【论文解读 ArXiv 2019 | HAHE】Hierarchical Attentive Heterogeneous Information Network Embedding

论文链接:https://arxiv.org/abs/1902.01475
代码链接:https://github.com/zhoushengisnoob/HAHE
来源:ArXiv 2019
文章目录
- 1 摘要
- 2 介绍
- 2.1 现有方法的不足
- 2.2 作者提出
- 2.3 贡献
- 3 HAHE模型
- 3.1 Path instance attention layer
- 3.2 Meta path attention layer
- 3.3 损失函数
- 4 实验
- 5 总结
1 摘要
HIN中不同的元路径有不同的语义信息,现有的工作都是对于所有节点,为元路径(meta paths)分配相同的权重,忽视了不同类型的节点在不同的元路径上的个性的特征。
而且现有的工作不能充分发掘出,反应节点在语义空间中的偏好信息的路径实例(path instances)之间的不同。
为解决上述问题,本文提出HAHE模型(Hierarchical Attentive Heterogeneous information network Embedding),分别在meta paths和path instances的语义空间,捕获到节点个性化的偏好信息(personalized preferences)。
因为path instances是基于meta path的,所以可用一个分层注意力机制,来建模meta paths和path instances上的个性化偏好。
2 介绍
2.1 现有方法的不足
首先,现有的方法要不就是不区分meta paths,要不就是对于所有节点,为meta paths赋予相同的权重。这样的话,节点在meta paths中的个性化信息不能被获取到,也不能充分获取到节点间的相似性(proximity)信息。
以HIN中的朋友推荐为例,有的用户可能想关注tag相似的用户,有的用户想关注location相似的用户。若只是对全局偏好信息进行建模,则会损失掉个性偏好信息,不利于embedding。
所以,需要在meta paths上为个性偏好信息建模。
其次,现有的方法捕获不到path instances中的个性偏好信息。
HIN可以看成是在给定meta paths的条件下,节点通过path instances的连接。现有的相似度衡量方法,忽略了path instances之间的不同。
还是以HIN中的朋友推荐为例,给定元路径user-tag-user,一个user可能通过多个path instances和多个user相连。而连接它们的tags也许并不合适,因为一个user可能有多个tags,或者tags的数量很少。就需要对这些path instances进行辨别,突出最相关的path instances,忽略掉噪声,已学习到更好的embedding。
2.2 作者提出
提出HAHE模型,在meta paths和path instances上建模个性偏好信息,以学习到更有效的HIN embedding。
path instances是基于meta paths的,所以使用分两层的注意力机制:元路径注意力层(meta path attention layer)和路径实例注意力层(path instances attention layer)。其中元路径注意力层为每个节点学习到面向meta paths的个性偏好,路径实例注意力层辨别path instances在给定meta paths条件下的重要程度。
在HIN embedding中使用注意力的优点:
(1)提升了HAHE模型在面向HIN的噪声部分建模的鲁棒性,提升了signal-to-noise(SNR)系数。
(2)注意力机制在建模节点时,突出了在所给任务的前提下,和该节点最相关的节点。使得模型更具有可解释性。
注:
(1)本文是自己定义元路径的,因为元路径的自动发现并不是本文的研究内容。
(2)本文设置了Target/Content type nodes,只学习target type nodes的节点表示。若要学习到所有类型节点的表示,需要将所有的节点类型都设为target type。
2.3 贡献
(1)提出HAHE模型,捕获在meta paths和path instances上的个性偏好信息,用于HIN embedding。
(2)设计了分层注意力机制,学习在meta paths和path instances上的注意力系数。
3 HAHE模型
模型结构如下图所示:

3.1 Path instance attention layer
**这一注意力层的目的是,学习到meta path π \pi π的嵌入表示 H π H^\pi Hπ,**以区分path instances。
使用基于邻接向量 A i π A^\pi_i Aiπ的meta path,作为节点 v i v_i vi的结构特征表示。
通过path instances与 v i v_i vi相连的节点,与 v i v_i vi结构特征相似的节点,对应的注意力系数 α π \alpha^\pi απ应该更大,计算如下:
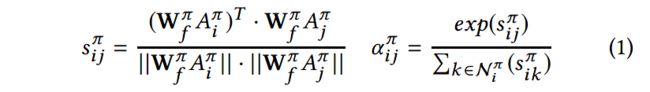
由于 A i π A^\pi_i Aiπ可能稀疏且高维,所以使用MLP将其转换到 d d d维。上式中的 s i j π s^\pi_{ij} sijπ就是基于meta path π \pi π,节点 v i , v j v_i, v_j vi,vj转换后的相似度。 W f π W^\pi_f Wfπ是针对 π \pi π的结构特征转换矩阵。 α i j π \alpha^\pi_{ij} αijπ是基于meta path π \pi π,为与节点 v i v_i vi相连的节点 v j v_j vj分配的注意力系数。这个注意力系数,是为了学习到向量 h i π h^\pi_i hiπ, i i i是节点下标, π \pi π是元路径。
由于与一个节点相连的path instances可能非常多,全部聚合这么多节点的信息会导致聚合的特征变得稀疏。所以从连接的节点集合中均匀采样部分节点,进行信息聚合,得到聚合embedding h N ( i ) π h^\pi_{N(i)} hN(i)π:

再接着,聚合 h N ( i ) π h^\pi_{N(i)} hN(i)π(针对元路径 π \pi π的邻居的embedding)和节点自身的特征,得到 h i π h^\pi_i hiπ:
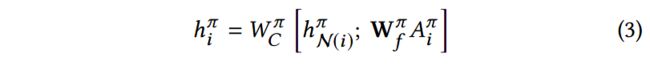
学习到的meta path based embedding h i π h^\pi_i hiπ不仅含有节点自身的特征,还加权聚合了通过path instances与该节点相连的其他节点们的特征。
3.2 Meta path attention layer
给定path instance attention layer学习到的mata path based embedding H 1 , H 2 , . . . H M {H^1, H^2, ... H^M} H1,H2,...HM,应结合这些embedding以得到更易理解的节点embedding。每一个meta path based embedding,都保留了接地那在特定语义空间中的相似性信息。
为了捕获到每个节点在meta paths上的个性偏好信息,使用meta path attentino layer对其建模,以学习到节点嵌入 H H H。
首先为每个节点 v i v_i vi引入meta path偏好向量 p i ∈ R 1 × k p_i\in R^{1\times k} pi∈R1×k,以指导meta path注意力机制区分meta path based embedding,为与 p i p_i pi相似的 h i π h^\pi_i hiπ分配较大的注意力系数。
因为 p i p_i pi是k维的,所以要将 H π H^\pi Hπ也转换为k维,才能比较两者的相似性,转换如下:
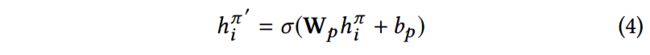
基于偏好向量和转换后的meta path based embedding,注意力系数计算如下:
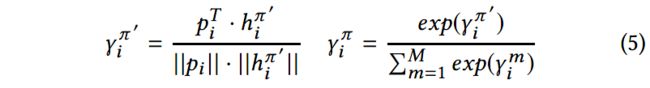
接着根据注意力系数的分配,基于meta path based embedding h i 1 , h i 2 , . . . , h i M {h^1_i, h^2_i,..., h^M_i} hi1,hi2,...,hiM(M表示meta path的数量)的节点 v i v_i vi的embedding计算如下:

3.3 损失函数
在针对特定任务的半监督学习过程中学习HAHE的参数,使用交叉熵损失函数。
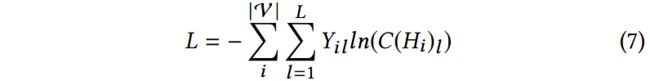
其中, Y i l ∈ { 0 , 1 } Y_{il}\in {\{0, 1\}} Yil∈{0,1}表示节点 v i v_i vi是否有标签 l l l的真实值, C ( H i ) l ∈ { 0 , 1 } C(H_i)_l\in {\{0, 1\}} C(Hi)l∈{0,1}是节点 v i v_i vi是否有标签 l l l的预测值。
整个HAHE模型的算法如下所示:

4 实验
数据集:DBLP、YELP、IMDB
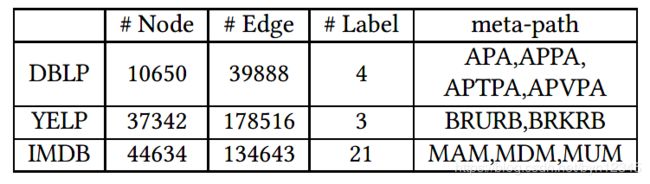
实验任务:节点分类;网络可视化
对比方法:
- Node2vec/LINE
- GraphSAGE
- GCN
- GAT
- Metapath2Vec:HIN嵌入学习的state-of-the-art之一
- HIN2vec:HIN嵌入学习的state-of-the-art之一
实验结果:
(1)节点分类实验结果:
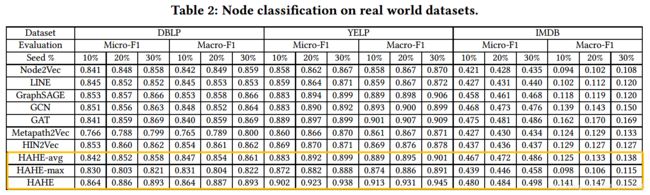
(2)网络可视化实验结果:
和Metapath2Vec、HIN2vec相比,可视化效果更好:同类的节点聚合明显,异类的节点彼此远离。

5 总结
提出HAHE模型解决HIN的嵌入学习问题。与以往方法不同的是,该方法使用了分层注意力机制,在meta paths和path instances上对节点的个性偏好信息进行建模。
模型的优化是基于半监督学习的,无法学习到所有类型节点的嵌入表示,作者将学习所有类型的节点的嵌入表示作为future work。
(注意力机制是个好东西,啥都能套)