基于BiLSTM+CRF的中文分词(CWS)(附代码以及注释)
本人菜鸟,很多地方都是看其他的博客学到的,自己也说不清楚,就贴出来供大家学习,写的不好大家包涵!
之前做过HMM进行中文分词,这次使用BiLSTM加CRF(条件随机场)进行中文分词。
HMM中文分词:https://blog.csdn.net/Yang_137476932/article/details/105467673
本文代码github地址:https://github.com/WhiteGive-Boy/CWS-Hmm_BiLSTM-CRF
biLSTM,指的是双向LSTM;CRF指的是条件随机场。这俩算法在CWS,NER等自然语言处理的领域都表现的不错,CRF貌似很多时候都用来处理这类词性标注的问题。
1.模型简略介绍
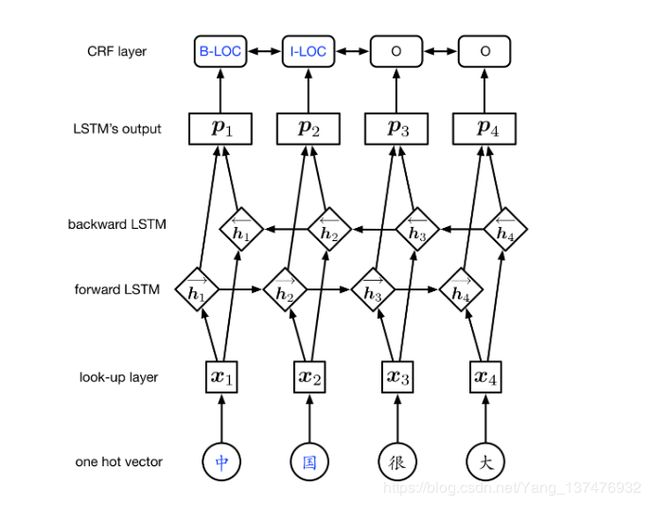
这张图很多写lstm+crf进行词性标注的地方都有,简略的分析下

输入序列{w0,w1,w2,w3,.... } 具体到中文分词来说 Wi为单个汉字的word_embedding,我们输入的序列是一个句子一个sentence的向量表示,所以真正的模型应该在输入前再价格Embedding层。将我们的word序列输入到双向LSTM中,得到每个word对于每个tag状态的概率,之后将这个得到的概率输入到CRF,结合另一个需要训练的各个状态间的转移参数,计算每个句子的score,score也即模型需要训练的loss,score的计算方式是我们训练的状态序列的score除所有可能路径的score和,即让我们的正确的状态序列的score占的比重最大,这里结合了各个状态间的转移矩阵以及所有路径的score和,让我们正确路径的比重最大,这可能是CRF让很多模型效果更优的原因。
这里可以参考这个博文,大佬讲的很细致,这里一定要弄懂,不然看不懂代码https://blog.csdn.net/b285795298/article/details/100764066
上面博文的贴图:

2.具体实现
2.1数据处理
import codecs
from sklearn.model_selection import train_test_split#进行训练集和测试集划分
import pickle#进行参数保存
INPUT_DATA = "./RenMinData.txt_utf8"#数据集
SAVE_PATH="./datasave.pkl"#保存路径
id2tag = ['B','M','E','S'] #B:分词头部 M:分词词中 E:分词词尾 S:独立成词 id与状态值
tag2id={'B':0,'M':1,'E':2,'S':3}#状态值对应的id
word2id={}#每个汉字对应的id
id2word=[]#每个id对应的汉字
def getList(input_str):
'''
单个分词转换为tag序列
:param input_str: 单个分词
:return: tag序列
'''
outpout_str = []
if len(input_str) == 1: #长度为1 单个字分词
outpout_str.append(tag2id['S'])
elif len(input_str) == 2:#长度为2 两个字分词,BE
outpout_str = [tag2id['B'],tag2id['E']]
else:#长度>=3 多个字分词 中间加length-2个M 首尾+BE
M_num = len(input_str) -2
M_list = [tag2id['M']] * M_num
outpout_str.append(tag2id['B'])
outpout_str.extend(M_list)
outpout_str.append(tag2id['E'])
return outpout_str
def handle_data():
'''
处理数据,并保存至savepath
:return:
'''
x_data=[] #观测值序列集合
y_data=[]#状态值序列集合
wordnum=0
line_num=0
with open(INPUT_DATA,'r',encoding="utf-8") as ifp:
for line in ifp:#对每一个sentence
line_num =line_num+1
line = line.strip()
if not line:continue
line_x = []
for i in range(len(line)):
if line[i] == " ":continue
if(line[i] in id2word): #word与id对应进行记录
line_x.append(word2id[line[i]])
else:
id2word.append(line[i])
word2id[line[i]]=wordnum
line_x.append(wordnum)
wordnum=wordnum+1
x_data.append(line_x)
lineArr = line.split(" ")
line_y = []
for item in lineArr:#对每一个分词进行状态值转换
line_y.extend(getList(item))
y_data.append(line_y)
print(x_data[0])
print([id2word[i] for i in x_data[0]])
print(y_data[0])
print([id2tag[i] for i in y_data[0]])
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.2, random_state=43) #分为训练集和测试集
with open(SAVE_PATH, 'wb') as outp: #保存
pickle.dump(word2id, outp)
pickle.dump(id2word, outp)
pickle.dump(tag2id, outp)
pickle.dump(id2tag, outp)
pickle.dump(x_train, outp)
pickle.dump(y_train, outp)
pickle.dump(x_test, outp)
pickle.dump(y_test, outp)
if __name__ == "__main__":
handle_data()
2.2 模型实现
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
START_TAG = "" #为每个句子添加开始和结束的tag
STOP_TAG = ""
def argmax(vec):
'''
计算一维vec最大值的坐标
'''
# return the argmax as a python int
_, idx = torch.max(vec, 1)
return idx.item()
def log_sum_exp(vec):
'''
计算vec的 log(sum(exp(xi)))=a+log(sum(exp(xi-a)))
'''
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1])
return max_score + \
torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
class Model(nn.Module):
def __init__(self, vocab_size, tag2id, embedding_dim, hidden_dim):
super(Model, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag2id = tag2id
self.tagset_size = len(tag2id)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim) #embedding层 将word映射为向量
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True) #LSTM层,输入一个word序列(一个句子),输出hidden层
# Maps the output of the LSTM into tag space.
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size) #线性转换层,将LSTM的输出结果映射为每个word针对各个状态的概率
# Matrix of transition parameters. Entry i,j is the score of
# transitioning *to* i *from* j = trans[i][j] 表示从j转移至i 注意 是颠倒的
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size)) #状态转移矩阵
# These two statements enforce the constraint that we never transfer
# to the start tag and we never transfer from the stop tag
self.transitions.data[tag2id[START_TAG], :] = -10000 #限制状态转移矩阵的部分值,限制任意状态不能转移至开始状态
self.transitions.data[:, tag2id[STOP_TAG]] = -10000#限制状态转移矩阵的部分值,限制结束状态不能转移至任意状态
self.hidden = self.init_hidden()#初始化LSTM的hidden
def init_hidden(self):
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
def _forward_alg(self, feats):
'''
计算所有可能的状态路径的score和
:param feats: LSTM+hidden2tag的输出
:return: 所有tag路径的score和
forward_var:之前词的score和
'''
# Do the forward algorithm to compute the partition function
init_alphas = torch.full((1, self.tagset_size), -10000.)
# START_TAG has all of the score.
init_alphas[0][self.tag2id[START_TAG]] = 0. #
# Wrap in a variable so that we will get automatic backprop
forward_var = init_alphas
# Iterate through the sentence
for feat in feats: #every word
alphas_t = [] # The forward tensors at this timestep
for next_tag in range(self.tagset_size): #every word's tag
# broadcast the emission score: it is the same regardless of
# the previous tag
emit_score = feat[next_tag].view(
1, -1).expand(1, self.tagset_size)
# the ith entry of trans_score is the score of transitioning to
# next_tag from i
trans_score = self.transitions[next_tag].view(1, -1)
# The ith entry of next_tag_var is the value for the
# edge (i -> next_tag) before we do log-sum-exp
next_tag_var = forward_var + trans_score + emit_score
# The forward variable for this tag is log-sum-exp of all the
# scores.
alphas_t.append(log_sum_exp(next_tag_var).view(1))
forward_var = torch.cat(alphas_t).view(1, -1)
terminal_var = forward_var + self.transitions[self.tag2id[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _get_lstm_features(self, sentence):
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self, feats, tags):
# Gives the score of a provided tag sequence 当前句子的tag路径score
score = torch.zeros(1)
tags = torch.cat([torch.tensor([self.tag2id[START_TAG]], dtype=torch.long), tags])
for i, feat in enumerate(feats):
score = score + \
self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag2id[STOP_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
backpointers = [] #路径保存
# Initialize the viterbi variables in log space
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag2id[START_TAG]] = 0
# forward_var at step i holds the viterbi variables for step i-1
forward_var = init_vvars
for feat in feats: # for every word
bptrs_t = [] # holds the backpointers for this step
viterbivars_t = [] # holds the viterbi variables for this step
for next_tag in range(self.tagset_size): #for every possible tag of the word
# next_tag_var[i] holds the viterbi variable for tag i at the
# previous step, plus the score of transitioning
# from tag i to next_tag.
# We don't include the emission scores here because the max
# does not depend on them (we add them in below)
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# Now add in the emission scores, and assign forward_var to the set
# of viterbi variables we just computed
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# Transition to STOP_TAG
terminal_var = forward_var + self.transitions[self.tag2id[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag2id[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
def forward(self, sentence, tags):
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
def test(self, sentence): # dont confuse this with _forward_alg above.
# Get the emission scores from the BiLSTM
lstm_feats = self._get_lstm_features(sentence)
# Find the best path, given the features.
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq

_forward_alg函数计算上式的最后一项,计算过程:我们先对输入的句子每个字进行循环,对每个字的每个tag都计算score并存储,forward_var存储当前词之前的所有词的score,具体的大家看不懂了可以问我,这里可以仔细阅读https://blog.csdn.net/b285795298/article/details/100764066的CRF loss function部分,结合代码就好理解些。2.3 测试
import pickle
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
import codecs
from model import Model
def calculate(x,y,id2word,id2tag,res=[]):
entity=[]
for j in range(len(x)):
if id2tag[y[j]]=='B':
entity=[id2word[x[j]]]
elif id2tag[y[j]]=='M' and len(entity)!=0:
entity.append(id2word[x[j]])
elif id2tag[y[j]]=='E' and len(entity)!=0:
entity.append(id2word[x[j]])
res.append(entity)
entity=[]
elif id2tag[y[j]]=='S':
entity=[id2word[x[j]]]
res.append(entity)
entity=[]
else:
entity=[]
return res
with open('../data/datasave.pkl', 'rb') as inp:
word2id = pickle.load(inp)
id2word = pickle.load(inp)
tag2id = pickle.load(inp)
id2tag = pickle.load(inp)
x_train = pickle.load(inp)
y_train = pickle.load(inp)
x_test = pickle.load(inp)
y_test = pickle.load(inp)
START_TAG = ""
STOP_TAG = ""
EMBEDDING_DIM = 100
HIDDEN_DIM = 200
EPOCHS = 5
LR=0.005
tag2id[START_TAG]=len(tag2id)
tag2id[STOP_TAG]=len(tag2id)
model = Model(len(word2id) + 1, tag2id, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=LR, weight_decay=1e-4)
for epoch in range(EPOCHS):
index = 0
for sentence, tags in zip(x_train, y_train):
index += 1
model.zero_grad()
sentence = torch.tensor(sentence, dtype=torch.long)
tags = torch.tensor(tags, dtype=torch.long)
loss = model(sentence, tags)
loss.backward()
optimizer.step()
if index % 10000 == 0:
print("epoch", epoch, "index", index)
entityres = []
entityall = []
for sentence, tags in zip(x_test, y_test):
sentence = torch.tensor(sentence, dtype=torch.long)
score, predict = model.test(sentence)
entityres = calculate(sentence, predict, id2word, id2tag, entityres)
entityall = calculate(sentence, tags, id2word, id2tag, entityall)
rightpre = [i for i in entityres if i in entityall]
if len(rightpre) != 0:
precision = float(len(rightpre)) / len(entityres)
recall = float(len(rightpre)) / len(entityall)
print("precision: ", precision)
print("recall: ", recall)
print("fscore: ", (2 * precision * recall) / (precision + recall))
else:
print("precision: ", 0)
print("recall: ", 0)
print("fscore: ", 0)
path_name = "./model/model" + str(epoch) + ".pkl"
torch.save(model, path_name)
print("model has been saved in ", path_name)
使用fscore进行模型的评价,包含precision和recall 准确率和召回率,结果如下
BiLSTM+CRF
参数选择:embedding_dim=100 hidden_dim=200 epoch=1 lr=0.005
precision:0.96975528
recall: 0.96779571
fscore: 0.96877451