时间序列异常点检测
原文链接:Time Series Anomaly Detection Algorithms
时间序列异常检测--简单的语言介绍当前时间序列异常检测方法
在Statsbot,我们不断地回顾异常检测方法,并在此基础上改进我们的模型。
本文概述了目前最流行的时间序列异常检测算法及其优缺点。
这篇文章是写给没有经验的读者的,他们只是想了解一下异常检测技术的当前状态。不想用数学模型吓到你,我们把所有的数学都隐藏在推荐链接下。
重要异常类型
时间序列异常检测问题通常表述为寻找相对于某个标准或常用信号的异常数据点。虽然有许多异常类型,但我们将只关注从业务角度来看最重要的异常类型,例如意外的峰值、下降、趋势变化和水平转移。
想象一下,你在你的网站上跟踪用户,发现用户在短时间内出现了意想不到的增长,看起来就像一个峰值。这些类型的异常通常被称为加性异常。
网站的另一个例子是,当你的服务器宕机,你看到零或很低的用户数量在短时间内。这些类型的异常通常被归类为时间变化。
在这种情况下,你处理一些转换漏斗,可能有一个下降的转化率。如果发生这种情况,目标度量通常不会改变信号的形状,而是在一段时间内改变其总价值。这些类型的变化通常被称为水平移动或季节性水平移动,这取决于变化的特征。
基本上,一个异常检测算法要么在每个时间点上标记异常/非异常,要么预测某个时间点的信号,并测试这个时间点的值是否与预测值有足够的差异,从而将其视为异常。
使用第二种方法,您将能够可视化一个置信区间,这将有助于理解为什么会出现异常并验证它。

Statsbot的异常报告。实际时间序列、预测时间序列和置信区间有助于理解异常发生的原因。
让我们从应用的角度来回顾这两种算法类型,以找到各种类型的异常值。
STL分解
使用 STL 分解法将时间序列数据表示成三个要素:季节性、趋势、残差。通过分析残差的背离程度,引入一定的阈值,就可以作为预警依据了。我们可以使用绝对中位差来作为阈值,推特使用并开源了相关类库(链接)。这种方法的优点是简单,对峰值异常较敏感,并能结合滑动平均来检测周期性的异常。缺点是需要进行调参,且不能检测剧烈变动的指标。
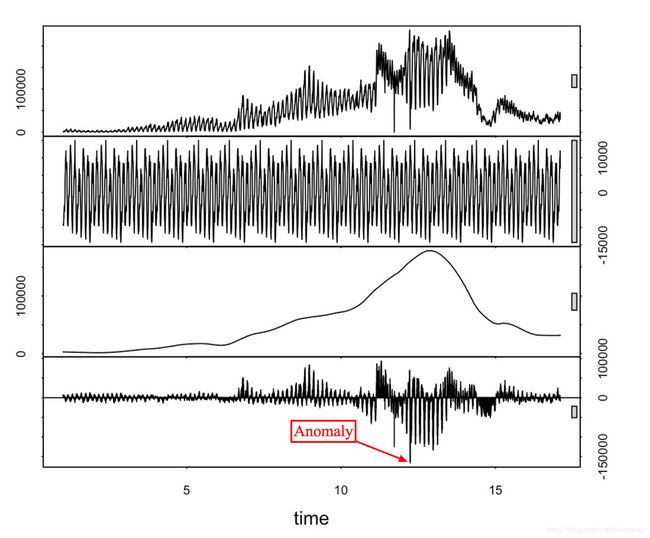
从上到下:利用STL分解检索原始时间序列、季节、趋势和残差部分。
顾名思义,它适用于季节性时间序列,这是最流行的情况。如果对残差进行分析并引入一定的阈值,就可以得到异常检测算法。
这里不明显的部分是,您应该使用中位数绝对偏差来获得更健壮的异常检测。
这种方法的主要实现是Twitter的异常检测库(R语言和python语言)。它使用广义的极端学生氏偏差测试来检查是否一个残差点是一个离群点。
优点
这种方法的优点在于它的简单性和健壮性。它可以处理许多不同的情况,并且所有的异常仍然可以直观地解释。
它主要用于检测加性异常值。为了检测电平变化,可以分析一些滚动平均信号而不是原始信号。
缺点
这种方法的缺点在于它在调整选项方面的僵化。你所能做的就是利用显著性水平来调整你的置信区间。
最典型的情况是信号的特性发生了巨大的变化。例如,您正在跟踪对公众关闭的网站上的用户,然后突然打开。在这种情况下,应该分别跟踪在启动期之前和之后出现的异常。
分类与回归树
分类和回归树是最健壮和最有效的机器学习技术之一。它还可以以多种方式应用于异常检测问题。
分类和回归树算法有两种使用方式:一种是准备好已标记过异常点的数据集,进行监督型的机器学习;另一种则是让 CART 算法自动寻找数据集中的模式,预测异常点的置信区间。最常用的开源库是 xgboost。这一方法可以用各种特征进行学习和预测,当然计算量也会因此上升。

实际时间序列(绿色),使用CART模型做出的预测时间序列(蓝色),以及检测到偏离预测时间序列的异常。
优点
这种方法的优点是它不受信号结构的任何约束,可以引入许多特征参数来执行学习并获得复杂的模型。
缺点
缺点是越来越多的特征会很快影响您的计算性能。在这种情况下,您应该有意识地选择特性
ARIMA
ARIMA是一种设计非常简单的方法,但仍然足够强大,可以预测信号并发现异常。它基于一个方法,从过去的几个点产生下一个点的预测加上一些随机变量,通常是白噪声。可以想象,未来的预测点会产生新的点,等等。它对预测范围的明显影响是:信号变得更平滑。使用这种方法的困难之处在于,您应该选择差异的数量、自回归的数量和预测误差系数。
每次处理一个新信号时,都应该构建一个新的ARIMA模型。
另一个障碍是,你的信号应该是平稳的差分后。简单来说,它意味着你的信号不应该依赖于时间,这是一个重要的限制。
异常检测是利用离群点建立调整后的信号模型,利用t统计量检验模型的拟合是否优于原始模型。

利用原始的ARIMA模型建立了两个时间序列,并对离群值ARIMA模型进行了调整。
这种方法的最佳实现是tsoutliers R包。它适用于检测所有类型的异常情况下,你可以找到一个合适的ARIMA模型为您的信号。
指数平滑法
指数平滑技术与ARIMA方法非常相似。基本的指数模型相当于ARIMA(0,1,1)模型。
从异常探测的角度来看,最有意思的方法是冬季季节法。你应该定义你的季节周期,它可以等于一个星期,一个月,一年,等等。
如果您需要跟踪几个季节周期,例如同时具有周和年依赖项,则应该只选择一个。通常,它是最短的:在这个例子中是一周。
这显然是这种方法的一个缺点
神经网络
和CART一样,有两种方法可以应用神经网络:监督学习和非监督学习。
当我们处理时间序列时,最合适的神经网络类型是LSTM。这种类型的递归神经网络,如果正确地构建,将允许您在您的时间序列中建模最复杂的依赖关系,以及高级的季节性依赖关系。
如果有多个时间序列相互耦合,这种方法也非常有用。
这方面的研究仍在进行中,需要做大量的工作来建立时间序列的模型。
记住
尝试最适合您的问题的最简单的模型和算法。
如果不成功,就使用更先进的技术。
从覆盖所有情况的更通用的解决方案开始是一个诱人的选择,但它并不总是最好的。
在Statsbot中,为了在规模上检测异常,我们使用不同的技术组合,从STL开始,到CART和LSTM模型结束。