iOS - 线程中常见的几种锁
线程锁主要是用来解决“共享资源”的问题,实际开发中或多或少的都会用到各类线程锁,为了线程的安全我们有必要了解常见的几种锁,下面是本人查看一些大牛的博客然后整理的内容,加上自己的一些见解,水平有限,如果不慎有误,欢迎交流指正。
常见锁列举
- 自旋锁(
OSSPinLock、os_unfair_lock) - 互斥锁(
pthread_mutex_t、NSLock、@synthronized) - 递归锁(
pthread_mutex_t、NSRecursiveLock) - 条件锁(
pthread_cond_t、NSCondition、NSConditionLock) - 信号量(
dispatch_semaphore_t、pthread_mutex_t等) - 读写锁(
pthread_rwlock_t) - 栅栏(
dispatch_barrier_sync、dispatch_barrier_async) - atomic
一、自旋锁
自旋锁的意思就是当资源被占有时,自旋锁不会引起其他调用者休眠,而是让其他调用者自旋,不停的循环访问自旋锁导致调用者处于busy-wait(忙等状态),直到自旋锁的保持者释放锁。自旋锁是为了实现保护共享资源一种锁机制,在任何时刻只能有一个保持者,也就是说在任何时刻只能有一个可执行单元获得锁。也正是因为其他调用者会保持自旋状态,使得在锁的保持者释放锁时能够即刻获得锁,效率非常高。但我们说调用者时刻自旋也是消耗CPU资源的,所以如果自旋锁的使用者保持锁的时间比较短的话,使用自旋锁是非常合适的,因为在锁释放之后省去了唤醒调用者的时间。
在iOS10之前,苹果使用自旋锁是OSSPinLock:
// 头文件
// #import 但是YYKit的作者 ibireme 在《不再安全的 OSSpinLock》一文中指出OSSpinLock存在潜在的优先级反转问题,意思就是如果一个低优先级的线程获得锁并访问共享资源,这时一个高优先级的线程也尝试获得这个锁,它会处于 spin lock 的忙等状态从而占用大量 CPU。此时低优先级线程无法与高优先级线程争夺 CPU 时间,从而导致任务迟迟完不成、无法释放 lock。
如果开发者能够保证访问锁的线程全部都处于同一优先级,OSSpinLock也是可用的。
所以在 iOS 10/macOS 10.12 发布时,苹果提供了新的 os_unfair_lock 作为 OSSpinLock 的替代,并且将 OSSpinLock 标记为了 Deprecated。使用 os_unfair_lock :
// 头文件
// #import 二、互斥锁
互斥锁和自旋锁类似,都是为了解决对某项资源的互斥使用,并且在任意时刻最多只能有一个执行单元获得锁,与自旋锁不同的是,互斥锁在被持有的状态下,其他资源申请者只能进入休眠状态,当锁被释放后,CPU会唤醒资源申请者,然后获得锁并访问资源。
常见的互斥锁常见有pthread_mutex_t、NSLock、@synthronized三种:
1、 @synthronized
该@synchronized指令是在Objective-C代码中动态创建互斥锁的便捷方法,和其他互斥锁不同的是我们不必直接创建互斥锁定对象,直接通过@synchronized指令来完成:
- (void)myMethod:(id)anObj
{
@synchronized(anObj)
{
//大括号之间的所有内容均受@synchronized指令保护。
}
}
虽然看起来很简洁,但是@synchronized是以牺牲性能来换取语法上的简洁和可读性的。官方文档指出在内部隐式地将异常处理程序添加到受保护的代码中,如果抛出异常,此处理程序将自动释放互斥量。这意味着,当我们使用@synchronized指令时,还免费的得到异常处理的功能,但这也造成了额外的开销。如果不介意由隐式异常处理程序引起的额外开销的话,可以考虑使用该锁,否则就使用其他锁类。
具体的实现原理可以参考这篇文章: 关于 @synchronized,这儿比你想知道的还要多。
2、 NSLock
NSLock是Object-C以对象的形式暴露给开发者的一种锁,并遵守NSLocking协议,实现起来很简单:
- (void)mutexLockTest {
NSLock *lock = [[NSLock alloc] init];
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[lock lock];
NSLog(@"---thread1");
sleep(3);
[lock unlock];
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[lock lock];;
NSLog(@"---thread2");
sleep(3);
[lock unlock];
});
}
输出:
LockTest[60255:2555431] ---thread1
LockTest[60255:2555429] ---thread2
上例中的lock和unlock都是协议NSLocking中的方法,NSLock类中还有两个方法:
- (BOOL)tryLock;
- (BOOL)lockBeforeDate:(NSDate *)limit;
我们知道lock方法是会阻塞线程的,而tryLock方法不会阻塞线程,如果返回YES则加锁成功,否则返回NO,加锁失败。方法lockBeforeDate:意思是一段时间之内都会尝试加锁并阻塞线程,如果这段时间能加锁成功则返回YES,否则返回NO。
注意:lock–unlock 、tryLuck—unLock 必须成对存在,不能迭代(或递归)加锁,如果发生两次lock,而未unlock过,则会产生死锁问题。
3、 pthread_mutex_t
pthread_mutex_t是纯C语言的函数,效率更高,先来看下几个函数:
// 初始化互斥锁函数
int pthread_mutex_init(pthread_mutex_t * __restrict,
const pthread_mutexattr_t * _Nullable __restrict);
// 加锁函数
int pthread_mutex_lock(pthread_mutex_t *);
// 解锁函数
int pthread_mutex_unlock(pthread_mutex_t *);
// 互斥锁属性初始化函数
int pthread_mutexattr_init(pthread_mutexattr_t *);
/**
* 互斥锁属性设置函数
*
* 锁类型:
* PTHREAD_MUTEX_NORMAL 0 普通互斥锁
* PTHREAD_MUTEX_ERRORCHECK 1 带有错误检查互斥锁
* PTHREAD_MUTEX_RECURSIVE 2 递归锁
*/
int pthread_mutexattr_settype(pthread_mutexattr_t *, int);
具体使用,创建一个简单的互斥锁:
- (void)mutexLockTest {
// 初始化互斥锁
__block pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
// 或者
// __block pthread_mutex_t mutex;
// pthread_mutex_init(&mutex, NULL);
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
pthread_mutex_lock(&mutex);
sleep(2);
NSLog(@"----- thread1 %@",[NSThread currentThread]);
pthread_mutex_unlock(&mutex);
});
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
pthread_mutex_lock(&mutex);
sleep(2);
NSLog(@"----- thread2 %@",[NSThread currentThread]);
pthread_mutex_unlock(&mutex);
});
}
输出结果:
LockTest[65150:2630192] ----- thread1 <NSThread: 0x600002b25700>{number = 8, name = (null)}
LockTest[65150:2630190] ----- thread2 <NSThread: 0x600002bf0280>{number = 4, name = (null)}
对于NSLock就是在内部封装一个pthread_mutex,属性为 PTHREAD_MUTEX_ERRORCHECK,它会损失一定性能换来错误提示。
这三种互斥锁的性能比较: pthread_mutex > NSLock > @synchronized
三、递归锁
递归锁可以被同一线程多次请求,而不会引起死锁,即在多次被同一个线程进行加锁时,不会造成死锁。这主要是用在循环或递归操作中。
1、NSRecursiveLock
NSRecursiveLock也是Object-C为我们提供锁类,其遵守NSLocking协议,递归锁也是通过 pthread_mutex_lock 函数来实现,在函数内部会判断锁的类型,如果显示是递归锁,就允许递归调用,仅仅将一个计数器加一,等到递归完毕之后,所有锁都会释放。举例:
- (void)recursiveLock {
NSRecursiveLock *recursiveLock = [[NSRecursiveLock alloc] init];
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
static void (^RecursiveBlock)(int);
RecursiveBlock = ^(int value) {
[recursiveLock lock];
// 这里要设置递归结束的条件或次数,不然会无限递归下去
if (value > 0) {
NSLog(@"处理中...");
sleep(1);
RecursiveBlock(--value);
}
NSLog(@"处理完成!");
[recursiveLock unlock];
};
RecursiveBlock(4);
});
}
2、pthread_mutex_t
NSRecursiveLock 与 NSLock 的区别在于内部封装的 pthread_mutex_t 的类型不同,前者的类型为 PTHREAD_MUTEX_RECURSIVE,举例:
- (void)recursiveLock {
__block pthread_mutex_t recursiveMutex;
pthread_mutexattr_t recursiveMutexattr;
pthread_mutexattr_init(&recursiveMutexattr);
pthread_mutexattr_settype(&recursiveMutexattr, PTHREAD_MUTEX_RECURSIVE);
pthread_mutex_init(&recursiveMutex, &recursiveMutexattr);
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
static void (^RecursiveBlock)(int);
RecursiveBlock = ^(int value) {
pthread_mutex_lock(&recursiveMutex);
// 这里要设置递归结束的条件或次数,不然会无限递归下去
if (value > 0) {
NSLog(@"处理中...");
sleep(1);
RecursiveBlock(--value);
}
NSLog(@"处理完成!");
pthread_mutex_unlock(&recursiveMutex);
};
RecursiveBlock(4);
});
}
四、条件锁
条件是信号量的另一种类型,当某个条件为true时,它允许线程相互发信号。条件通常用于指示资源的可用性或确保任务以特定顺序执行。当线程测试条件时,除非该条件已经为真,否则它将阻塞。它保持阻塞状态,直到其他线程显式更改并发出条件信号为止。条件和互斥锁之间的区别在于,可以允许多个线程同时访问该条件。
1、NSCondition
NSCondition 的底层是通过条件变量(condition variable) pthread_cond_t 来实现的。条件变量有点像信号量,提供了线程阻塞与信号机制,因此可以用来阻塞某个线程,并等待某个数据就绪,随后唤醒线程,比如常见的生产者-消费者模式。具体举例:
- (void)conditionLock {
NSCondition *conditionLock = [[NSCondition alloc] init];
__block NSString *food;
// 消费者1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[conditionLock lock];
if (!food) {// 没有现成的菜(判断是否满足线程阻塞条件)
NSLog(@"等待上菜");
[conditionLock wait];// 没有菜,等着吧!(满足条件,阻塞线程)
}
// 菜做好了,可以用餐!(线程畅通,继续执行)
NSLog(@"开始用餐:%@",food);
[conditionLock unlock];
});
// 消费者2
// dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
// [conditionLock lock];
// if (!food) {
// NSLog(@"等待上菜2");
// [conditionLock wait];
// }
// NSLog(@"开始用餐2:%@",food);
// [conditionLock unlock];
// });
// 生产者
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[conditionLock lock];
NSLog(@"厨师做菜中...");
sleep(5);
food = @"四菜一汤";
NSLog(@"厨师做好了菜:%@",food);
[conditionLock signal];
// [conditionLock broadcast];
[conditionLock unlock];
});
}
上面的例子可以看到,不仅用到了条件锁(signal、wait),还用到了互斥锁(lock、unlock),也就说条件锁是配合互斥锁一起使用的,这也是出于线程的安全考虑,防止其他线程修改数据,保证消费者拿到的是正确的数据。
在NSCondition中还有一个方法:
- (void)broadcast;
broadcast方法是以广播的形式通知所有满足条件且等待中的线程可以继续执行任务了,如上例中把注释的部分代码解开,会有两份输出结果。
2、NSConditionLock
NSConditionLock也给一种条件锁,具体例子:
- (void)conditionLock {
NSConditionLock *conditionLock = [[NSConditionLock alloc] init];
NSMutableArray *arrayM = [NSMutableArray array];
NSInteger condition = 4;// 条件
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
[conditionLock lock];
for (int i = 0; i < 6; i++) {
sleep(1);
[arrayM addObject:@(i)];
NSLog(@"异步下载第 %d 张图片",i);
if (arrayM.count == 4) {// 当下载四张图片就回到主线程刷新
[conditionLock unlockWithCondition:condition];
}
}
});
dispatch_async(dispatch_get_main_queue(), ^{
[conditionLock lockWhenCondition:condition];
NSLog(@"已经下载4张图片%@",arrayM);
[conditionLock unlock];
});
}
NSConditionLock和NSCondition有点相似,都是当条件满足时,唤醒另外一线程然后执行任务,只不过前者直接将条件作为了函数的参数。
3、pthread_cond_t
- (void)conditionLock3 {
__block pthread_mutex_t mutex;
__block pthread_cond_t condition;
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&condition, NULL);
NSMutableArray *arrayM = [NSMutableArray array];
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
pthread_mutex_lock(&mutex);
for (int i = 0; i < 6; i++) {
sleep(1);
[arrayM addObject:@(i)];
NSLog(@"异步下载第 %d 张图片",i);
if (arrayM.count == 4) {
//pthread_cond_broadcast(&condition);
pthread_cond_signal(&condition);
}
}
});
dispatch_async(dispatch_get_main_queue(), ^{
pthread_cond_wait(&condition, &mutex);
NSLog(@"已经获取到4张图片");
pthread_mutex_unlock(&mutex);
});
}
上例中的pthread_cond_wait和pthread_cond_signal两个函数的本质是锁的转移,以生产者-消费者模式来说, pthread_cond_wait 方法是消费者放弃锁,然后生产者获得锁,pthread_cond_signal 则是一个锁从生产者到消费者转移的过程。
三种锁的性能比较:pthread_mutex > NSCondition > NSConditionLock
五、信号量
信号量(Semaphore),有时被称为信号灯,是在多线程环境下使用的一种设施,是可以用来保证两个或多个关键代码段不被并发调用。在进入一个关键代码段之前,线程必须获取一个信号量;一旦该关键代码段完成了,那么该线程必须释放信号量。其它想进入该关键代码段的线程必须等待直到第一个线程释放信号量。为了完成这个过程,需要创建一个信号量VI,然后将Acquire Semaphore VI以及Release Semaphore VI分别放置在每个关键代码段的首末端。确认这些信号量VI引用的是初始创建的信号。
使用信号量采用GCD中的dispatch_semaphore_t对象,实际开发中通常用于控制最大并发量、控制资源的同步访问、网络同步加载等,函数介绍:
// 创建信号量,并给信号量初始化值
dispatch_semaphore_t dispatch_semaphore_create(long value);
// 信号量减1,当信号量小于0时阻塞线程
long dispatch_semaphore_wait(dispatch_semaphore_t dsema, dispatch_time_t timeout);
// 信号量加1
long dispatch_semaphore_signal(dispatch_semaphore_t dsema);
当我们需要控制两个或多个网络同步执行的时候,该如何做?我们会有多种方案(dispatch_async、锁等),这里我们使用信号量来实现:
// 创建信号量并初始化信号量的值为0
dispatch_semaphore_t semaphone = dispatch_semaphore_create(0);
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{ // 线程1
sleep(2);
NSLog(@"async1.... %@",[NSThread currentThread]);
dispatch_semaphore_signal(semaphone);//信号量+1
});
dispatch_semaphore_wait(semaphone, DISPATCH_TIME_FOREVER);//信号量减1
dispatch_async(dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0), ^{
// 线程2
sleep(2);
NSLog(@"async2.... %@",[NSThread currentThread]);
dispatch_semaphore_signal(semaphone);//信号量+1
});
输出:
LockTest[26691:3553853] async1.... <NSThread: 0x60000379c300>{number = 3, name = (null)}
LockTest[26691:3553853] async2.... <NSThread: 0x60000379c300>{number = 3, name = (null)}
分析:上例代码在主线程中执行,信号量初始化为0,执行到线程1时,因为是异步函数,所以会开辟分线程,然后会立即返回函数随后才会执行block中的任务,这时主线程中执行到dispatch_semaphore_wait函数(下文简称wait),信号量减1,变为-1,这时主线程会阻塞,导致线程2无法执行。当线程1中的执行完dispatch_semaphore_signal(下文简称signal)函数之后,信号量加1,变为0,这时主线程会解除阻塞状态,然后执行线程2中的任务。由此达到两个网络同步执行请求,如果是多个网络请求同步执行也是依次类推。
上面说到阻塞主线程的状况,如果我们把线程1中的任务执行完之后回到主线程调用signal函数,结局会怎样呢?
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"回到主线程");
dispatch_semaphore_signal(semaphone);//信号量+1
});
输出:
LockTest[27663:3570710] async1.... <NSThread: 0x6000020f4a00>{number = 5, name = (null)}
分析:根据上面的结果可以看出,线程1任务执行完成,而线程2却一直没有执行,什么原因?因为主线程死锁,当主线程执行到wait函数时,信号量减1,变为-1,阻塞主线程,然后线程1中的任务执行完毕,想要回到主线程调用signal函数,但是主线程已经处于阻塞状态了,导致根部不会执行到signal函数,导致主线程死锁。
再举个例子,当我们需要下载100张图片时,因为网络下载属于耗时操作,所以我们会使用并发队列(concurrent queue)和异步函数(dispatch_async),目的时开辟分线程,把耗时操作放在分线程中执行,但过多的线程数与项目的性能是成反比的,所以控制并发、提高性能则尤为重要,如下例:
// 创建信号量并初始值为5,最大并发量5
dispatch_semaphore_t semaphore = dispatch_semaphore_create(5);
dispatch_queue_t queue = dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_DEFAULT, 0);
for (int i = 0;i < 100 ; i ++) {
dispatch_semaphore_wait(semaphore, DISPATCH_TIME_FOREVER);
dispatch_async(queue, ^{
NSLog(@"i = %d %@",i,[NSThread currentThread]);
//此处模拟一个 异步下载图片的操作
sleep(arc4random()%6);
dispatch_semaphore_signal(semaphore);
});
}
分析:上例初始信号量为5,即最多允许同时有5个资源可以进入临界区域,解释上面的功能就是最多只允许5张图片同时下载,因为图片大小不同,所以耗时也不同,谁先执行完就会调用signal函数,使信号量加1,然后再允许一个资源进入临界区域,依次达到控制最大并发量的目的。
下载图片是分线程中执行,虽然最大并发量是5,但是不一定就开辟5个线程,实际需要开辟多少线程和当前CPU资源情况、内存状况、线程池线程数量等决定的。
六、读写锁
读写锁实际是一种特殊的自旋锁,它把对共享资源的访问者划分成读者和写者,读者只对共享资源进行读访问,写者则需要对共享资源进行写操作。这种锁相对于自旋锁而言,能提高并发性,因为在多处理器系统中,它允许同时有多个读者来访问共享资源,最大可能的读者数为实际的逻辑CPU数。写者是排他性的,一个读写锁同时只能有一个写者或多个读者(与CPU数相关),但不能同时既有读者又有写者。
读写锁适合于对数据结构的读次数比写次数多得多的情况. 因为, 读模式锁定时可以共享, 以写模式锁住时意味着独占, 所以读写锁又叫共享-独占锁.
具体实例:
__block pthread_rwlock_t rwlock;
pthread_rwlock_init(&rwlock, NULL);
NSMutableArray *arrayM = [NSMutableArray array];
void(^WrightBlock)(NSString *) = ^ (NSString *str) {
pthread_rwlock_wrlock(&rwlock);
NSLog(@"开启写操作");
[arrayM addObject:str];
sleep(2);
pthread_rwlock_unlock(&rwlock);
};
void(^ReadBlock)(void) = ^ {
pthread_rwlock_rdlock(&rwlock);
NSLog(@"开启读操作");
sleep(1);
NSLog(@"读取数据:%@",arrayM);
pthread_rwlock_unlock(&rwlock);
};
for (int i = 0; i < 5; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
WrightBlock([NSString stringWithFormat:@"%d",i]);
});
}
for (int i = 0; i < 5; i++) {
dispatch_async(dispatch_get_global_queue(0, 0), ^{
ReadBlock();
});
}
七、栅栏
栅栏函数在GCD中常用来控制线程同步,在队列中它总是等栅栏之前的任务执行完,然后执行栅栏自己的任务,执行完自己的任务后,再继续执行栅栏后的任务。常用函数有同步栅栏函数(dispatch_barrier_sync)和异步栅栏函数(dispatch_barrier_async)。
具体实例:
// 并发队列
dispatch_queue_t queue = dispatch_queue_create("com.gcd.brrier", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(queue, ^{
sleep(1);
NSLog(@"任务1 -- %@",[NSThread currentThread]);
});
dispatch_async(queue, ^{
sleep(2);
NSLog(@"任务2 -- %@",[NSThread currentThread]);
});
// 栅栏函数,修改同步栅栏和异步栅栏,观察“栅栏结束”的打印位置
dispatch_barrier_sync(queue, ^{
for (int i = 0; i < 4; i++) {
NSLog(@"任务3 --- log:%d -- %@",i,[NSThread currentThread]);
}
});
// 在这里执行一个输出
NSLog(@"栅栏结束");
dispatch_async(queue, ^{
sleep(1);
NSLog(@"任务4 -- %@",[NSThread currentThread]);
});
dispatch_async(queue, ^{
sleep(2);
NSLog(@"任务5 -- %@",[NSThread currentThread]);
});
上例中的代码是在主线程中执行的,当我们使用同步栅栏函数时,NSLog(@"栅栏结束")会在栅栏任务执行完之后输出,当使用异步栅栏函数时,NSLog(@"栅栏结束")会在刚开始就输出,说明同步栅栏函数会阻塞当前线程,功能类似于同步函数(dispatch_sync)。
注意:在使用栅栏函数时,只有使用自定义并发队列才有意义,如果用的是串行队列或者系统提供的全局并发队列,这个栅栏函数的作用等同于一个同步函数的作用。
八、原子操作atomic
原子操作是指不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch(换到另一个线程)。
属性的默认是atomic的,对于atomic的属性,系统会生成setter和getter方法时会确保set、get操作的完整性,据说setter和getter内部是通过添加自旋锁的方式保证其操作安全的。例如当线程A对属性进行getter操作时,线程B对属性进行setter操作,那么线程A仍能获取到完整无损的属性值。但是是不是说atomic就是多线程安全的呢?答案是不能,看下面例子:
// 添加一个atomic属性
@property (atomic, copy) NSString *name;
dispatch_queue_t concurrentQueue = dispatch_queue_create("com.gcd.concurrent", DISPATCH_QUEUE_CONCURRENT);
dispatch_async(concurrentQueue, ^{// 线程1
self.name = @"张三";//setter操作
});
dispatch_async(concurrentQueue, ^{// 线程2
self.name = @"李四";//setter操作
});
dispatch_async(concurrentQueue, ^{// 线程3
self.name = @"王二";//setter操作
// 这里有一个稍微耗时的操作,完事后想利用name的值,因为模拟需求是要把名字叫王二的人叫来
sleep(2);
NSLog(@"叫王二来一趟,name = %@",self.name);//getter操作
});
dispatch_async(concurrentQueue, ^{// 线程4
self.name = @"麻子";//setter操作
});
输出:
LockTest[18309:3431300] 叫王二来一趟,name = 麻子
上例中我们模拟需求是希望在线程3中修改属性name的值为“王二”,在执行完耗时操作时会用到这值“王二”,同时还有线程1、2、3在对属性name进行setter操作,最后打印的name却是“麻子”。说明在多线程操作时,atomic并不能保证多线程安全,能够保证的是读/写操作原子性,得到一个完整无损的数据。更多可以看看薯妹的文章。
有atomic就有nonatomic(非原子操作),对于nonatomic的属性,系统为其生成的setter、getter方法并不是安全的,它允许多个线程同时对属性进行读/写操作。例如线程A对属性进行getter操作,同时又有多个线程对属性进行setter操作,那么get到的数据可能是一个我们自己都不认识的垃圾数据。
结论:atomic是读/写操作安全的(操作的原子性),但不能保证多线程安全;nonatomic不能保证读写操作的安全(操作非原子性),也不能保证多线程安全;但是nonatomic的性能比atomic高,如果不涉及多线程操作,使用nonatomic是不错的选择,因为他可以保证性能的同时还能确保数据安全;如果开发中涉及到大量多线程操作,那么务必使用atomic,因为相对于性能而言,数据的正确安全更为重要。能在性能和安全之间找到平衡是最考验程序员的!!!
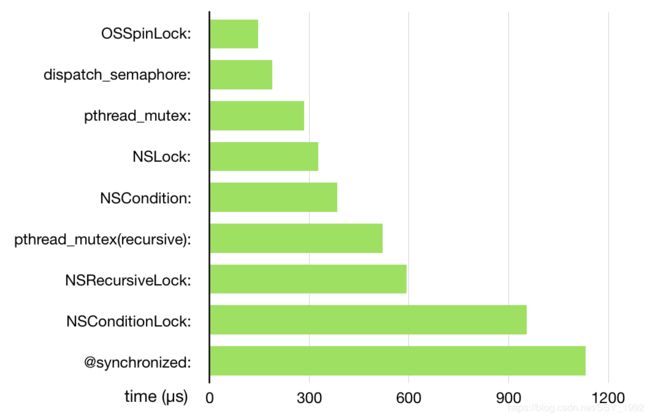
以上是常见几种锁的介绍,YY大神曾作出过几种锁的性能测试,但是只是测试了单线程的情况,不能反映多线程下的实际性能,所以这个结果只能当作一个定性分析: