字典初始化(用于K线按收盘时间分割)
# 在这里VarArrays指的是全新K线的数据,以字典的形式存放,Vars是更新K线前的缓存
self.Vars = {'close':False,
'open':False,
'high':False,
'low':False}
self.VarsArrays = {'close':np.zeros(size),
'open':np.zeros(size),
'high':np.zeros(size),
'low':np.zeros(size)}
# 更新Array,形成新的bar数据,后续指标等都是基于该Array进行计算
def updateBarArray(self):
for var in self.VarsArrays.keys():
self.VarsArrays[var][0:self.size-1] = self.VarsArrays[var][1:self.size]
self.VarsArrays[var][-1] = self.Vars[var]在拼接数据前,我们做了一个小的识别,看数据是有有夜盘,有夜盘的品种我们可以定todaybar=3,没有夜盘的品种,我们定todaybar=2。该变量用于在模型里帮助计算参数。这部分逻辑放在before_market_open函数中。g.TodayBar[IndexFuture]作为全局变量在模型里传递。
# 以下逻辑判断该品种是否有夜盘,并计算TodayBar
g.Data[IndexFuture] = attribute_history(IndexFuture,120, unit='60m',fields = ['close'])
HourList = [x.strftime('%H') for x in g.Data[IndexFuture].index[:]]
if '21' in HourList:
g.TodayBar[IndexFuture] = 3
else:
g.TodayBar[IndexFuture] = 2然后就是在DataPrepare函数中,拼接数据:
# 如果当前时间在该品种实际交易时间内(基于15分钟bar),则执行拼接
if str(context.current_dt.time()) in [x.strftime('%H:%M:%S') for x in g.LastPrice[IndexFuture].index[:]]:
# 初始化
if IndexFuture not in g.AM.keys():
g.AM[IndexFuture] = ArrayManager()
g.AM[IndexFuture].updateBar(g.LastPrice[IndexFuture]['close'][-1],
g.LastPrice[IndexFuture]['high'][-1],
g.LastPrice[IndexFuture]['low'][-1],
g.LastPrice[IndexFuture]['open'][-1])
else:
# 收盘时间时输出新Bar
if g.LastPrice[IndexFuture].index[-1].strftime('%H%M') in g.CloseMarket :
# 没有夜盘的品种在9点15分不输出新Bar
if g.TodayBar[IndexFuture] == 2 and g.LastPrice[IndexFuture].index[-1].strftime('%H%M') == '0915':
pass
else:这部分的关键语句就是g.LastPrice[IndexFuture].index[-1].strftime('%H%M') in g.CloseMarket : 数据开始切分,g.CloseMarket被我们定义为['0915','1130','1500'],在这3个时间点上,模型通过updateBarArray产生新的拼接完毕后的K线。每次拼接完毕后,要执行数据删除clear函数。
updateBar函数用于更新数据,这里不用更新open数据,因为一个重构后的K线的open等于最初传入的open。close数据始终更新,因为要取到最后切分那一刻之前的close。最高和最低价,自然要寻找这段时间的最高最低点了,所以进行max和min比较方法。
模型中其他逻辑都比较简单易懂,所以搞懂此部分,基本上就能完成计算所需的数据支撑。下面我们进行参数组合测试,发现全过程表现较优质的参数。因为数据拼接涉及到IO量大,计算速度较慢,所以我建议从2014年测试,且如果你想要得到一个完整、可信度高的参数表现,要和之前测试动量模型一样,测试大约25个以上的品种。
三、绩效测试
今天的文章仅演示6个品种。多组资金曲线的回测,是通过【研究】调用【回测】得到的,具体过程在这里讲过:
【量化课堂】多回测运行和参数分析框架
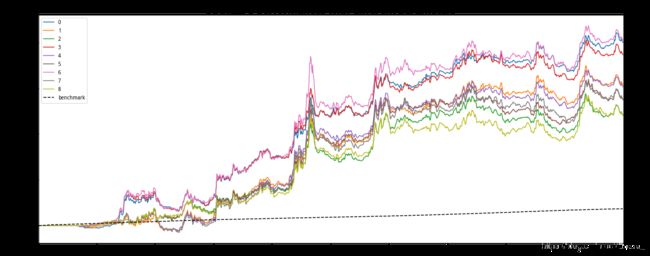
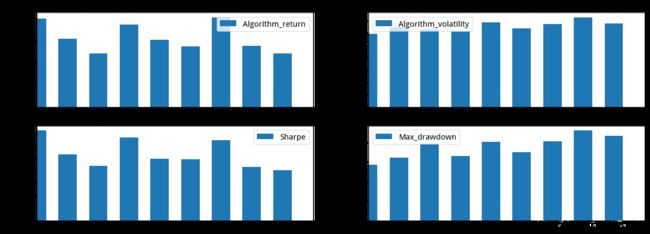
多组(参数)绩效如上图所示。

单组绩效如上图所示。
对于每个期货模型,因为很强的动量效应存在,结果都是比较理想的。但是其中也不免一些参数由于设置不合理,导致性能偏低。还是建议大家在品种数量更多的环境下,且最好能够分离训练集和测试集,找到合适的实盘参数。
我们将全部源码放在原文链接部分,需要的朋友们可以点击获取。