Python算法总结(九)集成算法
注:本篇文章不涉及模型参数调优。参数调优是一个重要的大话题。
1、什么是集成算法?
多个模型集成在一起的模型叫做集成评估器ensemble estimator,组成集成评估器的每个模型都叫做基评估器base estimator或弱学习器。
2、集成算法有哪些?
装袋法Bagging
提升法Boosting
堆叠法Stacking
3、什么是装袋法Bagging?
Bagging选用相同的弱学习器作为基模型,每个基模型的训练数据不是全部的数据集,而是通过“有放回的随机抽样”得到的随机子集,预测时各个基模型进行权重投票,是一种并行的训练结构。袋装法的典型代表是随机森林。
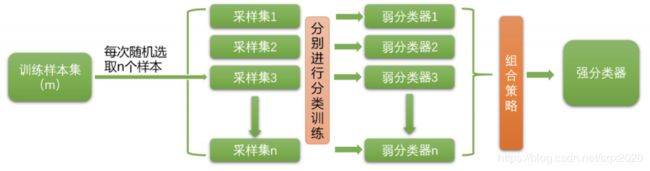
4、什么是随机森林Random Forest?
随机森林是Bagging的一种改进。
随机体现在:样本选择的随机性,特征选择的随机性。
森林体现在:所有弱分类器都是分类回归树(CART二叉树)。
随机森林的特点:对异常值不敏感,模型不易过拟合,要求基模型准确率大于0.5。
随机森林包含随机森林分类器、随机森林回归器。
随机森林的用途:可用于特征筛选。
5、什么是提升法Boosting?
Boosting选用相同的弱分类器作为基模型,依次训练模型,每个基模型的训练数据会根据前一个基模型的预测结果进行调整。后一个基模型会重点关注前一个基模型预测错误的样本,逐步修正前面基模型的误差。最终的预测结果通过基模型的线性组合来产生,是一种串行的结构。提升法的典型代表有Adaboost、XGBoost。
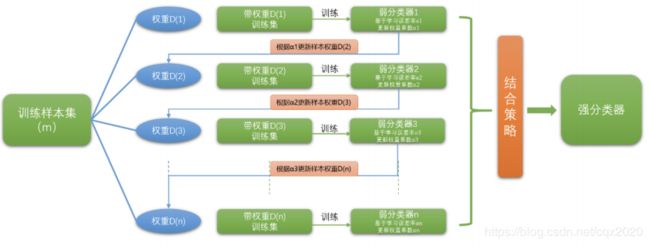
6、什么是Adaboost?
Adaboost是Adaptive Boosting自适应增强的缩写。自适应体系在:前一个基分类器分错的样本会得到加强(即更高权重),加权后的全体样本再次被用来训练下一个基本分类器。同时,在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数,算法停止。
Adaboost包含Adaboost分类器、Adaboost回归器。
(可参考另一篇文章《Python算法总结(七)Adaboost(附手写python实现代码)》)
7、什么是XGBoost?
(太难了,还没搞理解算法原理,待补充。据说XGBoost非常强大!)
XGBoost参数调优的讲解视频:B站/菜菜
8、Adaboost与XGBoost的区别?
(太难了,还没搞懂,待补充。)
9、Bagging装袋法与Boosting提升发的差异?
(1)样本选择
Bagging:有放回选取,每轮训练集之间是独立的
Boosting:每一轮的训练集不变,但样本权重发生变化
(2)样本权重
Bagging:每个样本的权重相等
Boosting:根据错误率不断调整样本权重,错误率越大则权重越大
(3)弱学习器权重
Bagging:所有弱学习器的权重相等
Boosting:误差小的弱学习器会有更大的权重
(4)并行计算
Bagging:并行训练,可节省时间
Boosting:串行训练
(5)过拟合与欠拟合
如果单个弱学习器过拟合,Bagging可缓解过拟合问题,Boosting可能加剧过拟合问题。
如果单个弱学习器学习能力较弱,Bagging可能无法提升模型表现,Boosting有可能提升模型表现。
(6)算法目标
Bagging:降低方差,提高模型整体的稳定性。
Boosting:降低偏差,提高模型整体的精确度accuracy。
其中,俩者都可以提高模型的精确度。在大多数数据集中,Boosting的精度更好。
10、集成算法的决策策略?
(1)回归问题
采用加权平均法得到最终的回归输出。

(2)分类问题
采用加权投票法得到最终的分类输出。
(3)学习法
在stacking中,对弱分类器的输出再加一层学习器。
11、Python库
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import RandomForestRegressor
pip install xgboost
import xgboost
有2种方式可以使用xgboost库。
第一种方式,直接使用xgboost库自己的建模流程。
step1:读取数据xgboost.DMatrix()
step2:设置参数param={}
step3:训练模型bst=xgboost.train(param)
step4:预测结果bst.predict()
第二种方式,使用xgboost库种的sklearnAPI
xgboost.XGBClassifier(
#弱评估器参数max_depth=3,
#集成算法参数learning_rate=0.1,
#集成算法参数n_estimators=100,
verbosity=1,
#集成算法参数silent=None,
#弱评估器参数objective=‘binary:logistic’,
#弱评估器参数booster=‘gbtree’,
#其他参数n_jobs=1,
#其他参数nthread=None,
#弱评估器参数gamma=0,
#弱评估器参数min_child_weight=1,
#弱评估器参数max_delta_step=0,
#集成算法参数subsample=1,
#弱评估器参数colsample_bytree=1,
#弱评估器参数colsample_bylevel=1,
#弱评估器参数colsample_bynode=1,
#弱评估器参数reg_alpha=0,
#弱评估器参数reg_lambda=1,
#其他参数scale_pos_weight=1,
#其他参数base_score=0.5,
#其他参数random_state=0,
#其他参数seed=None,
#其他参数missing=None,
**kwargs,
)