准备工作,配置输出GC日志
本文以idea的启动日志为例解读CMS收集器的GC日志
在idea64.exe.vmoptions文件中可以看到idea的启动参数,下面是初始启动参数配置
-Xms128m
-Xmx750m
-XX:ReservedCodeCacheSize=240m
-XX:+UseConcMarkSweepGC
-XX:SoftRefLRUPolicyMSPerMB=50
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
其中-XX:+UseConcMarkSweepGC表示使用ParNew + CMS + Serial Old收集器组合进行内存回收,Serial收集器是作为CMS收集器出现Concurrent Model Failure失败后的后备收集器,相当于替补。
接下来需要添加启动参数来打印idea的GC日志,JVM提供的几个主要的GC日志参数如下:
- -verbose:gc
在虚拟机发生内存回收时在输出设备显示信息,格式如下:[Full GC 268K->168K(1984K), 0.0187390 secs]该参数用来监视虚拟机内存回收的情况。 - -XX:+PrintGC
发生垃圾收集时打印简单的内存回收日志 - -XX:+PrintGCDetails
发生垃圾收集时打印详细的内存回收日志 - -XX:+PrintGCTimeStamps
输出GC的时间戳(以基准时间的形式,如49.459,默认就是这个输出形式,可以不写) - -XX:+PrintGCDateStamps
输出GC的时间戳(以以日期的形式,如2019-03-01T12:57:54.486+0800) - -XX:+PrintHeapAtGC
在进行GC的前后打印出堆的信息,经过个人实验,这个参数开启后只会在Minor GC的前后打印堆信息,而老年代CMS的Major GC前后则不会打印,不知道是什么原因。 - -Xloggc:../logs/gc.log
日志文件的输出路径
综上,我们在idea64.exe.vmoptions文件中添加如下配置参数打印GC信息
-verbose:gc
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-Xloggc:D:/gc.log
然后重启idea,就能在对应的D盘根目录下找到生成的gc.log日志。
GC日志内容解读
由于日志内容过长,一下子全展示出来太乱而不方便阅读,这里对日志中每个不用的现象输出分别做出讲解。
首先文件的最开头的信息如下:

这个很好理解,就是显示了当前程序运行的环境,当前的jdk版本为1.8。
接下来的输出信息如下:

这部分显示了这次JVM的启动参数配置,我们在idea64.exe.vmoptions配置的信息也会在这里打印出来,我们可以从这里看出很多默认配置,比如-XX:MaxTenuringThreshold=6这个参数,表示Survivor区的对象晋升老年代的年龄阈值为6,这个值在JDK 1.8之前默认为15。
再下面就是应用的GC信息了,不同的内存区域(新生代和老年代)发生的GC日志信息有所不同,下面一一举例。
MInor GC日志信息:

最前面的2019-03-01T13:38:04.037+0800: 0.867:是固定的,2019-03-01T13:38:04.037+0800表示GC发生的日期花间,0.867表示本次gc与JVM启动时的相对时间,单位为秒。
[GC (Allocation Failure)这里的GC表示这是一次垃圾回收,但并不能单凭这个就判断这是依次Minor GC,下文会说到CMS的标识为[GC (CMS Initial Mark)和[GC (CMS Final Remark),同样是GCCMS的却是是Major GC;括号中的Allocation Failure表示gc的原因,新生代内存不足而导致新对象内存分配失败。
再后面的[ParNew:表示本次gc使用的垃圾收集器为ParNew,我们知道ParNew是针对新生代的垃圾收集器,从这可以看出本次gc是Minor GC。后面紧跟着的34944K->4352K(39296K)的含义是GC前该内存区域已使用容量 -> GC后该内存区域已使用容量(该内存区域总容量),再后面的0.0138186 secs表示该内存区域GC所占用的时间,单位为秒。
再后面的34944K->6355K(126720K), 0.0141834 secs表示收集前后整个堆的使用情况,0.0141834 secs表示本次GC的总耗时,包括把年轻代的对象转移到老年代的时间。
最后的[Times: user=0.06 sys=0.00, real=0.02 secs]表示GC事件在不同维度的耗时,单位为秒。这里面的user、sys和real与Linux的time命令所输出的时间含义一致,分别表示用户态消耗的CPU时间、内核态消耗的CPU时间和操作从开始到结束所经过的等待耗时,例如等待磁盘I/O、等待线程阻塞,而CPU时间不包括这些耗时,但当系统有多CPU或者多核的话,多线程操作会叠加这些CPU时间,所以有时候user或sys时间超过real时间也是完全正确的。
Full GC / Major GC日志信息:
这里先要明确Minor GC、Major GC和Full GC的区别:
- Minor GC:针对年轻代的垃圾回收
- Major GC:针对老年代的垃圾回收。
- Full GC:针对整个堆(包括年轻代和老年代)的垃圾回收,而且会将年轻代存活的对象全部转移到老年代。
老年代由CMS收集器执行的Major GC相对比较复杂,包括初始标记、并发标记、重新标记和并发清除4个阶段,下面的gc日志也详细地描述了各个阶段的信息。
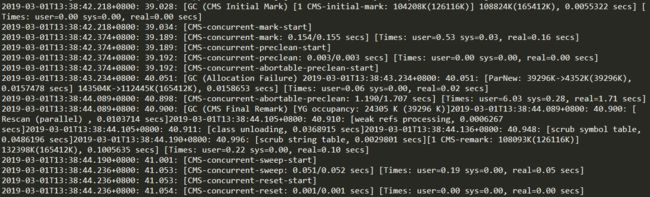
为了更清晰的观察各个阶段的日志信息,对上面的日志信息重新排版并添加注释,如下:
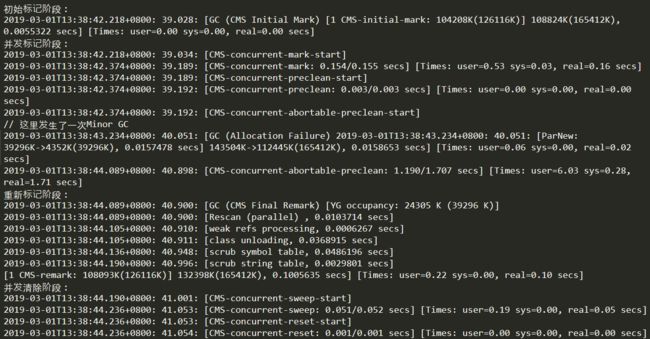
下面对上图中各个阶段的日志进行分析
初始标记阶段(CMS initial mark)

[GC (CMS Initial Mark)表示这是CMS开始对老年代进行垃圾圾收集的初始标记阶段,该阶段从垃圾回收的“根对象”开始,且只扫描直接与“根对象”直接关联的对象,并做标记,需要暂停用户线程(Stop The Word,下面统称为STW),速度很快。104208K(126116K)表示当前老年代的容量为126116K,在使用了104208K时开始进行CMS垃圾回收。可以计算下这个比例,104208 / 126116约等于0.83,可以大概推算出CMS收集器的启动内存使用阈值。
后面的108824K(165412K), 0.0055322 secs表示当前整个堆的内存使用情况和本次初始标记耗费的时间,最后的[Times: user=0.00 sys=0.00, real=0.00 secs]上文已经讲过,下文将不再重复。
并发标记阶段(CMS concurrent mark)
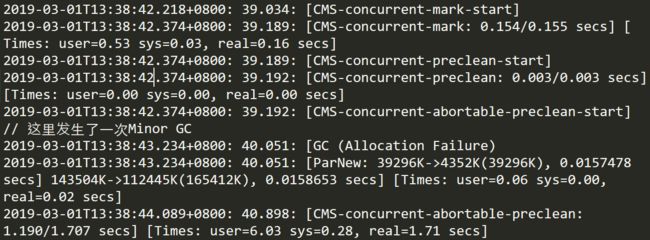
该阶段进行了细分,但都是和用户线程并发进行的
[CMS-concurrent-mark表示并发标记阶段,会遍历整个年老代并且标记活着的对象,后面的0.154/0.155 secs表示该阶段持续的时间和时钟时间,耗时0.15秒,可见耗时是比较长的。
由于该阶运行的过程中用户线程也在运行,这就可能会发生这样的情况,已经被遍历过的对象的引用被用户线程改变,如果发生了这样的情况,JVM就会标记这个区域为Dirty Card。
[CMS-concurrent-preclean阶段会把上一个阶段被标记为Dirty Card的对象以及可达的对象重新遍历标记,完成后清楚Dirty Card标记。另外,一些必要的清扫工作也会做,还会做一些final remark阶段需要的准备工作。
[CMS-concurrent-abortable-preclean并发预清理,这个阶段尝试着去承担接下来STW的Final Remark阶段足够多的工作,由于这个阶段是重复的做相同的事情直到发生aboart的条件(比如:重复的次数、多少量的工作、持续的时间等等)之一才会停止。这个阶段很大程度的影响着即将来临的Final Remark的停顿。
从后面的1.190/1.707 secs显示这个阶段持续了1秒多的时间,相当的长。
重新标记阶段(CMS remark)
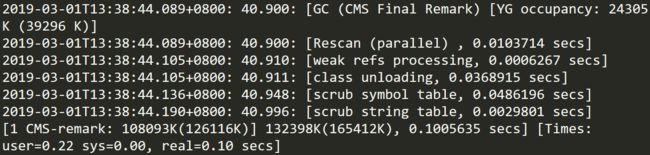
该阶段同样被细分为多个子阶段
[GC (CMS Final Remark)表示这是CMS的重新标记阶段,会STW,该阶段的任务是完成标记整个年老代的所有的存活对象,尽管先前的pre clean阶段尽量应对处理了并发运行时用户线程改变的对象应用的标记,但是不可能跟上对象改变的速度,只是为final remark阶段尽量减少了负担。
[YG occupancy: 24305 K (39296 K)]表示年轻代当前的内存占用情况,通常Final Remark阶段要尽量运行在年轻代是足够干净的时候,这样可以消除紧接着的连续的几个STW阶段。
[Rescan (parallel) , 0.0103714 secs]这是整个final remark阶段扫描对象的用时总计,该阶段会重新扫描CMS堆中剩余的对象,重新从“根对象”开始扫描,并且也会处理对象关联。本次扫描共耗时 0.0103714s。
[weak refs processing, 0.0006267 secs]第一个子阶段,表示对弱引用的处理耗时为0.0006267s。
[class unloading, 0.0368915 secs]第二个子阶段,表示卸载无用的类的耗时为0.0368915s。
[scrub symbol table, 0.0486196 secs]最后一个子阶段,表示清理分别包含类级元数据和内部化字符串的符号和字符串表的耗时。
[1 CMS-remark: 108093K(126116K)]表示经历了上面的阶段后老年代的内存使用情况。再后面的132398K(165412K), 0.1005635 secs表示final remark后整个堆的内存使用情况和整个final remark的耗时。
并发清除阶段(CMS concurrent sweep)

该阶段和用户线程并发执行,不会STW,作用是清除之前标记阶段没有被标记的无用对象并回收内存。整个过程分为两个子阶段。
CMS-concurrent-sweep第一个子阶段,任务是清除那些没有标记的无用对象并回收内存。后面的参数是耗时,不再多提。
CMS-concurrent-reset第二个子阶段,作用是重新设置CMS算法内部的数据结构,准备下一个CMS生命周期的使用。
这里再讲一个小知识点,我们上面提到CMS收集器会在老年代内存使用到一定程度时就触发垃圾回收,这是因为CMS收集器的一个缺陷导致的这种设定,也就是无法处理“浮动垃圾”,“浮动垃圾”就是指标记清除阶段用户线程运行产生的垃圾,而这部分对象由于没有做标记处理所以在本次CMS收集中是无法处理的。如果CMS是在老年代空间快用完时才启动垃圾回收,那很可能会导致在并发阶段由于用户线程持续产生垃圾而导致老年代内存不够用而导致“Concurrent Mode Failure”失败,那这时候虚拟机就会启用后备预案,临时启用Serial Old收集器来重新进行老年代的垃圾收集,Serial Old是基于“标记-整理”算法的单线程收集器,这样停顿时间就会很长。这个CMS启动的内存使用阈值可以通过参数-XX:CMSInitiatiingOccupancyFranction来设置,默认为68%(这是网上查到的数据),不过这68%应该是JDK1.8之前版本的默认参数,因为上文中初始标记阶段的gc日志分析中显示老年代内存使用到了83%才开始的CMS垃圾收集。我通过在命令行输入java -XX:+PrintFlagsInitial命令查看到的本机参数如下,也不知道这-1是什么意思,随机?如果你知道,可以在文章下留言告知,十分感谢!

由于元空间内存不足而引发的Full GC
这里还有一种Full GC日志也比较容易出现,如下:

通过[Full GC (Metadata GC Threshold)我们知道这是一次针对整个堆(包括年轻代和老年代)的Full GC,括号中的Metadata GC Threshold说明了gc发生的原因,是因为元空间内存不足够而产生扩容导致的GC,同样的我们还可以通过后面的[CMS: 0K->19938K(1048576K)看出在老年代内存使用为0的时候就发生了Full GC,所以可以确定不是因为老年代内存不够用而发生的gc。
再后面的[Metaspace: 20674K->20674K(1069056K)]表示这次gc前后的元空间(Metaspace)内存变化,元空间的最大容量为1069056K,约等于1G,疑问便来了,最大容量为1G,已使用才20670K,为什么会不够用?
从JDK8开始,方法区采用元空间(Metaspace)的概念来实现,原来的永久代(PermGen)实现被废弃。元空间并不在虚拟机中,而是使用本地内存,默认情况下,元空间的大小仅受本地内存限制。可以通过下面的参数来指定元空间的大小:
- -XX:MetaspaceSize:初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
可以通过在命令行输入java -XX:+PrintFlagsInitial命令查看到默认初始值为21810376B(约为20.8M)。 - -XX:MaxMetaspaceSize:最大空间,默认是没有限制的,根据机器实际内存而定。
还有几个参数也值得我们关注:
- -XX:MinMetaspaceFreeRatio:在GC之后,会计算当前Metaspace的空闲空间比,空闲内存小于该值时就会为其扩容,默认为40,即40%。
- -XX:MaxMetaspaceFreeRatio:在GC之后,会计算当前Metaspace的空闲空间,空闲空间大于该值时就会缩小Metaspace的空间,默认为70,即70%。
- -XX:MinMetaspaceExpansion:元空间每次扩容的最小幅度,默认为340784B(约为332.8K)。
- -XX:MaxMetaspaceExpansion:元空间每次扩容的最大幅度,默认为5452592B(大约为5MB)。
所以我们只要根据实际情况将元空间的初始值设置的大一点就可以避免这种Full GC。
程序中调用System.gc()而引发的Full GC
还有一种gc日志,虽然不多见,但也在我这次启动中出现了,如下
[Full GC (System.gc())说明这是一次Full GC,是由于调用System.gc()触发的。
后面的[CMS: 114245K->129265K(536576K)表示这次gc后老年代内存占用由114245K上涨到了129265K,注意,这并不能说明没有对老年代进行回收;再后面的378366K->129265K(997376K)表示这次gc后整个堆空间大小缩小到了129265K,正好等于老年代的使用量,所以可以推断这次Full GC回收了年轻代的内存,并将存活的对象全部移到了老年代。
为了更清楚的看清这次gc前后各个内存区域的内存占用变化,在启动参数中加入-XX:+PrintHeapAtGC参数打印GC前后的堆内存信息,重启idea,同样发生了这种gc,如下:

红框部分的现象跟上面的现象差不多,红框上面是gc前堆中各区域的使用情况,红框下面是gc后堆中各区域的使用情况,可以看出这次gc后新生代确实被清空了(eden、form和to区使用量都为0%),老年代占用内存变大,再反观之前的由于元空间内存不足而发生的Full GC同样也是清空了年轻代,由此可以推论出Full GC会对整个堆进行垃圾回收,并且会将年轻代存活的对象全部转移到老年代。
总结
本文章解读了jdk1.8版本下idea采用CMS收集器时的启动gc日志信息,阅读完这篇文章后能对GC日志有个大体的认识,通过对GC日志的分析可以帮助你更加清晰深入的理解JVM的内存分布,以及垃圾收集的具体细节。不同垃圾收集方案下的gc日志会有所不同,但也都大同小异。