论文浅尝 | BAG:面向多跳推理问答得双向 Attention 实体图卷积网络
论文笔记整理:谭亦鸣,东南大学博士生,研究兴趣:知识图谱问答

来源:NAACL 2019
链接:https://www.aclweb.org/anthology/N19-1032/
实现多跳推理问答需要模型能够充分理解文本和 query 之间的关系,本文提出了一种双向注意力实体图卷积网络(BAG),该方法利用实体图中的节点及实体图与query之间的attention信息处理上述推理问答任务。其中,实体图通过文本的多层特征构建得到,图卷积网络用于获取实体图中节点的表示(带有关系感知信息),双向attention被用到图与query上,以生成query感知的节点表示,将用于最后的预测中。在QAngaroo WIKIHOP数据集上的实验表明,BAG是目前准确度最高的模型。
动机
作者发现,在 QAngaroo 任务中(该数据集含有多个文本,目标是对于给定的 query,从一系列候选答案中找出正确的那个),大多数情况下,仅依赖一篇文档无法获得query对应的答案,问答过程需要通过文档之间的多跳推理来完成。因此,仅理解部分文本段落可能会使多跳推理失去有效性,对于过去的模型来说,这是一个巨大的挑战。
本文提出基于图的 QA 模型,将多个文本转换为图,其中的节点是实体,边是实体之间的关系(多源文本->单个图谱),接着使用一个图卷积网络对实体图中带有关系感知的节点做表示学习。而后在图和带有multi-level feature的query之间构建一个双向attention,用于最后的预测。
贡献
作者总结本文贡献如下:
在query和图之间使用一个双向attention建立基于query感知的表示学习用于阅读理解;
利用multi-level feature参与理解关系,同于图节点的GCN表示学习过程。
方法
首先,作者正式定义多跳QA任务(以QAngarooWIKIHOP数据集为例)如下:
给定一个文档集包含N个文档,任务目标是对于query(包含M个token),从候选答案列表C中找出正确答案(或列表中的答案索引)。
多跳推理示例:
给定一个 triple-style query q=(country, kepahiang),表示的是自然语言问题“which country does kepahiang belongs to”
候选答案如 C = {Indonesia, Malaysia}
现有一系列文本,但他们的内容并不完全与我们需要的推理相关
比如: Kephiang is a regency inBengkulu,
Bengkulu is one of province of Indonesia,
Jambi is a province of Indonesia
根据上述文本我们可以推理得到答案是 Indonesia,且推理仅基于前两句文本。
下图是 BAG 模型框架,主要包含五个部分:1) 实体图建立;2) Multi-level feature层;3) GCN层;4) 双向attention;5) 输出层
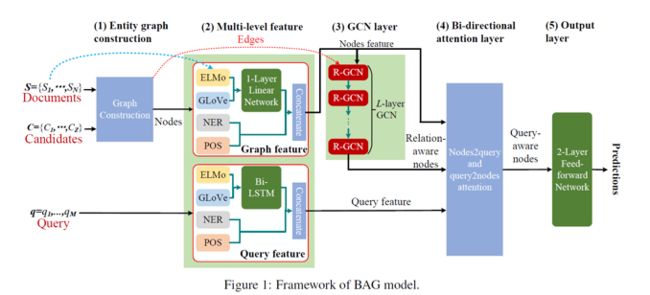
关于实体图
实体图构建基于Entity-GCN (De Cao et.al., 2018)模型实现,将所有文本中找到的实体都作为图中节点,每个节点对之间根据位置属性定义无向边。图中包含两类边:
cross-document edge:同一实体文本出现在不同文本中
within-document edge:每个节点对都在同一文本中
这样的做法使得实体图中的节点都可以通过字符匹配精确找到,而问题的答案也一定在实体图中。
关于 Multi-level Features
论文使用了GLoVe提供预训练word embedding用于node的节点表示,ELMo用于获取涵盖query上下文信息中的词表示,对于实体图,使用1层线性网络进行特征学习,对于query则使用双向LSTM,之后与NER及POS特征连接,完成整个特征融合步骤。
GCN层
为了实现多跳推理,作者使用了Relational Graph Convolutional Network(R-GCN, Schlichtkrull et al., 2018),该方法实现了图中不同实体节点之间的信息传递,并且生成转换后的表示。
R-GCN被用于处理高相关数据特征,并使用到不同的边类型。
在第l层,给定节点i,j的隐状态,以及i所有relation RNi关联到的邻居,其下一层的隐状态更新为:
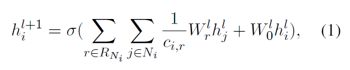
其中c为标准化因子,Wr为relation special权重矩阵,W0为普通权重矩阵。
在这个基础上,与Entity-GCN类似,作者也使用了门(一个线性转换函数f)用于更新当前节点的向量及隐状态:
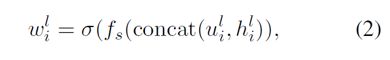
在f中u可以通过公式1得到(无sigmoid函数),之后可以被用来更新不同层中同一节点的隐状态的权重:
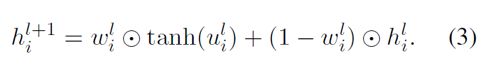
图和query之间的双向Attention
双向attention负责生成图和query之间的交互信息,在BiDAF(Seo et al., 2016)中,attention被用于帮助处理序列数据。作者发现,这个方法也可以用于节点和query,它能够生成query感知的节点表示,能够为推理预测提供信息。
不同的是,在BAG中attention被应用于图,相似矩阵S可以通过以下公式计算:
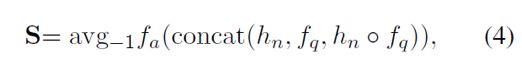
其中,hn是所有节点的表示,由GCN层得到,f是编码之后的query特征,fa是一个线性转换,avg-1表示在最后一维做平均操作,表示逐元素相乘。
与BiDAF构建context-to-query attention不同,本文构建一种node-to-query attention,用于强调与query最相关的节点,通过以下公式实现:
![]()
其中,softmaxcol表示在整列数据上执行softmax,·表示矩阵乘法。
同时,作者也构建了query-to-node attention,形如:
![]()
col表示的意义与(5)一样,dup函数的功能则是将其后内容复制T次,以控制矩阵维度,fn是未经GCN处理过的原始节点特征。
通过对node-to-query/query-to-node以及特征表示的整合,双向attention的输出被定义为:
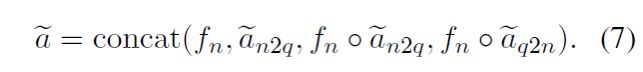
整个框架的输出层由两层全连接前馈网络构成,用于生成最终的预测结果。
实验
实验数据
本文实验基于QAngaroo WIKIHOP数据集(Welbl et al., 2018)
训练集,开发集及测试集的规模分别为43,738,5,129与2,451
作者罗列了其实验使用的 ELMo/GLoVe 的维度设定,其中 ELMo 为 1024维,GloVe 为 300 维,预训练由840B的Web数据得到,NER 和POS特征均表示维8维。
实验结果
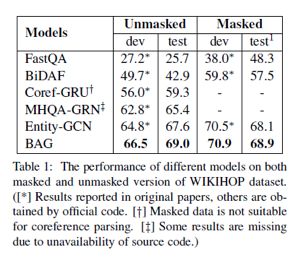
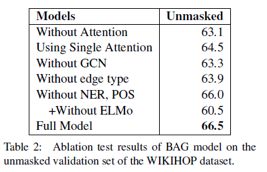
表1列举了多跳问答的实验结果,评价指标维准确度。
表2列举了BAG在开发集上的增量模型实验。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。