CUDA编程 原子操作atomicAdd对双精度浮点数double的重载
在设计CUDA并行程序的时候遇到的一个问题:并发线程每一个线程都需要对同一块内存中的值进行修改,由于并发的线程运行时间的不确定性,如果不对访存加以控制,将会导致计算得到的结果不正确。下面举个例子(我在项目中遇到的问题和该例子很类似)
举个栗子
甲乙两个线程运行到12:00的时候同时(也可以有些许先后)对同一块内存地址进行了读取操作,读到的数值是相同的,都是10,甲线程动作很快,把该值加上2之后又将新值(10+2=12)重新写入内存原地址中(12:01写入);而乙线程稍微做了一些其他操作之后,把该值加上5之后也把结果(10+5=15)写入原地址(12:03写入)。完成这波操作之后内存的值变为了15,而我们预期的结果应该是(10+2+5 = )17才对,计算结果出错。这就是不加控制的并发访存操作会导致的问题。
解决方法
要解决这个问题,可以使用的方法有
- 互斥锁
- 原子操作
- 同步等等
互斥锁顾名思义就是给内存加上锁,每一个线程访问时就给内存上锁,其他线程要来使用时,发现内存被上锁了,只能排队等待,等前一个线程使用结束,开锁之后才能使用
原子操作跟互斥锁的方法很像,不过对象不一样,互斥锁是对内操作锁,而原子操作是使运行语句具有原子性,整个流程是一体的,不能被其他线程拆解开。应用在上面的例子里就是使读数据,处理数据,写数据成为完整地一步操作,期间不会发生线程切换。该方法也能很好的防止内存访问混乱。
在CUDA遇到的难题
CUDA为我们提供了原子函数的工具,其中就有atomicAdd函数,可以解决以上例子中的问题。详见官方文档
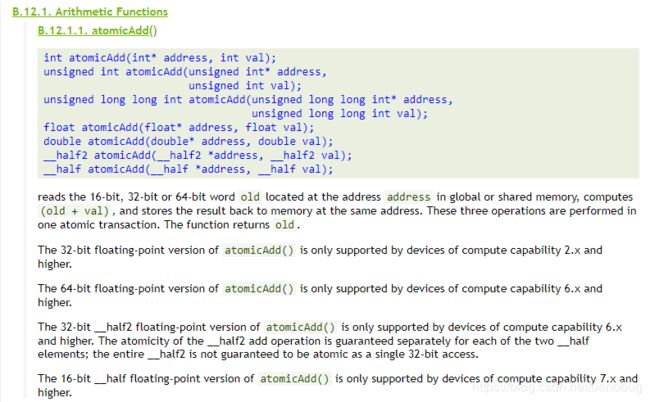
提供给我们的重载还很丰富呢!不过注意到没有(倒数第三段),对双精度浮点型double的重载只支持计算能力大于或等于6.0的设备,很不巧的是,我的设备的计算能力仅仅只有3.5,而我恰巧要用到的就是重载double的版本(心累,知道程序员为什么容易秃了T.T)。
不过好心的设计师们还是给我们留了后路,把文档往上翻可以看到下图所示的内容
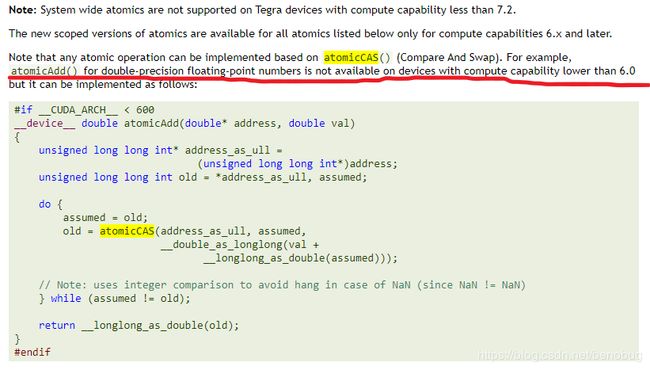
可真是福音啊!(划红线的部分下一句)简单翻译就是:虽然有些设备不能使用自带的重载double的atomicAdd,但可以用以下方法自己实现(真的是硬件不行,软件来凑啊!)
#if __CUDA_ARCH__ < 600
__device__ double atomicAdd(double* address, double val)
{
unsigned long long int* address_as_ull =
(unsigned long long int*)address;
unsigned long long int old = *address_as_ull, assumed;
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed,
__double_as_longlong(val +
__longlong_as_double(assumed)));
// Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN)
} while (assumed != old);
return __longlong_as_double(old);
}
#endif
这里用到了另一个特别的原子操作函数automicCAS,它的功能如下
读取位于全局或共享存储器中地址address 处的32 位或64 位字old,计算 (old == compare ? val : old),并将结果存储在存储器的同一地址中。这三项操作在一次原子事务中执行。该函数将返回old(比较并交换)。
所以CAS返回当前address的值,如果这个和原来读出的不一样,表示在中间 address已经被修改了,ival就不会被写入。这种情况下要重新做加法,再尝试CAS。
因此就不难理解为什么能用这个函数来实现atomicAdd了吧!
解决报错问题
在实际运用时,如果直接把官方给的代码直接拷贝进程序里,运行时还是会报错,它会一直提示重复定义标识符
error: function “atomicAdd(double *, double)” has already been defined
解决的方法是把预编译指令改为如下
#if !define (__CUDA_ARCH__) || __CUDA_ARCH__ >= 600
#else
__device__ double atomicAdd(double* address, double val)
{
unsigned long long int* address_as_ull =
(unsigned long long int*)address;
unsigned long long int old = *address_as_ull, assumed;
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed,
__double_as_longlong(val +
__longlong_as_double(assumed)));
// Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN)
} while (assumed != old);
return __longlong_as_double(old);
}
#endif