solr5.4.0
应用场景
在百度中搜索“阿凡达”会出来一系列资料,有文本,图片,电影,链接等等,这就是一个搜索引擎实现的,当然百度有自己的搜索引擎,我们可以不用自己写一个搜索引擎,有现成的比如sorl,lucene,ElasticSearch等等,这里介绍一些solr。
1.概述
1.1 Solr 是什么?
Solr它是一种开放源码的、基于 Lucene Java 的搜索服务器,易于加入到 Web 应用程序中。Solr提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式)。它易于安装和配置,而且附带了一个基于HTTP 的管理界面。可以使用 Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。
- Solr的特性包括:
-
高级的全文搜索功能
专为高通量的网络流量进行的优化
基于开放接口(XML和HTTP)的标准
综合的HTML管理界面
可伸缩性-能够有效地复制到另外一个Solr搜索服务器
使用XML配置达到灵活性和适配性
可扩展的插件体系
1.2 Lucene 是什么?
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene目前是 Apache Jakarta(雅加达) 家族中的一个开源项目。也是目前最为流行的基于Java开源全文检索工具包。目前已经有很多应用程序的搜索功能是基于Lucene ,比如Eclipse 帮助系统的搜索功能。Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。
1.3 Solr vs Lucene
Solr与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene,因为Solr底层的核心技术是使用Lucene 来实现的,Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括 Solr: Solr是Lucene面向企业搜索应用的扩展。
Solr与Lucene架构图:

Solr使用Lucene并且扩展了它!
- 一个真正的拥有动态字段(Dynamic Field)和唯一键(Unique Key)的数据模式(Data Schema)
- 对Lucene查询语言的强大扩展!
- 支持对结果进行动态的分组和过滤
- 高级的,可配置的文本分析
- 高度可配置和可扩展的缓存机制
- 性能优化
- 支持通过XML进行外部配置
- 拥有一个管理界面
- 可监控的日志
- 支持高速增量式更新(Fast incremental Updates)和快照发布(Snapshot Distribution)
1.4 总结
Lucene是一个全文检索的工具包,它是一堆jar包,不能单独运行,即不能独立对外提供服务。
Solr是一个全文搜索服务器,它可以独立运行,它能独立对外提供搜索和索引服务。
使用lucene开发站内搜索的话,程序员编写的代码量会比较大,而且在搜索和索引流程得考虑他的性能。
使用solr开发站内搜索的话,程序员只需编写少量的代码,快速的搭建出来站内搜索功能。而且性能方面不需要程序员去考虑,solr对它已经进行了处理。
下图展示了solr的使用组织结构:
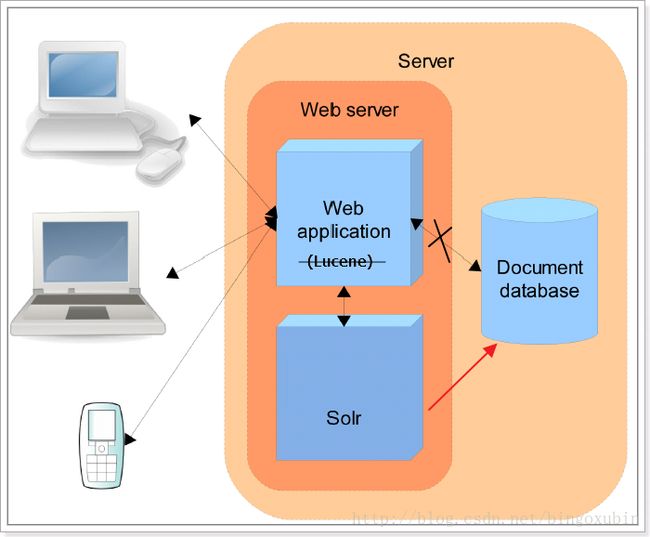
Solr也是Apache下一个项目,它是使用java开发的,它是基于Lucene的全文搜索服务器。
Solr如何进行索引和搜索:
索引:客户端(可以是浏览器可以是java程序)发送post请求到solr服务器,发给solr服务器一个文档(xml、json),就可以进行一个添加索引删除索引、修改索引的操作。
搜索:客户端(可以是浏览器可以是java程序)发送get请求到solr服务器,请求solr服务器给它响应一个结果文档(xml、json),程序员拿到这些文档就可以对其进行解析。进行视图渲染。
2. 系统信息及材料准备
2.1 系统信息
- 宿主机操作系统:windows 7+8G
- 宿主机ip:192.168.117.66
- 虚拟机版本:VMware® Workstation 11.0.0 build-2305329
- 操作系统:CentOS-6.6-x86_64
- JDK版本:jdk-7u79-linux-x64
- Tomcat版本:tomcat7.0.67
- Solr版本:solr5.4.0
- 虚拟机ip:192.168.199.23
- 虚拟机名:solr5
2.2 资源下载
2.2.1 jdk1.7下载
下载链接
进入链接后,选中Accept License Agreement,下载jdk-7u79-linux-x64.tar.gz。

2.2.2 tomcat7下载
下载链接
2.2.3 solr5.4.0下载
下载链接 进入solr5.4.0文件夹。
这样,我们所需要的solr环境搭建的组件都下载完毕了,下面着手安装与配置!
3. Solr单机版搭建
3.1 JDK安装
1. 卸载原有JDK
# yum remove java

2.将下载的JDK安装包,拷贝到【/usr/java】目录下,进行解压缩,把解压缩后的文件夹名改为jdk1.7。
# cd /usr/java
# tar -xzvf jdk-7u79-linux-x64.tar.gz
3. 修改profile配置文件。
# vim /etc/profile
4.在末尾加上如下3行配置:
export JAVA_HOME=/usr/java/jdk1.7
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH

5. 使修改的配置文件生效:
# source /etc/profile
6. 验证:
# java -version

3.2 Tomcat安装
上传apache-tomcat-7.0.67.tar.gz到服务器的【/usr/local/solr/】目录下并解压重命名为tomcat7,使用命令给tomcat的bin目录下的脚本赋予可执行权限。

# chmod 777 /usr/local/solr/tomcat7/bin/*
3.3 Solr安装
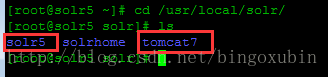
将solr-5.4.0.tgz下载下来,上传到服务器的【/usr/local/solr/】目录下并重命名为sorl5,此时【/usr/local/solr/】目录下应该存在两个文件夹,tomcat7和solr5。
3.4 Solr配置
- 将【/usr/local/solr/solr5/server/solr-webapp】目录下的webapp文件夹拷贝到【/usr/local/solr/tomcat7/webapps】目录下,并修改文件夹名称为solr。
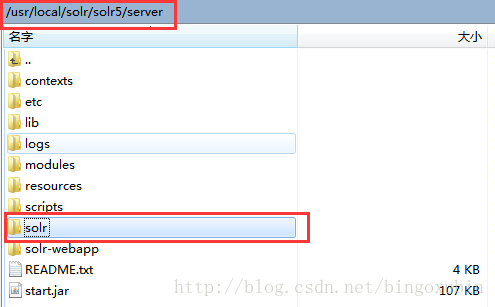
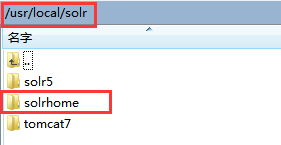
- 复制【/usr/local/solr/solr5/server/】目录下的solr文件夹,到【/usr/local/solr/】目录下,并改名为solrhome。
- 修改【/usr/local/solr/tomcat7/webapps/solr/WEB-INF/web.xml】文件:
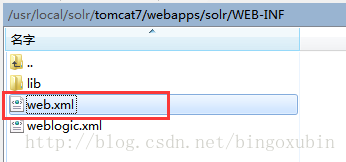
打开web.xml,修改内容为:(注:如果是windows,地址为绝对路径,如D:/solr/solrhome,不必用windows下的反斜线)
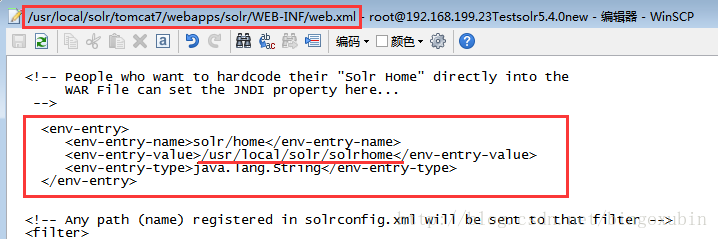
solr/home
/usr/local/solr/solrhome
java.lang.String
- 复制【/usr/local/solr/solr5/server/lib/ext】下的所有jar包【/usr/local/solr/tomcat7/webapps/solr/WEB-INF/lib】目录中。
命令如下:
# cp -r /usr/local/solr/solr5/server//lib/ext/* /usr/local/solr/tomcat7/webapps/solr/WEB-INF/lib/
- 在【/usr/local/solr/tomcat7/webapps/solr/Web-INF】目录下创建文件夹classes,复制【/usr/local/solr/solr5/server/resources/log4j.properties】文件到【/usr/local/solr/tomcat7/webapps/solr/WEB-INF/classes】目录下。
命令如下:
# cp -r /usr/local/solr/solr5/server/resources/log4j.properties /usr/local/solr/tomcat7/webapps/solr/WEB-INF/classes/
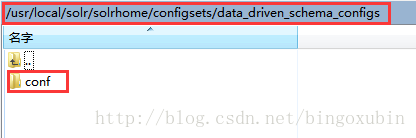
- 在【/usr/local/solr/solrhome/】目录下,创建solrcore,取名为collection1,将【/usr/local/solr/solrhome/configsets/data_driven_schema_configs】目录下的conf文件夹全部复制到【/usr/local/solr/solrhome/collection1】目录下。

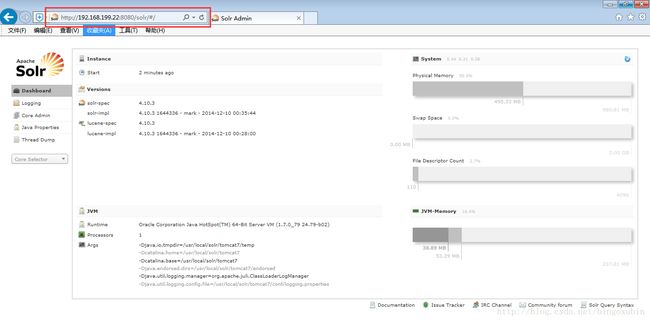
- 启动tomcat,访问http://192.168.199.23:8080/solr/admin.html即可。
注:这里如果访问地址为http://192.168.199.23:8080/solr会报404的错误,需要在地址后面加上admin.html,这是solr5特有的,千万注意。
4. Solr详解
4.1 SolrCore
4.1.1 SolrHome和SolrCore
SolrHome是Solr运行的主目录,该目录中包括了多个SolrCore目录。SolrCore目录中包含了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore。
一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
4.1.2目录结构
SolrHome目录:

SolrCore目录:
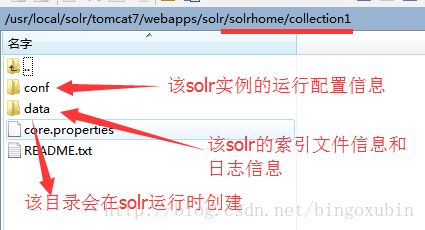
4.1.3创建SolrCore
创建SolrCore先要创建SolrHome。在solr解压包下solr5/server/solr文件夹就是一个标准的SolrHome。
- 拷贝solr5解压包下solr5/server/solr文件夹。
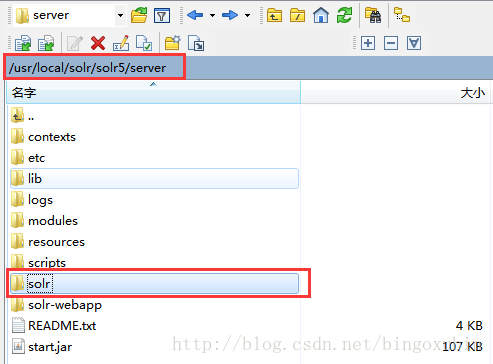
- 复制该文件夹到本地的一个目录,把文件名称改为solrhome。
注:改名不是必须的,只是为了便于理解。
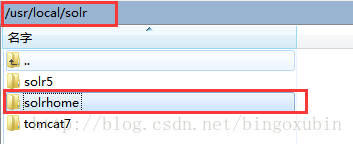
- 打开SolrHome目录
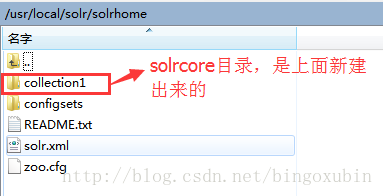
- SolrCore创建成功。
4.1.4多solrcore配置
配置多SolrCore的好处:
- 一个solr工程对外通过SorlCore提供服务,每个SolrCore相当于一个数据库,这个功能就相当于一个mysql可以运行多个数据库。
- 将索引数据分SolrCore存储,方便对索引数据管理维护。
- SolrCloud集群需要使用多core。
复制原来的core目录为collection2,目录结构如下:
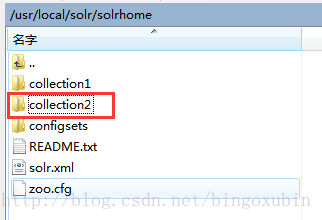
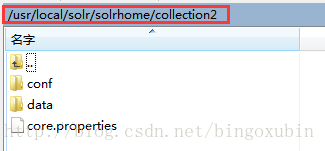
修改collection2下的core.properties,如下:
![]()
演示多core的使用,在collection1和collection2中分别创建索引、搜索索引,可以自己尝试。
5. 配置分词器
Solr自带的分词器并不能很好的满足我们的实际业务需求,比如对中文的分词支持的不够完善,如下:

可以看到当输入一个经典的例子语句”乒乓球拍卖完了”的时候分词效果是将每个文字都拆分开了,这样在最后用户检索的时候会服务器会响应大量的垃圾信息,用户体验大大下降。所以我配置自己的分词器。具体步骤如下:
所需jar包以及配置文件下载地址
- 将上面提供的后面4个jar包,上传到【/usr/local/solr/tomcat7/webapps/solr/WEB-INF/lib/】下。
- 把上面提供的2个文件,上传到【/usr/local/solr/tomcat7/webapps/solr/WEB-INF/classes/】目录下。
- 修改:/usr/local/solr/solrhome/collection1/conf/managed-schema,添加如下配置:

然后重启tomcat,在analysis中选择text_ik,输入一段中文,查看分词效果。
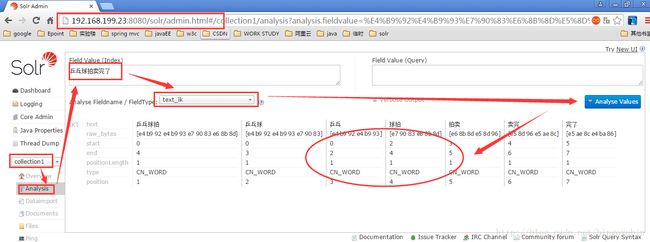
可以看到分词效果明细提升,如果有其他业务需要也可以继续对IK的词库进行相应的扩充。