(十七)论文阅读 | 目标检测之YOLOv4
简介

Y O L O v 4 {\rm YOLOv4} YOLOv4是继 Y O L O v 3 {\rm YOLOv3} YOLOv3之后提出的又一高性能目标检测算法。 Y O L O v 3 {\rm YOLOv3} YOLOv3凭借其结构简单、便于实现、实时性好、精度高等特点,在实际中被广泛应用。 Y O L O {\rm YOLO} YOLO系列是一阶段目标检测方法的代表,而 v 3 {\rm v3} v3又是这一系列算法的代表,相比于 Y O L O v 3 {\rm YOLOv3} YOLOv3, Y O L O v 4 {\rm YOLOv4} YOLOv4在大幅提高精度的前提下保证了模型的实时性。
论文原文 源码
在进行下面部分前,我们首先了解 Y O L O v 3 {\rm YOLOv3} YOLOv3的相关内容。如下图(图来自这里):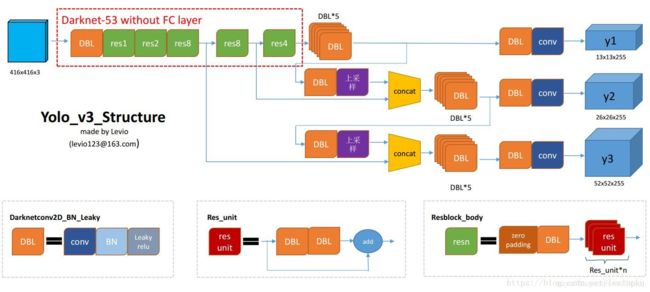
首先, Y O L O v 3 {\rm YOLOv3} YOLOv3的特征提取部分使用的是 D a r k N e t 53 {\rm DarkNet53} DarkNet53,其结构如下图: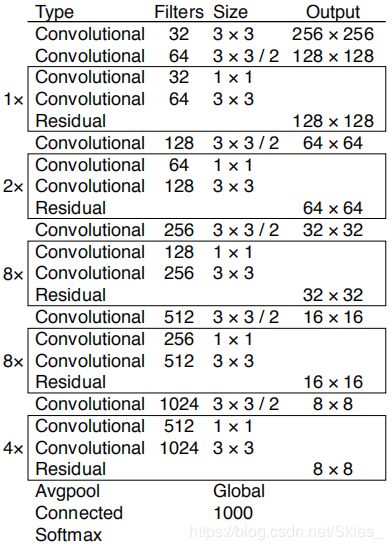
D a r k N e t 53 {\rm DarkNet53} DarkNet53的特点有:使用步长为 2 2 2的卷积操作代替池化;仅使用 3 × 3 3×3 3×3和 1 × 1 1×1 1×1的小卷积核;通过堆叠残差模块形成最终的网络结构(这也是现在很多模型采用的方法,即首先定义每一个块的结构,然后以合适的方式堆叠不同数量的块)。
其次,由于是一阶段算法, Y O L O v 3 {\rm YOLOv3} YOLOv3直接回归目标的类别和边界框,如图 2 2 2中蓝色输出块所示,其共产生三种不同尺度的输出。其中,每一种尺度设置三种先验框,尺寸通过聚类得到。最后,给出实验结果对比图: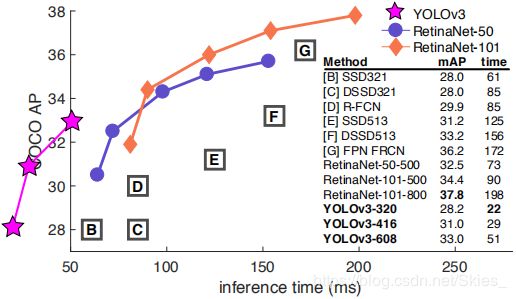
0. Abstract
作者将 Y O L O v 3 {\rm YOLOv3} YOLOv3结合大量 t r i c k s {\rm tricks} tricks,在数据处理、特征提取、网络回归等方面进行改善,得到 Y O L O v 4 {\rm YOLOv4} YOLOv4。实验结果为在 M S C O C O {\rm MS\ COCO} MS COCO数据集上的 A P {\rm AP} AP为 43.5 % {\rm 43.5\%} 43.5%, F P S {\rm FPS} FPS为 ~ 65 ( T e s l a V 100 ) {\rm ~65(Tesla\ V100)} ~65(Tesla V100)。
论文贡献:(一)提出一个高性能的检测器,可以在 1080 T i {\rm 1080Ti} 1080Ti或 2080 T i {\rm 2080Ti} 2080Ti上训练该模型;(2)实验验证了大量针对目标检测的 t r i c k s {\rm tricks} tricks的有效性;(3)改善优化方法,使模型更能适应于单 G P U {\rm GPU} GPU训练。
1. Introduction
Y O L O v 4 {\rm YOLOv4} YOLOv4的实验结果对比:
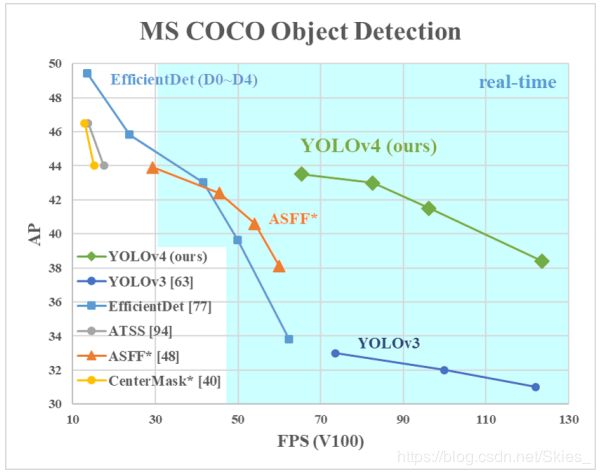
2. Related Work
由于论文涉及大量 t r i c k s {\rm tricks} tricks,本文在相关工作部分列举出论文中使用的相关方法,而作者的实验都是基于这些方法的,具体可查阅相关论文。
2.1 Object Detection Models
目标检测方法有以下分类:
- 在 G P U {\rm GPU} GPU上运行的模型,该类模型的 b a c k b o n e {\rm backbone} backbone包括 V G G {\rm VGG} VGG、 R e s N e t {\rm ResNet} ResNet、 R e s N e X t {\rm ResNeXt} ResNeXt、 D e n s e N e t {\rm DenseNet} DenseNet等;
- 在 C P U {\rm CPU} CPU上运行的模型,该类模型的 b a c k b o n e {\rm backbone} backbone包括 S q u e e z e N e t {\rm SqueezeNet} SqueezeNet、 M o b i l e N e t {\rm MobileNet} MobileNet、 S h u f f l e N e t {\rm ShuffleNet} ShuffleNet等;
- 两阶段检测方法,包括 R C N N {\rm RCNN} RCNN系列、 R – F C N {\rm R–FCN} R–FCN、 L i b r a R – C N N {\rm Libra\ R–CNN} Libra R–CNN等;
- 一阶段检测方法,包括 Y O L O {\rm YOLO} YOLO系列、 S S D {\rm SSD} SSD、 R e t i n a N e t {\rm RetinaNet} RetinaNet等;
- 两阶段无框检测方法,包括 R e p P o i n t s {\rm RepPoints} RepPoints等;
- 一阶段无框检测方法,包括 C e n t e r N e t {\rm CenterNet} CenterNet、 C o r n e r N e t {\rm CornerNet} CornerNet、 F C O S {\rm FCOS} FCOS等;
- 模型的颈( n e c k {\rm neck} neck)包括 F P N {\rm FPN} FPN、 P A N {\rm PAN} PAN、 B i P A N {\rm BiPAN} BiPAN、 N A S – F P N {\rm NAS–FPN} NAS–FPN等;
其他包括 D e t N e t {\rm DetNet} DetNet、 D e t N A S {\rm DetNAS} DetNAS、 S p i n e N e t {\rm SpineNet} SpineNet、 H i t D e t e c t o r {\rm HitDetector} HitDetector等。
2.2 Bag of Freebies
目标检测模型通常以离线的方式训练(针对整体数据集进行训练,即先使用全部数据集训练模型,再使用模型;相对比的是在线训练,即边训练边使用模型的实时训练方式),研究者通常致力于设计更有效的训练方法,对于目标检测常用的是数据增强( D a t a A u g m e n t a t i o n {\rm Data\ Augmentation} Data Augmentation)。数据增强的目的是增加输入图像的多样性,以增强模型针对不同场景的鲁棒性。
首先,常用的数据增强方法包括亮度变化(亮度、对比度、明度、饱和度、噪声等)、几何变换(缩放、裁剪、旋转等)。上述方法都是像素级调整,调整后原始像素的信息得以保留。此外还有其他种类方法:随机擦除和 C u t O u t {\rm CutOut} CutOut等随机地将图像中的矩形区域用随机或特定像素值填充; M i x U p {\rm MixUp} MixUp和 C u t M i x {\rm CutMix} CutMix等同时使用融合多幅图像进行增强;将 G A N {\rm GAN} GAN的方法应于图像增强等。
其次,不同于上述方法,还有通过增强数据集的语义信息的方法,这类方法往往解决的是样本不平衡问题。难例负样本挖掘和 O H E M {\rm OHEM} OHEM是两阶段检测方法中常用的方法,以及在一阶段检测方法中常使用的 F o c a l L o s s {\rm Focal\ Loss} Focal Loss。此外,还有 L a b e l S m o o t h i n g {\rm Label\ Smoothing} Label Smoothing用于提高模型鲁棒性、使用知识蒸馏设计标签精细化网络等。
最后是关于回归网络的目标函数设计。传统使用的是均方根误差( M S E {\rm MSE} MSE),它直接对边界框的中心点以及宽、高或左上角顶点及右下角顶点回归。但这类方法仅独立地关注边界框属性,没有利用其整体信息。为了解决上述问题,又出现了 I o U L o s s {\rm IoU\ Loss} IoU Loss,以及 G I o U {\rm GIoU} GIoU、 D I o U {\rm DIoU} DIoU、 C I o U {\rm CIoU} CIoU等改进。
2.3 Bag of Specials
目标检测模型中通常采用特定的模块以增大感受野、引入注意力机制、增强特征融合等,以及某些后处理手段是筛选模型的有效方法。首先,常用的用于增大感受野的方法有 S P P {\rm SPP} SPP、 A S P P {\rm ASPP} ASPP、 R F B {\rm RFB} RFB。其次,目标检测中常用到的注意力模块是通道注意力和点注意力,二者的代表分别是 S E {\rm SE} SE和 S A M {\rm SAM} SAM。最后,对于特征融合模块,常用到的有 S F A M {\rm SFAM} SFAM、 A S F F {\rm ASFF} ASFF、 B i F P N {\rm BiFPN} BiFPN等。
此外,还有许多关于对激活函数的研究, R e L U {\rm ReLU} ReLU是常用的激活函数,及对它的改进有 L R e L U {\rm LReLU} LReLU、 P R e L U {\rm PReLU} PReLU、 R e L U 6 {\rm ReLU6} ReLU6、 S E L U {\rm SELU} SELU、 S w i s h {\rm Swish} Swish、 h a r d – S w i s h {\rm hard–Swish} hard–Swish等。
常用的后处理模块是 N M S {\rm NMS} NMS,它的作用是过滤掉某些高置信度的错误预测结果,及对它的改进有 s o f t – {\rm soft–} soft– N M S {\rm NMS} NMS、 D I O U N M S {\rm DIOU\ NMS} DIOU NMS等。
3. Methodolody
3.1 Selection of Architecture
作者在设计网络结构时的原则是尽量平衡输入图像分辨率、卷积层数、模型参数、卷积核数。作者通过大量实验对比,最后选择 C S P D a r k N e t 53 {\rm CSPDarkNet53} CSPDarkNet53作为模型的特征提取网络( C S P D a r k N e t 53 {\rm CSPDarkNet53} CSPDarkNet53源自 C S P N e t {\rm CSPNet} CSPNet和 D a r k N e t 53 {\rm DarkNet53} DarkNet53)。下图展示了几种模型的参数对比:
此外, Y O L O v 4 {\rm YOLOv4} YOLOv4使用 S P P {\rm SPP} SPP模块以增大感受野、使用 P A N e t {\rm PANet} PANet作为特征融合模块,以及使用 Y O L O v 3 {\rm YOLOv3} YOLOv3的检测头。
3.2 Selection of BoF and BoS
本部分对应于上述 ( 2.2 ) (2.2) (2.2)和 ( 2.3 ) (2.3) (2.3)部分。
3.3 Additional Improvements
为了使得模型可以更适用于在单 G P U {\rm GPU} GPU上训练,作者对模型进行如下改善:
- 提出新的数据增强方法,包括 M o s a i c {\rm Mosaic} Mosaic和自对抗训练( S e l f A d v e r s a r i a l T r a i n i n g , S A T {\rm Self\ Adversarial\ Training,SAT} Self Adversarial Training,SAT);
- 使用遗传算法的同时使用最佳超参数;
- 对 S A M {\rm SAM} SAM、 P A N {\rm PAN} PAN和 B N {\rm BN} BN改进。
M o s a i c {\rm Mosaic} Mosaic的思路是将 4 4 4张图像融合,这就使得结果包含 4 4 4种不同的上下文信息(如图 7 7 7)。自对抗训练是一
种新的数据增强方法。在前向传播过程中,模型改变输入图像而非权重以使得网络进行自抗性攻击。在反向传播过程中,模型针对对抗样本进行训练。
C m B N {\rm CmBN} CmBN是对 B N {\rm BN} BN的改进,它仅收集单个批次中小批数据间的信息,如下图: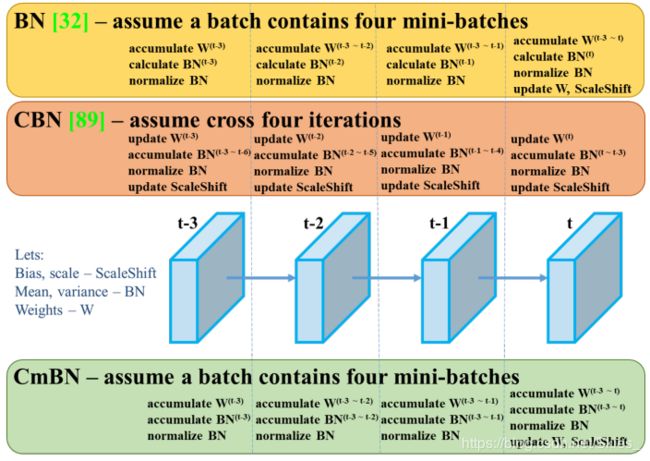
论文将 S A M {\rm SAM} SAM中的空间注意力替换为点注意力;将 P A N {\rm PAN} PAN中的特征融合方式由相加改为拼接。
3.4 YOLOv4
最后,总结一下 Y O L O v 4 {\rm YOLOv4} YOLOv4的各个部分: Y O L O v 4 {\rm YOLOv4} YOLOv4由 C S P D a r k N e t 53 {\rm CSPDarkNet53} CSPDarkNet53( B a c k b o n e {\rm Backbone} Backbone)、 S P P , P A N {\rm SPP,PAN} SPP,PAN( N e c k {\rm Neck} Neck)、 Y O L O v 3 {\rm YOLOv3} YOLOv3( H e a d {\rm Head} Head)组成,用到的 t r i c k s {\rm tricks} tricks包括:
- 对于 b a c k b o n e {\rm backbone} backbone的 B o F {\rm BoF} BoF: C u t M i x {\rm CutMix} CutMix和 M o s a i c {\rm Mosaic} Mosaic数据增强方法、 D r o p B l o c k {\rm DropBlock} DropBlock正则化、 L a b e l S m o o t h i n g {\rm Label\ Smoothing} Label Smoothing;
- 对于 b a c k b o n e {\rm backbone} backbone的 B o S {\rm BoS} BoS: M i s h {\rm Mish} Mish激活函数、 C S P {\rm CSP} CSP、多输入加权残差连接( M i W R C {\rm MiWRC} MiWRC);
- 对于 d e t e c t o r {\rm detector} detector的 B o F {\rm BoF} BoF: C I o U {\rm CIoU} CIoU、 C m B N {\rm CmBN} CmBN、 D r o p B l o c k {\rm DropBlock} DropBlock正则化、 M o s a i c {\rm Mosaic} Mosaic数据增强方法、自对抗训练、消除网络敏感性、多个 a n c h o r {\rm anchor} anchor匹配一个标注框、余弦退火策略、最佳超参数、训练时随机尺寸;
- 对于 d e t e c t o r {\rm detector} detector的 B o S {\rm BoS} BoS: M i s h {\rm Mish} Mish激活函数、 S P P {\rm SPP} SPP模块、 S A M {\rm SAM} SAM模块、 P A N {\rm PAN} PAN模块、 D I o U – N M S {\rm DIoU–NMS} DIoU–NMS模块。
4. Experiments
这里直接给出各目标检测模型的实验结果对比: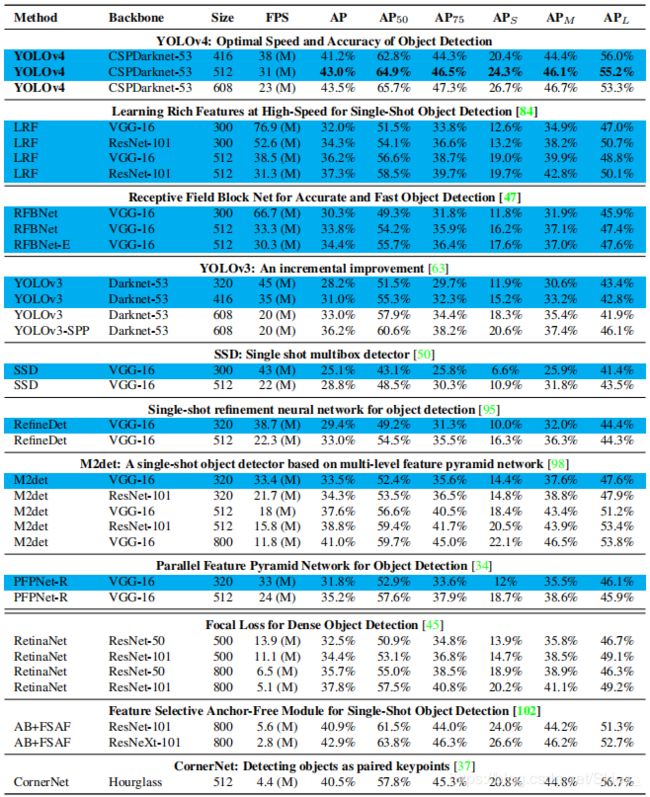
5. Conclusion
论文提出的 Y O L O v 4 {\rm YOLOv4} YOLOv4在所有一阶段检测算法上表现 S O T A {\rm SOTA} SOTA,其通过综合各种有效的模块、加上合适的训练方法,得到一个高性能模型。此外, Y O L O v 4 {\rm YOLOv4} YOLOv4可以在很多单 G P U {\rm GPU} GPU上训练,这表明模型的优化方面还是做得挺好的。
虽然 Y O L O v 4 {\rm YOLOv4} YOLOv4的精度和速度表现较好,但模型综合了大量的 t r i c k s {\rm tricks} tricks,可以预见到模型在训练过程中的收敛情况不如 Y O L O v 3 {\rm YOLOv3} YOLOv3。此外,相比较于 Y O L O v 3 {\rm YOLOv3} YOLOv3, Y O L O v 4 {\rm YOLOv4} YOLOv4的模型更加复杂、训练元素更加繁多,这导致很多人不会将 Y O L O v 4 {\rm YOLOv4} YOLOv4作为首选方案。构建一个结构简单、性能高效、训练方便的模型才是人们所追捧的, Y O L O v 3 {\rm YOLOv3} YOLOv3和 S S D {\rm SSD} SSD在实际应用中的表现就印证了这一点。最后文中涉及大量论文的思想,具体某项技术的思想和实现可参考相应论文。
由于没有阅读源码,本文只总结了 Y O L O v 4 {\rm YOLOv4} YOLOv4的大体结构和信息,详细内容请阅读论文原文。
参考
- Redmon J, Farhadi A. Yolov3: An incremental improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
- Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal Speed and Accuracy of Object Detection[J]. arXiv preprint arXiv:2004.10934, 2020.