围棋号称人类最复杂的棋类运动,但近两年来,在AlphaGo的冲击下,已经溃不成军。继2016年AlphaGo以4:1击败韩国李世石,2017年AlphaGo Master以3:0零封柯洁之后,最新的Alpha Zero在没有棋谱的情况下,进行3天的自我训练后,就击败了AlphaGo;经过40天训练后,击败了Alpha Master。在AlphaGo背后隐藏的知识就是近来发展如火如荼的深度学习。深度学习不仅在围棋领域大放异彩,在图像识别、语音识别、自然语言处理等领域也全面开花。
1.人工智能、机器学习与深度学习
人工智能(Artificial Intelligence,简称AI),也称为机器智能,是指由人制造出来的机器所表现的智能。通常人工智能是指通过普通计算机程序的手段实现的人类智能技术。广义上的人工智能,是让机器拥有完全的甚至超越人类的智能(General AI或者Strong AI)。计算机科学中的研究更多聚焦在弱人工智能(Narrow AI或者Weak AI)上:人工智能是研究如何能让计算机模拟人类的智能,来实现特定的依赖人类智能才能实现的任务(如学习、语言、识别)。
最早的人工智能探索可以追溯到1818年Mary Shelly(雪莱)对于复制人体的想象。计算机科学家先驱Alan Turing(图灵)早在1950年就完整提出了计算机智能的概念,并且提出了如何评估计算机是否拥有智能的测试——图灵测试。尽管有争议,这项测试今天依然被很多研究人员当做测试人工智能的一项重要指标。人工智能这个名字的正式提出,来自于1956年的Darmouth会议。从20世纪50年代到90年代,人工智能在跌跌撞撞中前进,期间经历了两次人工智能寒冬。在2000年后,随着互联网的发展,人工智能领域拥有了期盼已久的大数据,也有了足够快的硬件处理能力的支持。2010年深度学习的出现,给人工智能领域带来了一场革命,大大加快了人工智能领域的研究。不过这个领域的发展才刚刚起步,人工智能的未知世界,可能比计算机科学的其他领域(比如硬件、安全、系统)的总和还要多。下图为人工智能之父——图灵。

人工智能的研究分为多种学派,例如符号主义学派和连接主义学派等。每种学派所用的方法完全不同,甚至尝试解决的问题也不一样。符号主义源自于数学逻辑,目前依然是主流学派之一(例如知识图谱)。机器学习则是连接主义的产物,机器学习中最早的模型是源自于人脑的仿生学,感知机(Perceptron)就是对人脑单一神经元的模拟。基于统计学的方法,例如决策树、支持向量机、逻辑回归等也被归于此类算法当中。从广义上讲,机器学习是从数据中自动学习算法,并且使用学习到的算法去进行预测。机器学习所学习到的算法,是自动从数据中学习的,随着数据改变也会有本质上的改变。这与传统计算机科学中面向对数据提前编程有着本质区别。
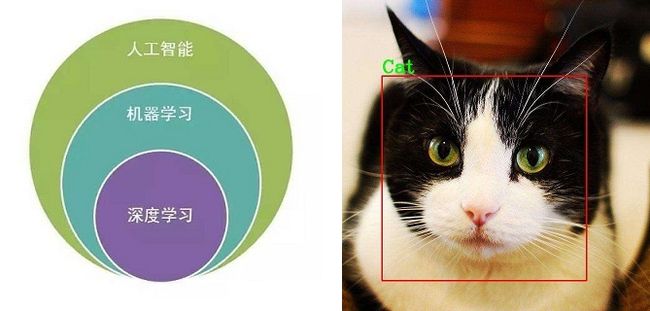
深度学习是使用深度神经网络来实现机器学习的方法。从下面左图中我们可以看到人工智能、机器学习和深度学习这三者的关系。深度神经网络跟人脑的模型有相似性,人脑中每个神经元都是可以连接的,而深度神经网络中,神经元往往被分为了很多层,从而有了深度。拿图像识别来举例(如下面右图:猫咪识别是深度神经网络最早的成功案例之一),图像可以被剪裁成很多小块,然后输入到神经网络的第一层,接着第一层再向后面的层传导,每层做不同的任务,然后最后一层完成预测。每个神经元对于输入都有权重,这些权重被用来计算最后的输出。例如图像识别的例子,有些神经元被用来识别颜色,有些神经元被用来识别形状,最后一层的神经元对所有权重进行总结,最终做出预测。
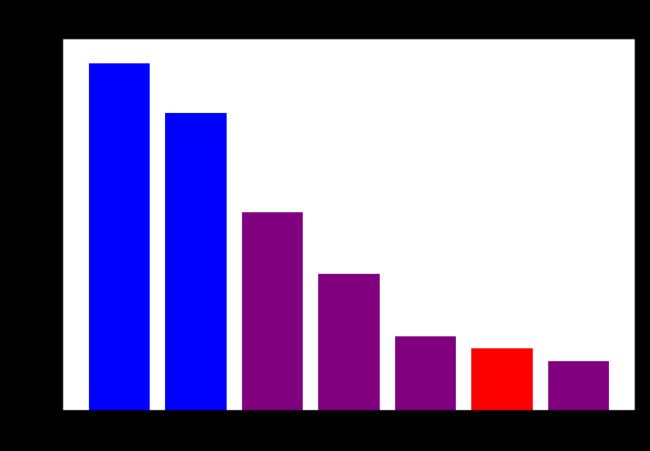
深度学习在所有人工智能领域当中都取得了成功。以ImageNet图像分类任务举例,深度学习自2012年以来就已经远远超过了传统的机器学习算法,在2014之后甚至超过了人类的正确率。
ImageNet 项目是一个用于物体对象识别检索大型视觉数据库。截止2016年,ImageNet 已经对超过一千万个图像进行手动注释,标记图像的类别。在至少一百万张图像中还提供了边界框。自2010年以来,ImageNet 举办一年一度的软件竞赛,叫做(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)。主要内容是通过算法程序实现正确分类和探测识别物体与场景,评价标准就是Top-5 错误率。Top-5错误率即对一个图片,如果概率前五中包含正确答案,即认为正确。Top-1错误率即对一个图片,如果概率最大的是正确答案,才认为正确。如下图所示,蓝色为非深度学习的成绩,紫色为深度学习的成绩,红色为人类的成绩。
为什么深度学习能够获得成功呢?主要是由于以下三个因素的影响。
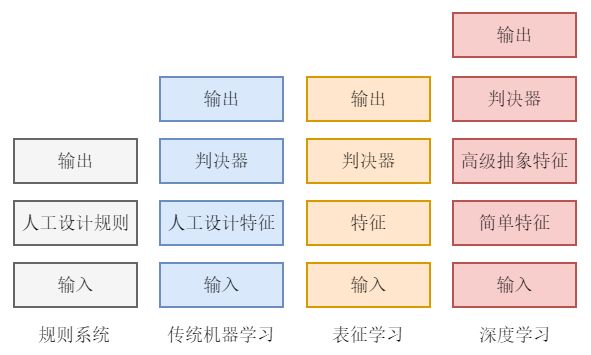
第一个因素是深度神经网络增加了学习能力。例如,传统的规则系统100%依赖于人工规则,而机器学习模型往往要依赖于少量人工设计的特征,深度学习模型则几乎不依赖任何人工定义的特征和规则,如下图所示。
另外两个因素是深度神经网络以外的因素,也不可忽视。一个因素是由于互联网时代的积累,我们有了更多的数据来训练模型。另一个因素是计算机硬件的飞速发展,特别是GPU的出现,让深度学习所需要的高带宽的超大规模计算变成了可能。以图像识别任务进行对比,2012年和1998年相比,神经网络的复杂程度增加了几十倍,训练数据的数量有了千万倍的飞跃,同时所用的计算能力也增加了千倍。
2.深度学习工具介绍
目前主要的深度学习框架有PyTorch、TensorFlow、Caffe/Caffe2、MXNet、Theano、Keras、CNTK、PaddlePaddle(百度)等。这些框架广泛地应用于计算机视觉、语音识别、自然语言处理、医疗诊断、生物信息学等领域。下面简要介绍当前深度学习领域影响较大的几个框架。
1.Theano
Theano是加拿大蒙特利尔大学LISA实验室在2008年提出的深度学习框架,是一个Python库,可用于定义、优化和计算数学表达式,特别是多维数组。Theano结合了计算机代数系统和优化编译器,能够为多种数学运算符生成定制的C语言代码,同时它还支持GPU加速,为早期的深度学习研究立下了汗马功劳。Theano在深度学习框架中是祖师级的存在,但它诞生于研究机构,学术气息浓厚,工程设计存在缺陷。在2017年9月,在Theano 10.0发布之际,LISA实验室负责人,深度学习三巨头之一的Yoshua Bengio宣布Theano停止开发。尽管Theano已经完成了使命,但它为深度学习的早期研究提供了极大地帮助,同时也为后来的深度学习框架奠定了方向:以计算图为框架的核心,采用GPU加速计算。
2.TensorFlow
2015年11月,Google推出了机器学习开源工具TensorFlow。TensorFlow是由Google Brain团队开发的,主要用于机器学习和深度神经网络研究。同时,它也是一个基础系统,能够应用于其他领域。TensorFlow使用C++作为开发语言,使用计算流图的形式进行计算。图中节点表示数学运算,而图中的线条表示Tensor之间的交互。TensorFlow对开发不是很友好,但是方便部署,不仅可以在CPU和GPU上运行,还可以在台式机、服务器、移动设备上运行。
在Google的强大号召力下,加上支持各种语言和硬件,TensorFlow是目前流行的深度学习框架,在工业上应用广泛,有强大的开发者社区。但是TensorFlow的系统设计过于复杂,对于初学者来讲,学习曲线优点陡峭。同时,TensorFlow作为静态图框架,不太方便直接调试,打印中间结果必须借助Session运行才能生效,或者学习额外的tfgdb工具。
3.Caffe/Caffe2
Caffe的全称是Convolutional Architecture for Fast Feature Embedding,是加州大学伯克利分校的贾扬清开发的,目前由伯克利视觉中心维护。这是一个清晰、高效的深度学习框架,核心语言是C++,支持命令行、Python和MATLAB接口,在CPU和GPU均可运行。Caffe2沿袭了大量的Caffe设计,并解决了Caffe在使用和部署上发现的问题。Caffe2能够提供速度和便携性,其Python库和C++ API使用户在Linux、Windows、iOS、Android,甚至Raspberry和Nvidia Tegra上进行原型设计、训练和部署。由于Caffe2对全平台的支持,适合工业部署。
4.MXNet
MXNet是由李沐和陈天奇等人开发的深度学习框架。2016年,成为亚马逊云计算的官方深度学习平台。MXNet支持C++、Python、R、Scala、Julia、MATLAB以及JavaScript等语言;支持命令行和符号编程;可以运行在CPU、GPU、集群、服务器、台式机和移动设备。MXNet分布式性能强大,对显存、内存优化明显。为了完善MXNet生态圈,MXNet推出了PyTorch设计的Gluon,未来Gluon还将支持微软的GNTK。
5.CNTK
2016年1月,微软开源了自身的深度学习开发框架——认知工具集GNTK(Cognitive Toolkit)。GNTK是由微软研究院基于C++开发的工具包。GNTK最初为微软内部为黄学东进行语音识别等任务进行开发的。根据微软官方的介绍,GNTK是一个统一的计算网络框架,将深度神经网络描述为一系列通过有向图的计算步骤。在有向图中,每个节点代表一个输入值或者一个网络参数,每条边表示在其中的一个矩阵运算。GNTK提供了实现前向计算和梯度计算的算法。GNTK支持CPU、GPU模式。GNTK文档比较缺乏,推广不是很有力,导致现在的使用者较少,但GNTK在语音识别领域的效果比较显著。
6.Keras
Keras是一个高级神经网络API,有纯Python编写并使用TensorFlow、Theano及GNTK作为后端。从严格意义上讲,Keras并不能称为一个深度学习框架,而是一个深度学习接口,调用其他深度学习框架。学习Keras十分容易,以类似Python的方式进行编码,但是使用Keras相当于调用接口,很难真正学习到深度学习的知识。同时,由于Keras支持各个框架,为了提供一致的接口,Keras做了层层封装,导致用户获取底层的数据信息困难,有了Bug,也不好调试处理。
3.PyTorch介绍
PyTorch是一个年轻的框架。2017年1月28日,PyTorch 0.1版本正式发布,这是Facebook公司在机器学习和科学计算工具Torch的基础上,针对Python语言发布的全新的深度学习工具包。PyTorch类似Numpy,并且支持GPU,有着更高级而又易用的功能,可以用来快捷地构建和训练深度神经网络。一经发布,它便受到机器学习和深度学习者重要的研究和开发工具之一。
2017年7月,Facebook和微软宣布,推出开放的Open Neural Network Exchange(ONNX,开放神经网络交换)格式,ONNX为深度学习模型提供了一种开源格式,模型可以在不同深度学习框架下进行转换。亚马逊的AWS接着加入进来。2017年10月,Intel、Nvidia、AMD、IBM、Qualcomm、ARM、联发科和华为等厂商纷纷加入ONNX阵营,ONNX生态圈正式形成。ONNX生态系除了原本支持的开源软件框架Caffe2、PyTorch和CNTK,也包含了MXNet和TensorFlow。PyTorch是一套以研究为核心的框架,但是用PyTorch开发的算法模型可以通过ONNX转换,可用于其他主流深度学习框架。
2017年8月,PyTorch 0.2版本发布,增加分布式训练、高阶导数、自动广播法则等众多特性。
2017年12月,PyTorch 0.3版本发布,性能改善,对计算速度进行优化,同时一个重大的更新是模型转换没支持DLPack、支持ONNX格式,可以把PyTorch模型转换到Caffe2、Core ML、CNTK。MXNet、TensorFlow中。
2018年4月25日,PyTorch官方在GitHub上发布了0.4版本,新版本做了非常多的改进,其中最重要的改进是官方支持Windows系统。
2018年10月3日,首届PyTorch开发者大会上,Facebook正式发布PyTorch 1.0预览版。PyTorch 1.0框架主要迎来了三大更新;第一,添加了一个新的混合前端,支持从Eager模式到图形模型的跟踪和脚本模型,以弥合研究和生产部署之间的差距;第二,增加了经过改进的torch.distributed库,使得开发者可以在Python和C++环境中实现更快的训练;第三,增加了针对关键性能研究的Eager模型C++接口。在PyTorch 1.0版本中,Facebook将现有PyTorch框架的灵活性与Caffe2(2018年5月宣布Caffe2并入PyTorch)的生产力结合,提供从研究到AI研究产品化的无缝对接。
可以看到PyTorch更新频率是很快的,可见Facebook对其支持力度。开源社区和机器学习从业者也对PyTorch响应热烈。
面对众多的深度学习框架,为什么要选择PyTorch呢?PyTorch有哪些鲜明的特点?
(1)PyTorch使用Python作为开发语言,使得开发者能接入广大的Python生态圈的库和软件。同时,在PyTorch开发中,数据处理类型类似数据计算包Numpy的矩阵类型,代码风格类似机器学习包Scikit-Learn,方便广大的机器学习者进入深度学习这个新的领域。
(2)目前大多数开源框架(比如TensorFlow、Caffe、CNTK、Theano等)采用静态计算图,而PyTorch采用动态计算图。静态计算图要求对网络模型先定义再运行,一次定义多次运行。动态计算图可以在运行过程中定义,运行的时候构建,可以多次构建多次运行。静态图的实现代码冗长,不直观。动态图的实现简洁优雅,直观明了。动态计算图的另一个显著优点是调试方便,可以随时查看变量的值。由于模型可能会比较复杂,如果能直观地看到变量的值,就能够快速构建好模型。
(3)PyTorch的API设计简洁优雅,方便易用。PyTorch的API设计思想来源于Torch,Torch的API设计以灵活易用而闻名,Keras作者就是受Torch的启发而开发了Keras。PyTorch有种使用Keras的快感,就是来源于此。相比而言,TensorFlow就臃肿难用多了。
(4)PyTorch支持ONNX格式,补齐了最后一块短板——生产环境的部署。生产环境有移动设备、嵌入式设备和云端设备。原本因PyTorch过于灵活,不太合适部署生产环境和大规模部署,但将深度学习部署到生产环境变得越来越重要,ONNX的横空出世解决了这一难题。可以用PyTorch做研究,然后用ONNX转换为Caffe2部署到生产环境。值得一提的是,Caffe2也是Facebook开发的,是Caffe的最新版本。
PyTorch开发语言简洁优雅,方便快速构建模型,同时调试的功能便于发现和改进错误。可以说,PyTorch是入手深度学习的最佳利器。使用PyTorch的公司和研究机构如雨后春笋版涌现,数不胜数。