【阅读笔记】机器阅读理解(中)——架构篇
文章目录
- 一、MRC模型架构
- 总体架构
- 编码层
- 词表向量
- 字符编码
- 上下文编码
- 交互层
- 互注意力
- 自注意力
- 上下文编码
- 输出层
- 多项式选择答案生成
- 区间式答案
- 自由式答案生成
- 注意力机制的应用
- 拷贝生成机制
- 二、常见MRC模型
- BiDAF
- R-net
- 融合网络
- 单词历史
- 全关注注意力
- 总体架构
- 关键词检索与阅读模型(ET-RR)
- 检索器
- 阅读器
- 三、预训练模型与迁移学习
- 基于翻译的PTM——CoVe
- 基于语言模型的ELMo
- 生成式PTM——GPT
- transformer
- 多头注意力
- 位置编码
- 残差网络
- GPT本身
- 划时代的BERT
- 双向语言模型
- NSP
- 具体任务
- BERT的改进措施【重要】
一、MRC模型架构
总体架构
在交互层,模型需要建立文章和问题之间的联系。比如问题出现“河流”,而文章中出现关键词“长江”,虽然两个词完全不一样,但是其语义编码相近,因此文章中“长江”一词,以及它附近的语句将成为模型回答问题时的重点关注对象。
大部分阅读理解的创新集中在交互层,因为这一层中对文章和问题语义的交叉分析有很多不同的处理方式,而且这也是模型最终能产生正确答案的关键步骤。
编码层
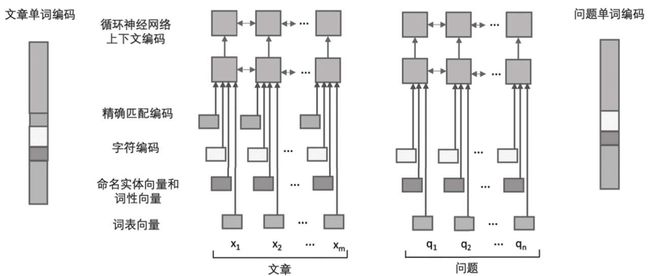
编码层生成单词编码可以包括:词表向量、NE向量、POS向量、字符编码、精确匹配编码和上下文编码。
词表向量
有两种方式获得词表中的单词向量:
- 保持词表向量不变,即采用预训练词表中的向量,在训练过程中不进行改变
- 将词表中的向量视为参数,在训练过程中和其他向量一起求导并优化
第一种选择的优势是模型参数少,训练初期收敛较快;后者可以根据实际数据调整词向量的值,以达到更好的训练效果。
在编码层中,为了准确表示每个单词在语句中的语义,除了词表向量化外,还经常对NE和POS进行向量化处理。如建立命名实体表(其实就是矩阵,N*dN,N是NE种类),词性表(P * dP),两个表中的向量均是可训练的参数。然后用文本分析软件比如Spacy获得文章和问题中的每个词的NE和POS,在将对应向量拼接在词向量之后。由于一个词的POS和NE和所在语句有关,因此用这种方式获得的向量编码可以更好地表达单词的雨衣,在许多模型中对性能都有明显的提升!
另一种在MRC里常见的单词编码是精确匹配编码,对于文章中的单词w,检查w是否出现在问题中,如果是则w精确匹配编码为1,否则为0,然后将这个二进制位拼接在单词向量后。由于单词可能有变体,所以也可以用另一个二进制位表示w的词干是否和问题中某些词的词干一致。精确匹配编码可以使模型快速找到文章中出现了问题单词的部分,而许多问题的答案往往就在这部分内容的附近。
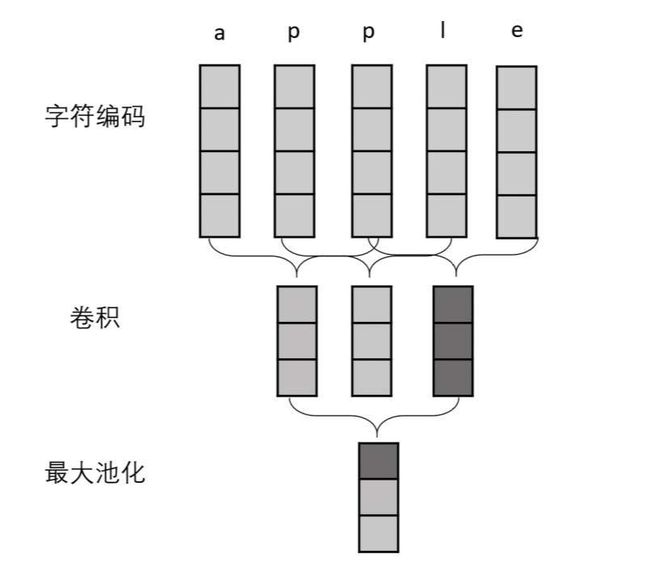
字符编码
在单词理解中,字符和子词具有很强的辅助作用。通过字符组合往往可以识别正确的单词形式(纠错)。为了得到固定长度的字符向量编码,最常用的模型是字符CNN
设一个单词有K个字符,对应K个字符向量,每个向量维度为c。字符CNN利用一个窗口大小为W且有f个输出通道的CNN,获得(K-W+1)个f维向量。然后利用最大池化,求得这些向量每个维度上的最大值,形成一个f维向量作为结果。
"""
首先需要合并前两个维度batch和seq_len形成三维数据输入标准CNN网络,
然后将输出中第一维展开回两维,得到batch, seq_len, out_channels三个维度,
即每个单词得到个out_channels维字符向量
new_seq_len = word_len - window_size + 1
"""
class Char_CNN_Maxpool(nn.Module):
def __init__(self, char_num, char_dim, window_size, out_channels):
super(Char_CNN_Maxpool, self).__init__()
self.char_embed = nn.Embedding(char_num, char_dim)
# 1个输入通道,out_channels个输出通道,过滤器大小
self.cnn = nn.Conv2d(1, out_channels, (window_size, char_dim))
def forward(self, char_ids):
"""
输入:为每个单词里的字符编码char_ids,共4维,包括batch,seq_len,单词中字符个数word_len和字符向量长度char_dim
char_ids: (batch, seq_len, word_len),每个词含word_len个字符编号(0~char_num-1)
输出:(batch*seq_len * out_channels)
"""
x = self.char_embed(char_ids)
# x: (batch * seq_len * word_len * char_dim )
x_unsqueeze = x.view(-1, x.shape[2], x.shape[3]).unsqueeze(1)
# x_unsqueeze: ((batch*seq_len) * 1 * word_len * char_dim )
x_cnn = self.cnn(x_unsqueeze)
# x_cnn:((batch*seq_len) * out_channels * new_seq_len * 1)
x_cnn_result = x_cnn.squeeze(3)
# x_cnn_result : ((batch*seq_len) * out_channels * new_seq_len),删除最后一维
res, _ = x_cnn_result.max(2)
# 最大池化,得到:((batch*seq_len) * out_channels)
return res.view(x.shape[0], x.shape[1], -1) # (batch*seq_len * out_channels)
上下文编码
编码层需要为每个单词生成上下文编码(contextual embedding),这种编码会随着单词的上下文不同而发生改变,从而反映出单词在当前语句中的含义。
RNN是最常用的上下文编码生成结构。
交互层
交互层可以交替使用互注意力、自注意力、上下文编码。通过这些步骤的反复使用,可以使模型更好理解单词、短语、句子、片段以及文章的语义信息,同时融入对问题的理解,从而提高预测答案的准确度。
随着交互层结构复杂化,容易导致参数过多、模型过深,引起梯度消失、梯度爆炸、难以收敛或过拟合等不利于模型优化的现象。因此,一般建议可以从较少的层数开始,逐渐增加注意力和上下文编码的模块,同时配合采用Dropout、梯度裁减等辅助手段加速优化进程。
互注意力
为了对文章的单词向量、问题的单词向量两部分的语义进行交互处理,一般采用注意力机制。
在MRC中,可以用注意力机制计算从文章到问题的注意力向量:基于对文章第i个词pi的理解、对问题单词向量组(q1,…,qn)的语义总结,得到一个向量piq,是向量组Q的线性组合,即从单词向量pi的角度对单词向量组Q=(q1,…,qn)进行总结,从而得到Q所代表的语句与单词pi相关的部分信息,其中与pi相关的Q中单词获得相对大的权重。
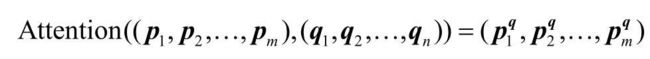

从图可知,交互注意力的结果向量个数是文章单词的个数m,而维度是问题单词的编码长度qi。
用类似的方法也可以得到从问题到文章的注意力向量qip,这可以使模型在理解每个问题单词语义的同时兼顾对文章的理解。上两种方式的注意力机制统称 互注意力。
注意力机制通过注意力函数对向量组Q中的所有向量打分。一般而言,注意力函数需要反映pi和每个向量qj的相似度。常见的注意力函数有:
- 内积函数,应用在pi和qj维度相同时。
- 二次型函数,可以在计算过程中加入参数,便于优化
- 加法形式函数
- 双维度转换函数,此函数将文章和问题单词向量转化到低纬度进行相乘,减少了参数个数。
自注意力
在一些文章中,要获得答案需要理解文章中若干段相隔较远的部分,可以使用自注意力机制。这使得信息可以在相隔任意距离的单词间交互,大大提高信息传递效率。每个单词计算注意力向量的过程都是独立的,可以用并行计算提高运行速度。
下面算法**,使用参数矩阵W将原向量映射到隐藏层**,然后计算内积得到注意力分数。这样做的好处是可以在向量维度较大时通过控制隐藏层大小降低时空复杂度。
class SelfAttention(nn.Module):
def __init__(self, dim, hidden_dim):
super(SelfAttention, self).__init__()
self.W = nn.Linear(dim, hidden_dim)
def forward(self, x):
hidden = self.W(x) # 计算隐藏层,结果为 batch * n * hidden_dim
scores = hidden.bmm(hidden.transpose(1,2)) # batch * n * n
alpha = F.softmax(scores, dim=-1) # 对最后一维softmax
attended = alpha.bmm(x) # 注意力向量,结果为batch x dim
return attended
但是自注意力机制完全舍弃了单词的位置信息(单词的顺序和出现位置也会对语义产生影响),因此,自注意力可以和rnn同时使用。此外,还可以配合 位置编码,为自注意力加入单词的位置信息。
上下文编码
(见书)
输出层
为了从文章中生成答案,通常将问题作为一个整体与文章中的单词进行匹配运算。因此,需要用一个向量q表示整个问题,以方便后续处理。经过交互层的处理,向量q中已包含问题中所有单词的上下文信息,也包括了文章的信息。
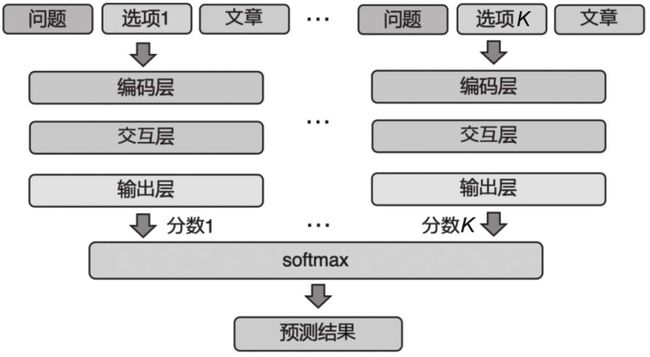
多项式选择答案生成
为了预测正确答案,模型需要在输出层对每个选型计算一个分数,最后选取分数最大的选项作为输出。
设一共有K个选项,可以用类似于处理问题的方法分析每个选项的语义:对选项每个单词进行编码,在和问题和文章计算注意力向量,从而得到一个向量ck代表第k个选项的语义。然后,综合文章、问题与选项计算该选项的得分。这里可以灵活设计各选项得分的网络结构,下面给出两种网路结构:
- 得到一个表示文章的单一向量p,选项得分为sk=pTWcck + pTWq q。(也就是分别结合计算选项、问题)
- 对问题向量q和选项向量ck进行拼接,得到tk=[q; ck] ,然后将ti作为RNN的初试状态,计算(p1,p2,…pm)的RNN状态(h1,h2,…hm),利用最后位置的RNN状态hm和参数向量b的内积,得到选项得分sk=hTm b
因为是分类问题,所有使用交叉熵作为损失函数,fcross_entropy=-log(pk*)。
区间式答案
对于一篇长度为m的文章,可能的区间式答案有m(m-1)/2种。在SQuAD这种数据集上,标准答案长度一般不会太长,一般参赛队伍会设置为15个单词左右,但即使限定答案长度为L,可能区间答案扔有L*m种可能。所以模型预测的是始末位置。

可以看出,计算始末位置的过程是独立的。因此也有模型尝试在两个计算过程之间传递信息,比如FusionNet模型就让两个过程之间有了关联。
两者均为多分类任务,因此也可以用交叉熵损失函数:fcross_entropy=-log(p i* S) -log(p j*E) ,即2个多分类问题的交叉熵之和。模型在预测时需要找到概率最大的一组开始位置和结束位置:iR,jR=argmax PS i PE j。
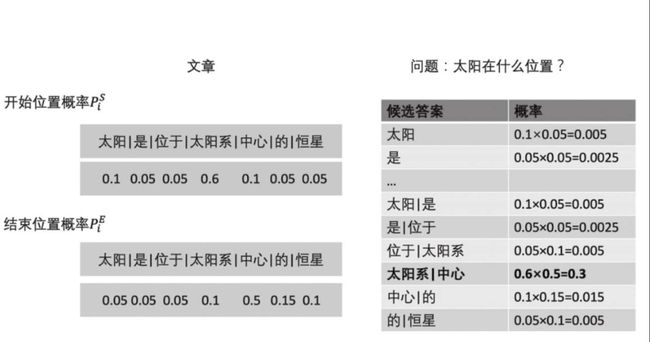
"""
答案区间生成:
输入:prob_s是大小为m的开始位置概率,prob_e是大小为m的结束位置概率,均为一维pytorch张量
设文本共m个词,L为答案区间可以包含的最大单词数
输出:概率最高的区间在文本中的开始位置和结束位置
"""
def get_best_interval(prob_s, prob_e, L):
prob = torch.ger(prob_s, prob_e)
# 从两个一维输入向量生成矩阵,获得m*m的矩阵,其中prob[i,j]=prob_s[i] x prob_e[j]
prob.triu_().tril_(L-1)
# 上三角矩阵保证开始位置不晚于结束位置,tril_函数保证候选区间长度不大于L,对这2个操作取一个交集
# 即如果i>j 或 j-i+1>L,设置prob[i,j]为0
prob = prob.numpy()
# 转为numpy数组
best_start, best_end = np.unravel_index(np.argmax(prob), prob.shape)
# 获得概率最高的答案区间在原数组中的索引,开始位置为第best_start个词,结束位置为第best_end个单词
return best_start, best_end
自由式答案生成
模型输出层基本采用encoder-decoder模型。设词表大小为|V|,词表向量维度是d,建立大小为d*|V|的全连接层将h1 dec 转化为一个|V|维向量,表示模型对词表每个单词的打分。这些分数经过softmax可以得到预测概率P1,…Pv。一般来说,编码器的词表、解码器的词表、最终的全连接层共享其中的参数:大小均为d * |V| 或|V| * d,这样做既可以减少参数个数,还能大大提高训练效率和质量。
传入到第二个RNN单元的时候(第一个答案单词向量是文本开始位置标识符),输入单词向量取决于是否使用Teacher forcing:如果使用,则使用标准答案的第一个单词,否则使用分数最高的单词——即模型预测的第一个词。
对于单词,一个提升准确率的技巧是,在模型最终输出答案时将所有生成答案里的用文章中随机选择的单词替换,这样可以去除的同时保证准确率不会下降。
注意力机制的应用
答案生成的各个位置的单词可能与文章中不同的片段有关,注意力机制也用在解码器中,在生成单词的时候提供文章的信息。

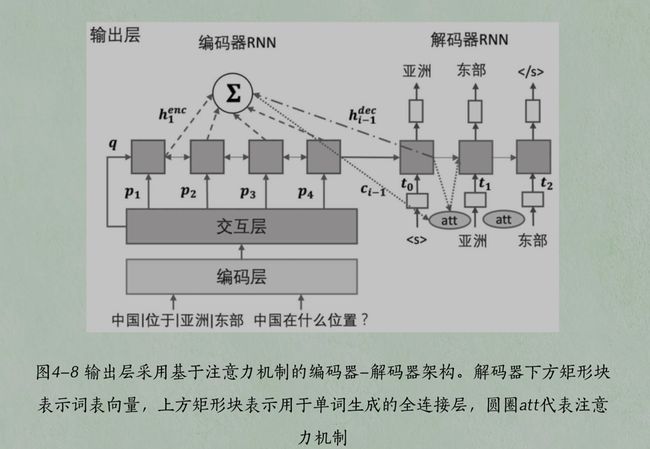
"""
解码器注意力机制
"""
class Seq2SeqOutputLayer(nn.Module):
def __init__(self, embed, word_dim, vocab_size):
super(Seq2SeqOutputLayer, self).__init__()
self.emb = embed
self.vocab_size = vocab_size
self.encoder_rnn = nn.GRU(word_dim, word_dim, batch_first=True)
self.decoder_rnncell = nn.GRUCell(word_dim, word_dim)
# 将RNN状态和注意力向量的拼接结果降维成word_dim维
self.combine_state_attn = nn.Linear(word_dim + word_dim, word_dim)
self.linear = nn.Linear(word_dim, vocab_size, bias=False)
self.linear.weight =embed.weight
def forward(self, x, q, y_id):
"""
x:交互层输出的文章单词向量,维度为 batch * seq_len * word_dim
q: 交互层输出的问题向量,维度为 batch * word_dim
y_id:真值输出文本的单词编号,维度为 batch * seq_len * word_dim
输出预测的每个位置每个单词的得分为 word_scores,维度是 batch * y_seq_len * word_dim
"""
y = self.embed(y_id)
# 文章每个位置的状态enc_states,结果维度是 batch * x_seq_len * word_dim
# 最后一个位置的状态enc_last_states,维度是 1 * batch* word_dim
enc_states, enc_last_state = self.encoder_rnn(x, q.unsqueeze(0)) # 问题q为初始状态
# 解码器的初试状态为编码器的最后一个位置的状态,维度是 batch * word_dim
prev_dec_state = enc_last_state.squeeze(0)
# 最终输出为每个答案所有位置各种单词的得分
scores = torch.zeros(y_id.shape[0], y_id.shape[1], self.vocab_size)
for t in range(0, y_id.shape[1]):
# 前一个状态和真值文本第t个词的向量表示,输入解码器RNN,得到新的状态,维度是 batch * word_dim
new_state = self.decoder_rnncell(y[:,t,:].squeeze(1), prev_dec_state)
context = attention(enc_states, new_state.unsqueeze(1)).squeeze(1) # batch * word_dim
new_state = self.combine_state_attn(torch.cat((new_state, context), dim=1))
# 生成这个位置每个词表中单词的预测得分
scores[:,t,:] = self.linear(new_state)
# 此状态传入下一个GRUCell
prev_dec_state = new_state
return scores
vocab_size = 100
word_dim = 20
embed = nn.Embedding(vocab_size, word_dim)
y_id = torch.longTensor(30, 8).random_(0, vocab_size) # 共30个真值输出文本的词id,每个文本长度为8
# 省略编码层和交互层,交互层最后得到:
# 文章单词向量x,维度为30 * word_dim
# 问题向量q,维度为 30 * word_dim
x = torch.randn(30, 10, word_dim)
q = torch.randn(30, word_dim)
net = Seq2SeqOutputLayer(embed, word_dim, vocab_size)
optimizer = optim.SGD(net.parameters(), lr=0.01)
word_scores = net(x, q, y_id)
loss_func = nn.CrossEntropyLoss()
# 将word_scores变为二维数组,y_id变为一维数组,计算损失函数
# word_scores计算出第2、3、4个词的预测,所以要和y_id错开一位比较
loss = loss_func(word_scores[:,:-1, :].contiguous().view(-1, vocab_size), y_id[:,1:].contiguous().view(-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
用Attention计算上下文向量context,并与编码器rnn状态合并为新的状态。同时,解码器使用RNN单元GRUCell,因为每一步只需要预测下一个位置的单词。解码过程使用teacher-forcing,即利用标准答案的单词预测下一个位置的单词。
拷贝生成机制
如果纯用encoder-decoder架构,即完全利用词表生成单词,一旦文章中的重要线索单词,特别是专有名词不在词表中,模型就会产生标识符从而降低准确率。为了解决这一问题,研究者提出了拷贝-生成机制copy-generate mechanism,使得模型也可以生成不在预定词表中的文章单词,从而有效提高生成答案的语言丰富性和准确性。该机制在生成单词的基础上提供了从文章中复制单词的选项。需要生成以下内容:
- 下一个单词是文章中第i个词wi的概率Pc(i)
- 下一个词使用生成而非拷贝方式的概率Pgen
然后将两个分布合成得到最后的单词分布:
Pc(i)本质上是文章中所有位置的一个分布,即文章中每个位置的单词在这一步被拷贝的概率。Pgen是一个实数,代表在这个位置使用生成机制的概率,它可以用上下文向量ci-1、前一个RNN单元输出状态、当前输入词向量hi-1生成Pgen。

二、常见MRC模型
BiDAF
略。
确定了MRC编码层-交互层-输出层的结构。
核心就是,交互层,也就是双向互注意力层,Q2C, C2Q得到的的是两个文章表示,它们都在不同程度上融合包含了问题的信息,从而帮助下一层的预测!
R-net
略,不过BiDAF和R-Net的阅读真的是需要循环渐进。先通过BiDAF来了解Q2C,C2Q的向量表示,从而才能更好的了解R-net,毕竟r-net是在向量表示的基础上,再引入了门控。
创新
-
门机制的应用,比如vt = GRU(vt-1,gate([ut; ct]))。
ct是t时刻的文章单词关于问题的Q2C注意力表示,ut是t时刻的文章单词向量,vt是t时刻的RNN隐层。
这里用门机制把ut和ct结合了起来,相当于用一个门控,R-net可以在每一步动态控制RNN的输入中有多少信息来自当前单词ct(融入了问题的单词向量),有多少信息来自问题ut,
-
结合了门的注意力机制融入进RNN
融合网络
融合网络(FusionNet)是一种改进了阅读理解网络中多层上下文编码和注意力机制的模型,的主要贡献在于提高了深层机器阅读理解网络的效率。全关注注意力机制基于单词历史,使用单词历史计算注意力分数,但是输出是其中某一层或某基层的加权和。
因为由于历史向量随网络深度增加而变长,会导致网络参数过多。维度压缩可以有效地解决这一问题,它既融合了单词的所有历史信息,也大大降低了注意力向量的维度,达到了化繁为简的目的。
推算维度的方式可以见5.3.3 总体架构。
单词历史
为了保留多个层次的信息,FusionNet将每个单词第1至i-1个网络层的输出向量表示拼接起来作为第i个网络层的输入。这个拼接而成的向量称为单词历史(history of word),因为其代表了之前每个阶段处理这个单词的所有编码,如X=(x1,x2,…xn)。一方面,History of Word方法使得深层网络可以更好理解文章各个层次的语义,但另一方面,随着计算层数的增加,与每个单词相关的向量编码总长度也在增加,会造成网络参数的个数激增,运算效率下降,优化效果也会受到影响。
比如说,每个文章中的单词的向量是900维,然后经过P2Q后,每个文章单词的向量获得了300维的注意力向量,即问题GloVe向量的加权和,经过这一层后,每个文章单词向量的维度为900+300=1200。
然而,如果仅仅为了保证效率而不对每层结果进行拼接,就会损失更低层次的信息。
如下图,每个竖条表示一个单词对应的向量表示。深色块代表网络中更高层的输出及其代表的语义理解。例如,文章中“小明”一词在经过第一层后,模型理解为一个人名;经过第二层后,模型理解为一个球员;经过第三层后,模型理解为一个有号码的球员。
由此可以看出,如果缺少单词历史的话,虽然文章和问题中的号码10与12截然不同,但网络中的较高计算层会认为这两个数字都是球队中的号码可以较好地匹配,从而错误预测答案“小明”。

因此,就要想一个办法,将这些单词历史融合起来!为了同时保留多层次信息且不影响计算效率,FusionNet提出了全关注注意力机制的概念。
全关注注意力

也就是说,这不仅可以融合单词历史信息,还可以实现维度压缩。在实际应用中,全关注注意力机制可以灵活使用。例如,可以多次计算注意力,每次对不同的历史层进行加权和,从而获得更丰富的语义交互信息。
总体架构
谈谈交互层:单词注意力层、阅读层、问题理解层、全关注互注意力层、全关注自注意力层
在交互层中,FusionNet反复使用全关注注意力机制和循环神经网络,并控制生成向量的维度,从而减少了模型参数,提高了计算效率。
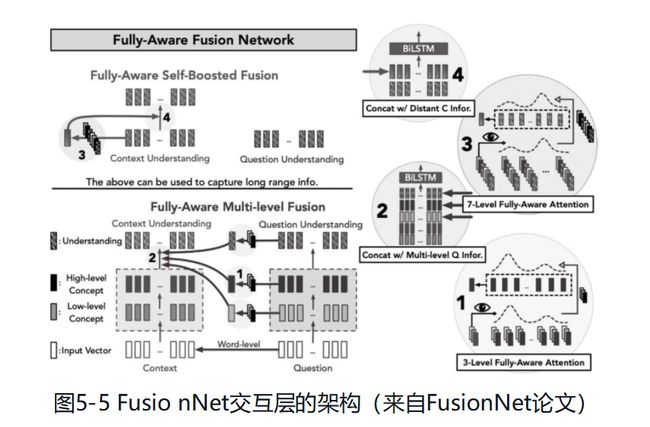
全关注互注意力层
FusionNet将全关注注意力机制应用在文章和问题的单词历史上。单词历史是一个300+600+250+250=1400维向量,这是一个非常高维的向量表示。因此,FusionNet对维度进行压缩,融合3个不同层的注意力向量。融合有不同层次的:
- 低层融合
- 高层融合
- 理解层融合
经过融合,都得到一个小维度的向量,远远小于单词历史。
全关注自注意力层
FusionNet再次使用全关注注意力机制计算文章单词的自注意力,并通过维度压缩。
关键词检索与阅读模型(ET-RR)
文本库式阅读理解任务一般包含一个大型语料库,因而此类阅读理解模型必须包含快速而有效的检索模块。
关键词检索与阅读模型(Essential-Term Retriever Reader Model, ET-RR)是2019年提出的一种文本库式阅读理解模型。它专门解决建立在大规模文本库上的多项选择式机器阅读理解任务。ET-RR模型分为**检索器(retriever)和阅读器(reader)**两个模块。检索器利用关键词抽取技术大大提高了检索结果与问题的相关度。而阅读器中根据检索结果、问题和选项建立了网络模型。

ET-RR模型最大的贡献在于使用深度学习网络提取问题中的关键词。使用问题关键词作为查询可以有效提高检索结果与问题和选项的相关性,从而提高回答的准确度,这对于文本库式机器阅读理解任务至关重要。ET-RR针对多项选择式答案,模仿人类阅读解题的方式提出了选项交互的方法,并取得了良好的效果。
检索器
对于给定的问题Q,将Q作为查询输入检索器,得到最相关的N个语料库中的句子,将它们拼接成文章段落P,从而将其转化成一般的阅读理解任务。
如果任务是多项选择形式,除了问题外,还提供N个选项C1, …, CN,一种常用的检索方法是,将问题Q和每个选项Ci拼接起来作为一个查询输入搜索引擎,得到检索结果Pi。然后,阅读器模型计算得出Pi有多大概率证明Ci为Q的正确答案。最后,模型选择概率最大的选项输出。
模型的准确性很大程度上取决于检索器返回的结果的质量,也就是段落与问题及选项的相关度。而搜索引擎对于长查询的检索质量远低于短查询。
ET-RR模型提出了一种解决方案:在问题中选择若干关键词(essential term),然后将关键词与选项拼接起来作为查询。这样可以有效缩短查询的长度,而关键词也保留了问题中的重要相关信息。
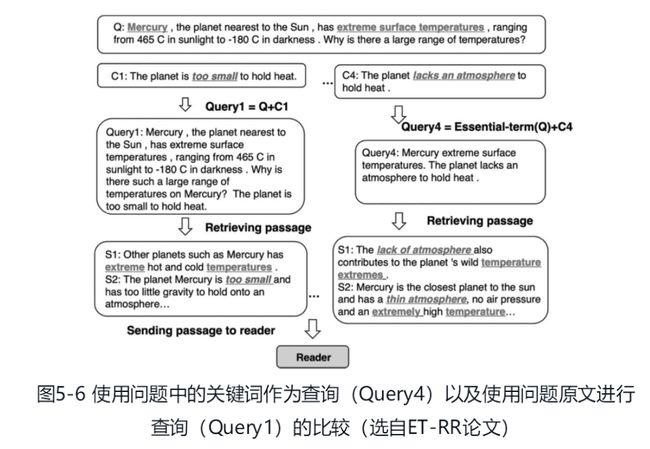
模型应该如何在一段文本中选取关键词呢?ET-RR将此任务定义为分类问题:将文本分词成为w1w2…|wn后,对每个单词进行二分类,以预测这个单词是否为关键词。为了提高二分类的准确度,ET-RR设计了分类神经网络ET-Net。
ET-NET
ET-Net的训练基于公开数据Essentiality Dataset,并使用二分类交叉熵损失函数。如果模型预测到问题中第i个词作为关键词的概率Pi大于0.5,则认为它是关键词,否则认为它不是关键词。
ET-Net获得问题Q的关键词之后,将这些关键词与每个选项Ci拼接起来输入搜索引擎Elastic Search,得到文本库中与查询最相关的K个句子。这K个句子就组成了阅读器的输入文章Pi。
阅读器
阅读器输入:这一层的输入包括与问题Q、文章Pi和选项对应的向量Ci,阅读器的作用是,根据查询结果产生选项i是Q的正确答案的可能性。阅读器融合选项之间的语义信息(类似人类做多选阅读理解)来提升模型性能。

-
关系编码
ET-RR利用大规模单词关系图ConceptNet来获得文章中的每个单词与问题及选项中的每个单词间的关系。然后,ET-RR建立关系编码字典,每种关系有一个对应的10维参数向量。
-
特征编码
根据文章P中的单词w是否在问题和选项中出现,ET-RR给w加入了一维0/1精确匹配编码。此外,w在文本中出现的频率的对数也作为一维编码。
-
注意力层
模型计算:①文章到问题的注意力向量;②选项到问题的注意力向量;③选项到文章的注意力向量;
-
序列模型层
-
融合层
在融合层中,问题和选项经过单词向量加权和各自用一个向量q和c来表示,然后,将文章单词向量HP与问题向量q进行融合,得到文章的最终表示p
-
选项交互层
人类在解决多项选择题时,经常会通过选项文本之间的区别得到有用的信息以辅助解决问题。基于这一思路,ET-RR将选项间的语义信息差异加入模型计算。
ci inter 代表选项i与其他选项的差异度。最后,将cifinal =[ ciinter ; ci ]作为选项i的最终表示。
-
输出层
这一层的输入包括与问题、文章和选项对应的向量。输出层计算文章Pn支持第n个选项是问题的正确答案的概率,用分数Sn表示。
三、预训练模型与迁移学习
使用预训练模型的方式与使用预训练词向量(如GloVe、Word2vec等)有本质上的区别,因为预训练词向量是一个向量字典,而预训练模型是一个计算模块,其中既包括网络架构,也包括网络中的参数。
基于翻译的PTM——CoVe
基于语言模型的ELMo
生成式PTM——GPT
transformer
Transformer有个重要的特性——输入和输出维度一致。因此,可以将多个Transformer依次叠加形成更复杂的结构。多层Transformer结构可以分析更深层次的语义信息。
多头注意力
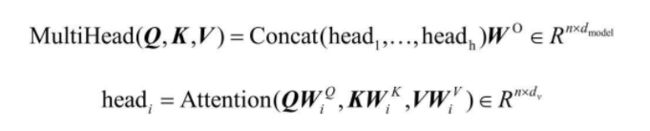
由于多头注意力包括h次含参注意力计算,因此大大增加了模型的灵活度。将多头注意力运用于自注意力机制就可以获得每个单词的上下文编码,且完全不受单词间距离的影响。
位置编码
位置编码有两种形式:函数型和表格型。
-
函数型位置编码以单词位置和维度作为参数。
(就是transformer的位置函数),PEpos,j 代表第pos个位置的单词的位置编码中第j维分量的值
优点:即使测试时出现比训练数据更长的语句,即pos值超出训练范围,依然可以使用函数计算新位置的编码值。
缺点:函数型位置编码中并没有可以训练的参数,因而限制了位置编码的自由度。
-
表格型位置编码根据训练数据中最长语句的长度L建立一个L × dmodel 的编码表,作为参数进行训练
优点:灵活
缺点:测试时无法处理长度大于L的语句
残差网络
residual network,目的是降低计算导数时链式法则路径的平均长度。
GPT本身
GPT模型第一次做到了替代目标任务模型的主体部分。
模型利用字节对编码(BPE)对文本进行分词。然后,GPT使用滑动窗口的概念,即通过文本中第i-1, i-2, …, i-k个词预测第i个词。We为字典单词向量矩阵,在模型利用最后一层的结果预测下一个词ui的时候,用了P(u)=softmax(hi-1 WeT),这里复用了We,这也是 语言模型中的常用技巧。
微调的话,在GPT模型后加入简单的输出层,继续训练3论左右即可。
在微调时加入语言模型损失函数能有效提高模型在目标任务上的准确度,即使用如下的损失函数L3:L3 = L2© + λ*L1©,L1是预训练语言模型损失函数,L2是模型目标损失函数。
划时代的BERT
输入是一段文本中每个单词的词向量(分词由WordPiece生成,类似于BPE),输出是每个单词的BERT编码。BERT模型采用了两个预训练任务:双向语言模型和判断下一段文本。这两个任务均属于无监督学习,即只需要文本语料库,不需要任何人工标注数据。
BERT的创新之处在于:第一,利用掩码设计实现了双向语言模型,这更加符合人类理解文本的原理;第二,通过判断下一段文本增强了BERT分类能力,提高了预训练任务与目标任务的契合度。
双向语言模型
只有单层transformer才能在第i个位置的输出编码不依赖于单词i的信息,因为第二层transformer的时候,zi=f(y1,y2,…,yi-1,yi=1,…,yn),但是这些y向量中已经包含了xi的信息!这样就会导致zi不能用来预测第i个位置的单词!为了解决这个问题,BERT提出了掩码(masking)机制,就是在一段文本中随机挑选15%的单词,以掩码符号[mask]代替。利用多层Transformer机制预测这些位置的单词。由于输入被mask的单词没有任何信息,这些位置上的Transformer输出可以用来预测对应的单词。因此BERT是一个双向语言模型。但是为了预防预训练任务与之后的目标任务产生不一致,所以用80%-10%-10%的概率策略选择单词存留。
NSP
设起始符[CLS]位置的BERT编码为xcls,则模型预测B文本是A文本的下一段文本的概率为σ(W*xcls), W为参数矩阵
具体任务
BERT迁移到文本分类型任务时,需要将所有信息拼接成一段文本,然后在BERT模型上添加一个前向网络,将[CLS]位置对应的BERT编码h0转化成得分。
在序列标志型任务,比如区间答案型阅读理解任务中,定义BERT输入为[CLS] Q [SEP] P。然后分别计算答案在文本每个位置开始概率和结束概率,然后将这些概率与标准答案的位置输入交叉熵损失函数进行训练。
在以上两种任务的微调训练中,BERT自身的参数和添加的前向网络参数均需要训练,但一般只需要在目标任务上训练2~4轮。
# 安装包含在BERT在内的Transformer软件包
$ pip install pytorch-transformers
import torch
from pytorch_transformers import *
# 使用bert-base模型,不区分大小写
config = BertConfig.from_pretrained('bert-base-uncased')
# bert使用的分词工具
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 载入为区间答案型阅读理解任务预设的模型,包括前向网络输出层
model = BertForQuestionAnswering(config)
# 处理训练数据
# 获得文本分词后的单词编号,维度为 batch_size(1) * seg_length(4)
input_ids = torch.tensor(tokenizer.encode('this is an example')).unsqueeze(0)
# 标准答案在文本中的起始位置和终止位置,维度为batch_size
start_positions = torch.tensor([1])
end_positions = torch.tensor([3])
# 获得模型的输出结果
outputs = model(input_ids, start_positions=start_positions, end_positions=end_positions)
# 得到交叉熵损失函数值loss,以及模型预测答案在每个位置开始和结束的打分start_scores与end_scores, 维度均为batch_size(1) * seq_length
loss, start_scores, end_scores = outputs
BERT的改进措施【重要】
在BERT出现之后,对于新的模型架构的研究相对减少,研究者更多关注的是如何在给定BERT模型的情况下,改进训练数据的收集方法、预训练和微调的模式等
-
更多预训练任务
比如改进了掩码的使用方式,利用掩码代替短语或句子,而非单个单词
-
多任务微调
在微调阶段,可以对多个目标任务同时进行训练,即将多种类型任务的数据混合起来进行训练。这些任务共享BERT的基本网络结构,但各自拥有和自身任务相关的前向网络输出层。这些目标任务彼此之间不必相似,可以包括阅读理解、语句相似度判断、语句释义等多种类型。实验表明,多任务微调可以提高模型在每个子任务上的表现。
-
多阶段处理
可以先在和目标任务相关的语料上继续预训练BERT,再针对目标任务(比如医疗、法律)进行微调。
-
将BERT作为编码层
由于BERT模型的规模巨大,在目标任务上微调也需要大量的计算资源。在资源有限的情况下,可以将BERT作为编码层,并固定其中的所有参数。之后,和ELMo模型类似,需要对BERT每一层Transformer的输出计算含参加权和,以便在后续网络层中使用。由于BERT的参数不参与训练,因而大大减少了对计算资源的需求。