领域驱动设计(domain driven design)战略篇之一 战略 & Bounded Context
之前的文章主要从战术层面的角度介绍了ddd。在岛国也被称为轻量级ddd。它提供了一些概念如aggregate, entity, domain event和一些设计模式如repository, specification来帮助我们建模和设计。各种战术还有能够扩展的地方,有机会还会再写下去。不过从这篇文章开始会写一写ddd战略方面的知识。
战略 vs 战术
究竟什么是战略与战术?他们有什么区别?
目测这两个词都来源于战争(自己的理解),战术是偏微观的策略,目的是取得某场战斗或者战役的胜利。诱敌深入,敌进我退之类的可能都属于战术吧。而战略是偏宏观的策略,目的是赢得一场战争,它所关注的不限于军事方面,可能资源的调配,甚至会牵涉到外交等。
扯远了~在领域驱动设计[domain driven design]中战术与战略的概念亦是如此。战术是微观层面的。在之前的文章中的例子中,基本都是为了解决某个十分具体问题而进行的模型设计。这些设计会反应具体的细节。比如一个如何去识别一个entity,一个entity会有什么样的行为。而这些设计会直接反映到我们的代码上。
为什么需要战略
从很抽象的概念上来说,我们应该不难理解为什么我们需要战略。战略与战术他们需要解决的是不同层面的问题。当我们谈宏观问题时,自然是需要战略的。但话是这么说,什么从程序开发的角度来说,什么才是宏观问题?什么又是微观问题?这个好像很难用语言来具体地定义。
假设我们完全不考虑宏观问题。我们想象(想象…)一下只用ddd中介绍的战术知识来进行设计。如今互联网产品的行业可能比较现实的制造产品的方案会是,先做proto type,然后做mvp(minimum viable product 只包含核心功能的产品),然后在mvp的技术上进行后续开发。
mvp
当我们在开发mvp的阶段时,产品的需求可能相对简单。我们分析需求,业务逻辑,然后设计能够描述这些业务的模型。可能10个到20个左右的aggregate就能解决问题。画个简图来表示我们定义的aggregate和其中的entity, value object。
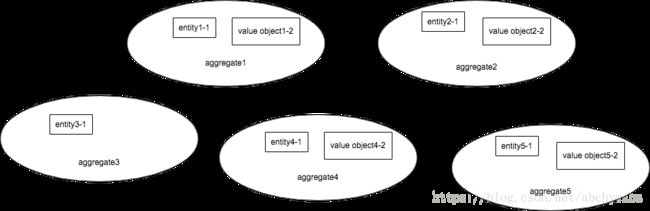
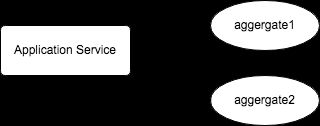
这个时候你的application层的application service可能不需要与很多aggregate交互。
产品进化
随着产品经理对产品的认识更加深入,我们需要追加更多的开发,为了应对新的需求,我们要调整现有的模型,也需要增加新的模型来应对。某个时点,我们可以能已经到达了像图中的一个状况。我们已经无法再在一张图中精确描述aggregate中的元素。

而此时,我们的application层的中的一些application service可能已经不得不与非常多的aggregate进行交互。

当application service包含了很多的aggregate操作时,我们可能不知不觉增加了各个模型间的耦合度,同时也冒着把业务逻辑写进application service的风险。理想情况下,我们希望所有的业务逻辑都在domain层,而application service是很薄的。
另外随着模型量的增加,我们对模型之间的关系也会慢慢模糊。再加上如果是在多人项目中,程序员之间交流会有极限。对于系统的认知里为下降,各种“神奇现象“会开始发生。如下图,模块2里的aggregate3,在设计之初可能设想只有模块2里的东西会对aggregate3进行操作,但项目大了,参与开发的人多了,之前完全没有想到的不知名模块25也对aggregate3进行了操作。对模块25的修改可能影响到了模块2。
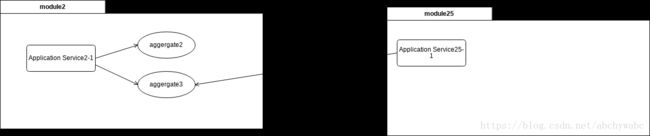
注: 没有专门写文章说明module(模块)这个概念。如果你是java工程师,就把它当成package就行。
进化的究极体—-big ball of mud
当产品的复杂度不断增加,而我们有没有去控制控制这种复杂的话,我们的系统会成为ddd中称作big ball of mud(大泥球)的东西。
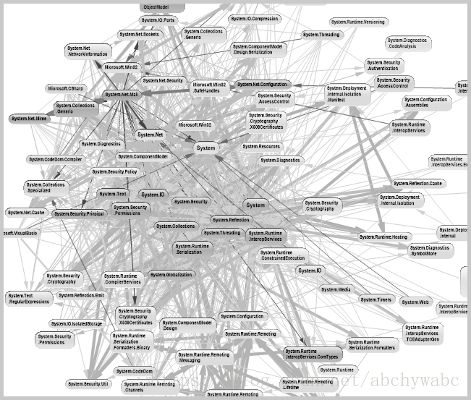
这个说法应该是比较形象的,系统的各种模块已经耦合在一起,很难直观地,整体地理解这个系统的构成。当我们对它无法整体地理解它,各种各样的误判就会发生,系统的各种行为变得难以捉摸。对于程序员来说,在这样的系统基础上开发会是个噩梦。
如何解决这种问题?
前面描述的方法哪里有问题?我们把注意力只集中在了小范围的设计上,我没有对全局进行把控。可能我们在各个模块的层面上,设计是合理的,当把视野放宽时,系统设计却变得很混乱。
很显然,除了战术层面的aggregate, module这样定义边界的概念,我们还需要一个抽象度更高,范围更广的概念来帮助我们把系统进行切分。其实这也符合一般的系统设计的思路,
在传说中的waterfall模式时代,我们会把需求定得十分明确,把尽可能地具体到每个细节(至少岛国就是这种状况。各种纸质设计文档,一审再审,一改再改,最后文档叠起来的高度会不亚于“上海中心“)。但即使在那种设计难以应对变化的年代,在程序设计时也不会一下子就设计到最细小的部分。还是会先分大的区块。比如一个服务,我们需要用多少个子系统来组成它,如何分割子系统,子系统之间如何交互。这写就是战略层面上要考虑的问题。而在子系统中我们会在进行更细节部分的设计。如下图所示,先将服务分成A, B, C三个子系统。其中的子系统B考虑它应该包含什么样的模块。
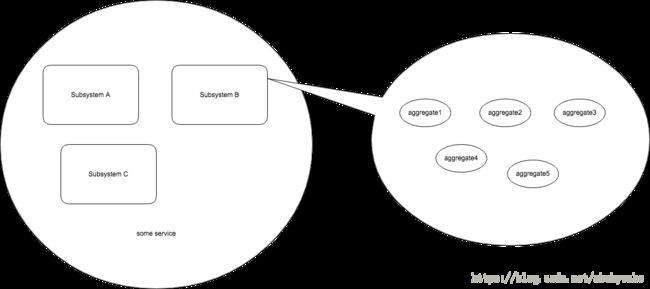
在[领域驱动设计中]提出了bounded context这个概念。直译过来时”边界确定的上下文”。这是一个帮助我们进行系统粗粒度切分的概念。
Bounded Context
个人认为Bounded Context强调的是边界这个概念。这个思想有一个前提,万能的模型是做不到的。我们建模是为了描述或解决现实的问题。而现实问题是复杂的,我们无法建立一个模型是面面俱到,一般我们只会截取自己所关注的一个切面,对它进行建模。
同一个概念,不同模型
比如在一个管理户籍时,我们只关注一个人的姓名,身份证号,住址。在写简历时,我们会关注一个人拥有的技能与工作经验。而在¥%@时,我们会关注一个人的性格等。在现实生活中同样的一个人的概念,它十分复杂,拥有很多的侧面,我们在建模时不会指望构建一个完美的模型,它能够复刻一个人。即使有这样的模型,它肯定也是极度复杂的(在本人目前的认知下),也很有可能超过了我们可以理解的范围。
因此,模型在某一个bounded context中,它是有限的,仅描述它所关注的部分。按上面的例子来说,在一个户籍管理系统中,Person可能就是下面的一个类
class Person (val identification: Identification,
var firstName: String,
var lastName: String,
var address: String) {
}而在一个求职服务里,Person会是这样的
class Person (val id : Long,
val userName: String,
var emailAddress: String,
var resumeId: ResumeId){
}
class Resume(val id: ResumeId,
var education: String,
var professionalExperience: String
var skills: List<Skill>) {
}尽管这两个Person在现实中是相关的,即使他们共同存在于某一个平台,在他们各自的bounded context中,他们是相对独立的,可以想像,这两个Person拥有的行为也会是不同的。
不同的语境,不同的概念
在英语中Account的这个词有不同的意思,一个表示银行的账户,一个表示账号。Account在银行业务,与网络业务的bounded context里会是完全不同的概念。
我们必须认识到这种思路和自然语言是不同的。在自然语言里,一个词可能是多义的,意义也可能是宽泛的。Bounded Context这个概念要求我们在Context中的模型必须是单义的,意义相对狭义的。当一个Bounded Context中的一个模型类开了Bounded Context,它的意义与行为会发生改变。
Bounded Context让我必须认清我们建模时所应该关注的地方。明确我们所关心的点后,我们能更有目的性地建模。同时把不应该在某一个Context关注的东西放到另一个Context。再次提醒!同一个概念,可以出现在在不同的Bounded Context,但是他们会以不同的模型来展现。
如何实现Bounded Context
很遗憾的是,[领域驱动设计]一书中并没有给出操作层面实现Bounded Context的方法。这也导致了Bounded Context的实现成为了一个众说纷纭的话题。这里列举一些实现的方式。
首先Bounded Context并不是一个层,不是要在presentation, application, domain, infrastructure的4层架构中在加一个层。
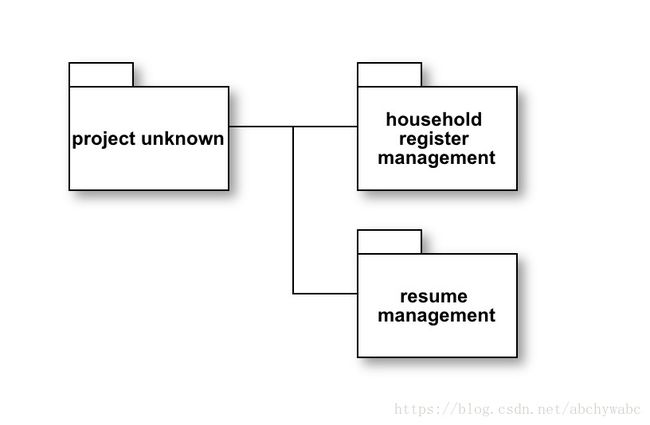
namespace级别的bounded context
如果是java的画,这个就是通过包(package)来构建bounded context。
project级别的bounded context
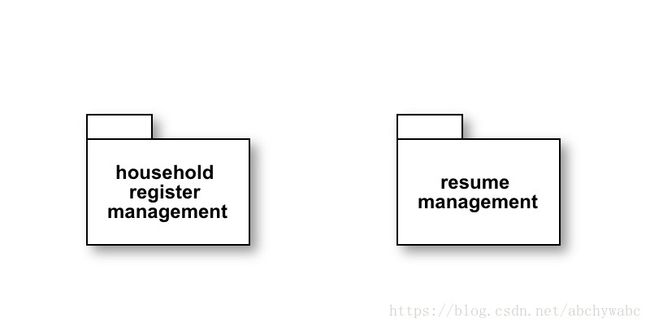
project又是一个很有歧义的词,如果你是java工程师,那project就是代码层面的一个叫project的单位。使用如果你使用intellij开发的话,它会被称为module。总之他们有各自的代码,如果不使用build工具,project A是无法引用project B的代码的。
micro-service级别的bounded context
这个可能不必赘述了把。用一个微服务来实现一个context。
比较
从边界的强度来说
namespace < project < micro-service
使用namespace来实现的话,如果编程语言不对namespace之间类的引用有限制的话,这种边界定义是很弱,很容易打破边界(有意无意)。对越界(package A是否引用package B的类)的检查可能需要人力,从长期来看成本很大。
project级别的话,基本不会有代码层面的越界。但是不同不同的project A, project B可能引用了同一个数据库,这可能会造成隐性的越界。比如A,B中的模块要对同一张数据表进行修改。但在A并不知道有B的存在。A所拥有的数据会在A不知情的情况被修改。
micro-service的边界是最牢固的。如果你不开发接口,基本上做不到越界。
边界初期投入上来说
namespace < project < micro-service
这个显而易见。如果你选择micro-service,意味着你选择了一个复杂的系统架构,你可能还需要一大堆配套的框架。而如果是namespace的话投入基本就是0。
如何实现bounded context是否是该尽早决定的
很显然如何实现bounded context没有一个完美的方案(可能本人没有找到)。无论选择那个选项,都必须做出牺牲,这就成了令人烦恼的权衡问题。
个人觉得,如要考虑的有如下几个要素
1. 对边界的认识是清晰明确
2. 团队技术实力
3. 项目规模
在这几个要素都十分明确的情况下,我们会有足够的信息作出选择。
但如果在边界还不是很清晰,对domain的理解也不成熟,就直接用micro service进行划分是比较危险的。因为一刀割下去割得太彻底,之后发现割错了也没办法缝合了。你可能觉得那只要把需求理解清楚后,把边界明确定义不就行了。很可惜现实情况是需求也是在变的,我们很在初期就把握所有的需求。
所以如果在各个要素都还不明确的情况下,比较实际的做法可能是,一开始选择边界强度低的实现方法,随着对domain理解的深入,明确边界后再过度到强度高的实现(micro service)。不过这种方法有一个隐性前提,边界分割方法的更改可以低成本地实现。如果monolithic的服务能够轻易地变换成微服务,那就不用逼我们在早期冒险做决定。这需要借助其他的一些手段。比如由尽量高的自动测试覆盖率等。
总结
这次讲了ddd的战术与战略的区别,战术帮我们优化局部,战略帮我们把握全局。
介绍了bounded context的这个概念以及实现的方式。那究竟如何能把一个系统分解成bounded context呢?之后的战略篇文章会进行说明。
网上发现了一张不错的图,总结了在ddd中,战略和战术都有那些概念。战略部分的概念之后会进行讲解。
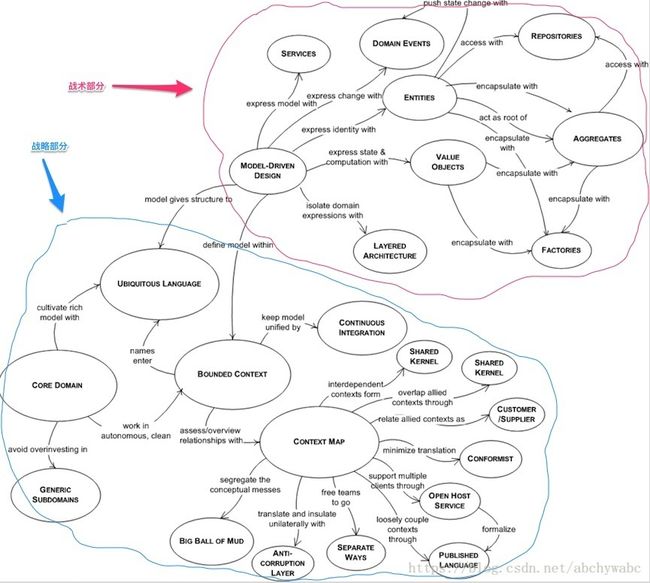
参考资料
BoundedContext