前端性能优化实践
1、背景
网站前端的用户体验决定了用户是否想要去使用网站的功能,而网站的功能决定了用户是否会一票否决前端体验。 不仅仅如此,如果前端优化得好,他不仅可以为企业节约成本,因为增强的用户体验,他还能给用户带来更多的用户。
2、前言
从输入 URL 到页面加载完成,发生了什么?
我们现在站在性能优化的角度,一起简单地复习一遍这个经典的过程:首先我们需要通过 DNS(域名解析系统)将 URL 解析为对应的 IP 地址,然后与这个 IP 地址确定的那台服务器建立起 TCP 网络连接,随后我们向服务端抛出我们的 HTTP 请求,服务端处理完我们的请求之后,把目标数据放在 HTTP 响应里返回给客户端,拿到响应数据的浏览器就可以开始走一个渲染的流程。渲染完毕,页面便呈现给了用户,并时刻等待响应用户的操作。
我们将这个过程切分为如下的过程片段:
- DNS 解析
- TCP 连接
- HTTP 请求抛出
- 服务端处理请求,HTTP 响应返回
- 浏览器拿到响应数据,解析响应内容,把解析的结果展示给用户
本文基于词典的一个长期项目出发,针对这个过程,从多角度进行了性能优化尝试,做此总结。
3、网络篇
3.1、网络连接优化
3.1.1、TCP影响性能
我们都知道,http1.1所实现的长连接,到http2实现的多路复用,已经极大的提升了网络连接的性能,但TCP因其特点,仍为严重制约前端性能的一大因素。
- 三次握手
- 流量控制
- 慢启动
三次握手的步骤:
- SYN。客户端选择一个随机序列号 x,并发送一个 SYN 分组,其中可能还包括其他 TCP 标志和选项。
- SYN ACK。服务器给 x 加 1,并选择自己的一个随机序列号 y,追加自己的标志和选项,然后返回响应。
- ACK。客户端给 x 和 y 加 1 并发送握手期间的最后一个 ACK 分组
三次握手带来的延迟使得每创建一个新 TCP 连接都要付出很大代价,而这也决定了提高 TCP 应用性能的关键,在于想办法重用连接。
流量控制是一种预防发送端过多向接收端发送数据的机制。否则,接收端可能因为忙碌、负载重或缓冲区既定而无法处理。为实现流量控制, TCP 连接的每一方都要通告自己的接收窗口(rwnd),其中包含能够保存数据的缓冲区空间大小信息。
服务器通过 TCP连接初始化一个新的拥塞窗口变量,将其值设置为一个系统设定的保守值。客户端与服务器之间最大可以传输(未经 ACK 确认的)数据量取 rwnd 和 cwnd 变量中的最小值。然后在分组被确认后增大窗口大小。
慢启动中的“慢”指的不是窗口增长的速度慢,而是因为要增长到适合当前带宽的窗口大小,需要多次 TCP 通信往返,这个过程带来了较大的时间消耗。
综合来看,我们可以总结出TCP制约性能的关键:
- TCP 三次握手增加了整整一次往返时间
- TCP 慢启动将被应用到每个新连接
- TCP 流量及拥塞控制会影响所有连接的吞吐量
3.1.2、优化点–QUIC协议传输
QUIC 全称 Quick UDP Internet Connection, 是Google制定的一种基于 UDP 协议的低时延互联网应用层协议
- 0 RTT建立连接。如果一对使用QUIC进行加密通信的双方此前从来没有通信过,0RTT是不可能的。所以第一次C和S建连还是会走正常的tls握手流程,但过了一会儿或者一段时间后,C又想和S通信,此时C已经有了刚刚和S协商出来的密钥(可能是存在内存or外存)。C就会利用刚刚的密钥K1来和S加密首次数据,在第二个RTT期间,S会和C协商出新的密钥K2,作为接下来的通信密钥。
- 基于UDP,解决了慢启动和流量控制的问题
- 基于UDP,各个请求之间相互独立,比如 请求2 丢了一个 Pakcet,不会影响 请求3 和 请求4,不存在 TCP 队头阻塞
从项目效果来看,弱网环境的时候能够提升 20% 以上的访问速度。
频繁切换网络的情况下,不会断线,不需要重连,用户无任何感知。
3.2、缓存
所谓缓存,即致力于解决二次访问速度的问题,通过对资源的存储,达到提升第二次访问速度的目的。目前的缓存类型有如下几种:
- HTTP缓存。Cache-Control、expires 等字段控制的缓存。
- Service Worker离线缓存。Service Worker 是一种独立于主线程之外的 Javascript 线程。
- Memory缓存。存在内存中的缓存。从优先级上来说,它是浏览器最先尝试去命中的一种缓存。Base64 格式的图片,几乎永远可以被塞进 memory cache
- PUSH缓存。浏览器只有在 Memory Cache、HTTP Cache 和 Service Worker Cache 均未命中的情况下才会去询问 Push Cache。Push Cache 是一种存在于会话阶段的缓存,当 session 终止时,缓存也随之释放。
我们一般用的比较多的是HTTP缓存,但是HTTP缓存受服务端控制,仍然有很多的制约性。本次项目采用了Service Worker的方式进行缓存。
3.2.1、优化点–Service Worker缓存
Service Worker是一种Web Worker。它本质上是一个与主浏览器线程分开运行的 JavaScript 文件,可以拦截网络请求、缓存资源或从缓存中检索资源、传递推送消息。
当应用程序处于没有活动状态时,Service Worker 可以从服务器接收推送消息。这可以让您的应用程序向用户显示推送通知,即使它未在浏览器中打开。
与HTTP缓存相比,Service Worker有如下特点:
- 精细化控制浏览器缓存,不依赖服务端
- 提前缓存未访问页面的资源,加快访问速度
具体实现:
利用workBox,在webpack打包的时候自动生成Service Worker文件。
new WorkBoxPlugin.GenerateSW({
cacheId: 'webpack-pwa', // 设置前缀
skipWaiting: true, // 强制等待中的 Service Worker 被激活
clientsClaim: true, // Service Worker 被激活后使其立即获得页面控制权
swDest: 'service-wroker.js', // 输出 Service worker 文件
globPatterns: ['**/*.{html,js,css,png.jpg}'], // 匹配的文件
globIgnores: ['service-wroker.js'], // 忽略的文件
runtimeCaching: [
// 配置路由请求缓存
{
urlPattern: /.*\.js/, // 匹配文件
handler: 'networkFirst' // 网络优先
}
]
})
在index.html中加入
<script>
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker
.register('./service-worker.js')
.then(registration => {
console.log('SW registered: ', registration);
})
.catch(registrationError => {
console.log('SW registration failed: ', registrationError);
});
});
}
</script>
注意: service worker仅支持https域名的缓存
3.3、其他
3.3.1、DNS预解析
dns-prefetch是与页面加载是并行处理的,且不用影响到页面加载的性能。
3.3.2、巧用CDN
同一个域名下的请求会不分青红皂白地携带 Cookie,而静态资源往往并不需要 Cookie 携带什么认证信息。把静态资源和主页面置于不同的域名下,完美地避免了不必要的 Cookie 的出现。
3.3.3、构建结果体积优化
webpack-bundle-analyzer,配置方法和普通的 plugin 无异,它会以矩形树图的形式将包内各个模块的大小和依赖关系呈现出来。
3.3.4、SERVER PUSH
服务端接收到客户端主请求,能够“预测”主请求的依赖资源,在响应主请求的同时,主动并发推送依赖资源至客户端。客户端解析主请求响应后,可以”无延时”从本地缓存获取依赖资源, 减少访问延时, 提高访问体验,也加大了链路的并发能力。
采用服务端推送的功能,则JS/CSS资源基本可以和HTML资源同步到达,浏览器可以“无延时”获取JS/CSS资源,客户端的延时最多可以减少一个RTT。
4、渲染篇
上面介绍的一系列缓存,主要是解决第二次访问性能的问题,对于新用户来说,第一次访问网站的速度决定了回访率,因此首屏加载需要重点处理。
4.1、图片加载优化
4.1.1、WebP图片
WebP是一种支持有损压缩和无损压缩的图片文件格式,根据Google的测试,无损压缩后的WebP比PNG文件少了26%的体积,有损压缩后的WebP图片相比于等效质量指标的JPEG图片减少了25%~34%的体积。
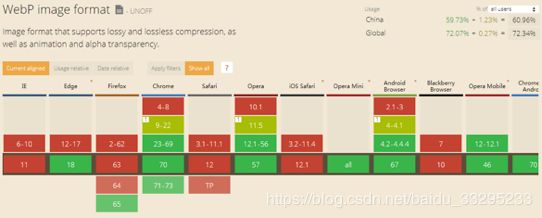
谷歌全面支持、安卓浏览器从4.2开始支持。那么在页面中对于安卓用户中图片资源加载大小会有大幅度下降。
打开淘宝–前端标杆,可以看到淘宝针对大量的图片详情图片采用了webp格式的图片,该图片因其体积小的特性,使得网站加载速度明显提升。
项目中一开始使用的是png格式的图片,图片信息如下:

可以看到图片大小达到了300多kb,这显然不利于首屏的加载,当换成webp格式后,
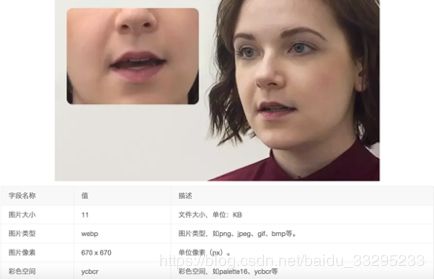
图片大小只有11kb,如此小的体积,并且图片并没有失真或者模糊,因此,webp格式必然会成为未来的主流。
那前端如何判断浏览器是否支持webp格式呢?非常简单!主要方法有两种,一种是利用canvas绘制来判断,一种是利用img对象来加载一个1px的webp图片。核心代码分别如下:
方式一:
document.createElement('canvas').toDataURL('image/webp').indexOf('data:image/webp') == 0
方式二:
window.isSupportWebp = false;//是否支持
(function() {
var img = new Image();
function getResult(event) {
//如果进入加载且图片宽度为1(通过图片宽度值判断图片是否可以显示)
window.isSupportWebp = event && event.type === 'load' ? img.width == 1 : false;
}
img.onerror = getResult;
img.onload = getResult;
img.src = 'data:image/webp;base64,UklGRiQAAABXRUJQVlA4IBgAAAAwAQCdASoBAAEAAwA0JaQAA3AA/vuUAAA='; //一像素图片
})();
4.1.2、图片预加载与懒加载
图片预加载,即图片提前加载,可以保证图片快速、无缝的发布,用户需要查看时可直接从本地缓存中渲染。
image对象实现预加载:
var images = new Array()
function preload() {
for (i=0;i<preload.arguments.length;i++){
images[i] = new Image()
images[i].src = preload.arguments[i]
}
}
背景图片实现预加载:
#preload-01 { background: url(http://domain.tld/image-01.png) no-repeat -9999px -9999px; }
#preload-02 { background: url(http://domain.tld/image-01.png) no-repeat -9999px -9999px; }
懒加载:当图片出现在可视区域内时再加载。
思路:将页面里所有img属性src属性用data-xx代替,当页面滚动直至此图片出现在可视区域时,用js取到该图片的data-xx的值赋给src。
// 获取所有的图片标签
const imgs = document.getElementsByTagName('img')
// 获取可视区域的高度
const viewHeight = window.innerHeight || document.documentElement.clientHeight
// num用于统计当前显示到了哪一张图片,避免每次都从第一张图片开始检查是否露出
let num = 0
function lazyload(){
for(let i=num; i<imgs.length; i++) {
// 用可视区域高度减去元素顶部距离可视区域顶部的高度
let distance = viewHeight - imgs[i].getBoundingClientRect().top
// 如果可视区域高度大于等于元素顶部距离可视区域顶部的高度,说明元素露出
if(distance >= 0 ){
// 给元素写入真实的src,展示图片
imgs[i].src = imgs[i].getAttribute('data-src')
// 前i张图片已经加载完毕,下次从第i+1张开始检查是否露出
num = i + 1
}
}
}
// 监听Scroll事件
window.addEventListener('scroll', lazyload, false);
4.2、骨架屏与预渲染
移动端白屏是前端体验优化的一个重要方向,web前端诞生了多种优化方案。
| CSR | 预渲染 | SSR | 同构 | |
|---|---|---|---|---|
| 优点 | 不依赖数据 | FCP比CSR快 | SEO友好,首屏渲染性能高 | SEO友好,首屏性能高,内存数据共享 |
| 缺点 | FCP慢 | SEO不友好 | 模板维护成本高,更多的服务器负载 | node成为瓶颈 |
FP表示页面只有根节点,FCP表示渲染出基本结构,FMP表示页面渲染完毕
通过对比,可以看到同构集合了CSR和SSR的优点,可以适用于大部分场景。但由于在同构方案中,node中间层处于核心位置,那么面对词典的几百万的访问量,系统可用性的瓶颈就极大的依赖于node,一旦作为短板的node挂掉,会导致整个服务不可用。
为了保障在系统稳定的前提下又要优化用户体验,本文采用了预渲染的方式。
prerender-spa-plugin是一个基于 webpack 的插件,对于使用者可以很简单的将通过 webpack 构建的网站或单页面应用进行预编译,生成预渲染文件。
生成的代码大致为:
可以看到,预渲染或者骨架屏都是生成了一部分静态html代码,并插入根节点,当真实的页面渲染完后,再进行替换。
5、打包篇
5.1、代码分割
对于前端资源来说,文件体积过大是很影响性能的一项。特别是对于移动端的设备而言简直是灾难。
此外对于某些只要特定环境下才需要的代码,一开始就加载进来显然也不那么合理,这就引出了按需加载的概念了。
为了解决这些情况,代码拆分就应运而生了。代码拆分故名思意就是将大的文件按不同粒度拆分,以满足解决生成文件体积过大、按需加载等需求。
SplitChunksPlugin是webpack4中官方plugin,用于做分包打包的,可以帮你把重复引入的模块按规则打包到指定的js里面。以下是SplitChunksPlugin的默认配置:
splitChunks: {
chunks: "async", //在默认情况下,SplitChunksPlugin 仅仅影响按需加载的代码块,如果需要对同步的代码做代码分割打包,那么chunk配置为'all'
minSize: 30000, // 模块的最小体积
minChunks: 1, // 模块的最小被引用次数
maxAsyncRequests: 5, // 按需加载的最大并行请求数
maxInitialRequests: 3, // 一个入口最大并行请求数
automaticNameDelimiter: '~', // 文件名的连接符
name: true,
cacheGroups: { // 缓存组
vendors: { //引入的node modules里面的库打包成一个vendor
test: /[\\/]node_modules[\\/]/,
priority: -10
},
default: { //其他重复的模块,如业务组件、自定义公共组件等
minChunks: 2,
priority: -20,
reuseExistingChunk: true
}
}
}
在没有做代码分割之前,可以看到由于公共库重复引入,导致整体打包体积过大。

使用默认打包后,代码整体体积大大降低。

由于本项目为多入口项目,我们按SplitChunksPlugin的基础配置,在webpack.config.js里面引入,以~连接的chunk就是SplitChunksPlugin使用基础的配置给我们拆包出来的文件,这时我们的页面是不能正常加载的,因为这些拆包出来的chunk不能自动地注入到所引用的入口页里,我们将其做下统一,将这部分代码分割到common里,配置如下:
splitChunks: {
chunks: 'all',
name: true,
cacheGroups: {
vendors: { // 项目引用的三方库,如mobx等
chunks: 'all',
test: /node_modules/,
priority: 100,
name: 'vendors',
},
commons: { // 其他同步加载公共包,如自定义组件等
chunks: 'all',
minChunks: 3, //最小引用次数修改为3,那么app.js和其他入口页共用的模块就不会被打包进来,而是只打包了引用次数超过三次的一些自定义组件
name: 'commons',
priority: 80,
},
default: false //注意把cacheGroups的默认的default设置为false,不然还是会走default里面的配置,将引用了两次以上的模块进行打包
}
}
打包结果如下:
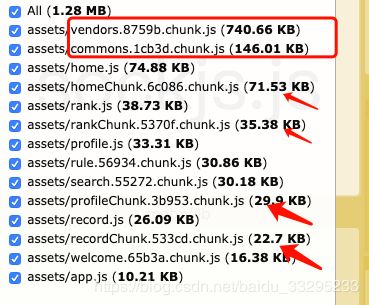
SplitChunksPlugin虽然好用,但是也不要盲目地使用,应该根据项目的具体情况而定,一般如果是单入口页面,就直接按默认配置即可;多入口页的话,可以根据具体情况再进行拆包,自己写cacheGroups的配置的时候注意要关闭或者覆盖默认配置。
5.2、异步代码

常规同步代码写法造成加载大量未在首屏使用的代码,异步代码提升首屏加载时间。
方式:将点击事件这类业务逻辑异步加载,并且利用上import的语法糖,在浏览器空闲时间预加载。

5.3、webpack-dll-plugin 与 Externals对比
我们项目中常见的 React 全家桶,亦或是用到的一些工具库,比如 lodash 等等,我们不希望这些依赖被集成进每一次构建逻辑中,因为它们真的太少时候会被变更了,所以每次的构建的输入输出都应该是相同的。因此,我们会设法将这些静态依赖从每一次的构建逻辑中抽离出去,以提升我们每次构建的构建效率。常见的方案有两种,一种是使用 webpack-dll-plugin 的方式,在首次构建时候就将这些静态依赖单独打包,后续只需要引用这个早就被打好的静态依赖包即可,有点类似“预编译”的概念;另一种,也是业内常见的 Externals的方式,我们将这些不需要打包的静态资源从构建逻辑中剔除出去,而使用 CDN 的方式,去引用它们。
本文采用了externals的方式,webpack-dll-plugin缺点如下:
- 需要配置在每次构建时都不参与编译的静态依赖,并在首次构建时为它们预编译出一份 JS 文件(后文将称其为 lib 文件),每次更新依赖需要手动进行维护,一旦增删依赖或者变更资源版本忘记更新,就会出现 Error 或者版本错误。
- 将所有资源预编译成一份文件,并将这份文件显式注入项目构建的 HTML 模板中,这样的做法,在 HTTP1 时代是被推崇的,因为那样能减少资源的请求数量,但在 HTTP2 时代如果拆成多个 CDN Link,就能够更充分地利用 HTTP2 的多路复用特性。
6、总结
以上为本次项目所做的一些性能优化,可以看到,性能优化没有一个固定的方案,需要我们根据项目实际情况进行考虑。性能优化实在是前端知识树中特别的一环——当你需要学习前端框架时,文档和源码几乎可以告诉你所有问题的答案,当你需要学习 Git 时,你也可以找到放之四海皆准的实践方案。但性能优化却不一样,它好像只能是一个摸索的过程。
相对于模式成熟、方案完善的服务端性能优化来说,前端性能优化整体的起步是比较晚的。但在当今的大环境下,它又是极其重要的一个工作。我们是离用户最近的工程师,需要直接对用户的体验负责。因此,我们需要做的努力还有太多太多。希望我们任何一个用户端的产品,都需要把输入url访问页面的过程滴水不漏地考虑到自己的性能优化方案内、反复权衡,从而打磨出用户满意的速度。
参考文档:
- (Webpack优化–将你的构建效率提速翻倍)[https://juejin.im/post/5d614dc96fb9a06ae3726b3e]
- (前端性能优化–掘金小册)[https://juejin.im/book/5b936540f265da0a9624b04b/section/5b936540f265da0aec223b5d]