深蓝学院点云公开课《基于三维点云场景的语义及实例分割》(RandLA-Net、3D-BoNet)笔记
该笔记来源于深蓝学院公开课基于三维点云场景的语义及实例分割.
-
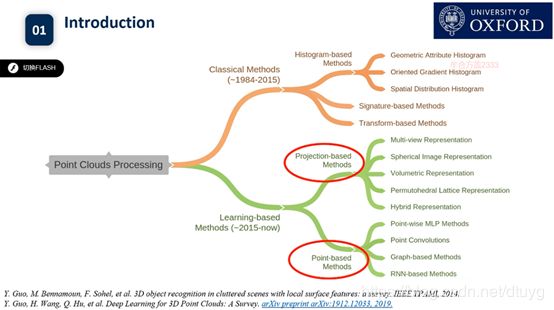
介绍之前的点云工作
-
介绍大场景三维点云的语义分割方法RandLA-Net。
1)目标
大多数方法如pointnet,pointnet++,pointcnn等只是处理小范围(如4k个点的1m×1m blocks),少量方法可处理大场景,但它们依赖于耗时的预处理或昂贵的体素化的步骤,预处理的时候进行了切块,把本该连一起的点云切开了,切开的部分可能成了不同的预测,网络可能没有学习到点云的几何信息,而是在拟合信息。
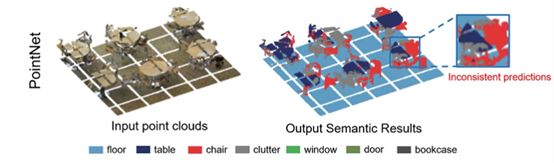
尝试用处理小范围的方法扩展至大范围。经过试验,pointnet方法在处理尺度越来越大的点云时准确性明显持续下降,原因是pointnet是里主要学习了独立的点的特征,没有学到本身的几何关系的信息,用来考虑整体特征的操作只是max-pooling,然而点数越大max-pooling丢掉的信息越多;pointnet++方法在处理尺度越来越大的点时准确性有所提升,然而计算速度确越来越慢,pointnet++的farthest point samping的模块的处理速度与点数是二次方的关系。
处理大场景点云结构的问题有点云的几何结构更加复杂;GPU容量的限制;深度传感器得到的点云数据的空间大小和点的数量是不确定的,我们希望可以直接处理而不是经过一些切割办法。RandLA-Net的方法的目标为:处理大场景点云,不经过分割的操作尽可能保留原来的几何特征;计算的效率较高,没有耗时的预处理或耗容量的体素化;提升准确性,对不同尺度的点云能捕捉提取到几何信息。
2)基本思路:
对大尺度的点云的特征集进行下采样,保留有能准确识别的关键特征。则需要更高效的点采样方法(减少计算损耗)和更高效的local feature aggregation来捕捉几何特征。
从采样方法来看,目前的采样方法可分为两类,一类是启发类的算法,及根据人为经验设计的算法

另一类是基于学习的算法

经过考量,采用random sampling方法。
为了保存有用的信息,提出了local feature aggregation(LFA)
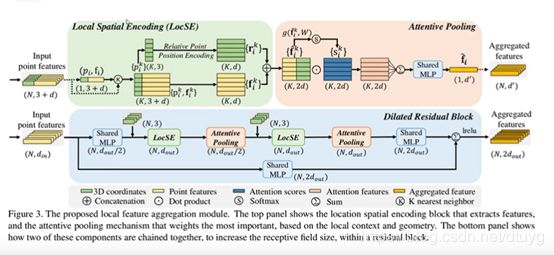
在local spatial encoding模块,为学习到近邻特征,先找到一些最近的neighbor集,将一个点的xyz作为三个通道类似于rgb输入到网络,同时它的neighbor的xyz坐标以及相对位置和欧氏距离encode后也被输入网络,得到的特征再与原来的特征结合到一起

在attentive pooling模块,对于feature用softmax的方式学到一个“掩膜”,(类似于加到原始的feature上的效果),重要的feature就可以学到大一点的weight。加权后,然后通过weighted summation把多个临近点特征的 f i k ^ \ \hat{f^{k}_{i}} fik^和 s i k \ s^{k}_{i} sik相乘后aggregate在一起,得到一行的特征,再通过shared mlp把该行特征降维到 d ′ \ d' d′。以上是一个点的情况,多个点就有了 A g g r e g a t e d \ Aggregated Aggregated f e a t u r e s \ features features
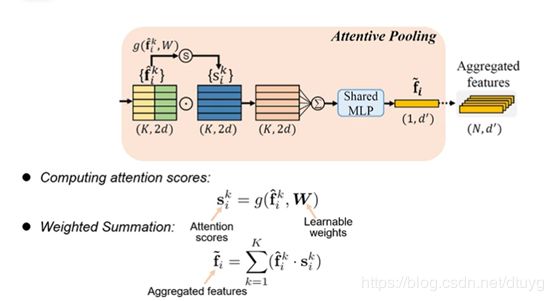
在dilated residual block模块,为了让ramdom sampling也能有好的准确率,希望每个点的residual block越来越大,这样便可encoder越来越多的信息。把上述两种模块结合在一起,图解说明,该方式等价于增大了residual
block的方式
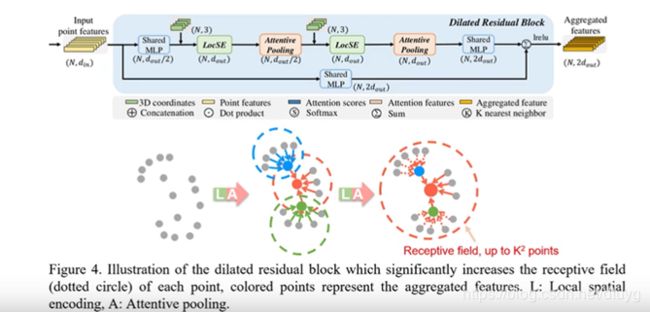
RandLA-Net的结构如下

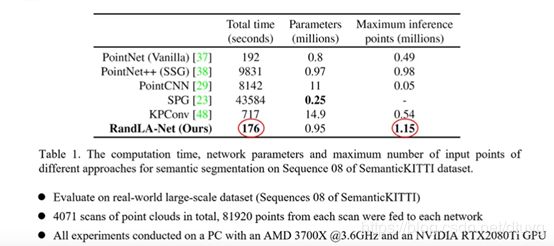
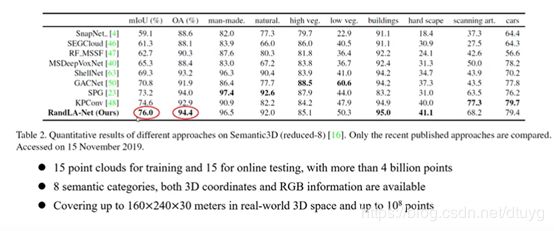
该网络的效果如下
3.介绍三维点云的实例分割3D-BoNet
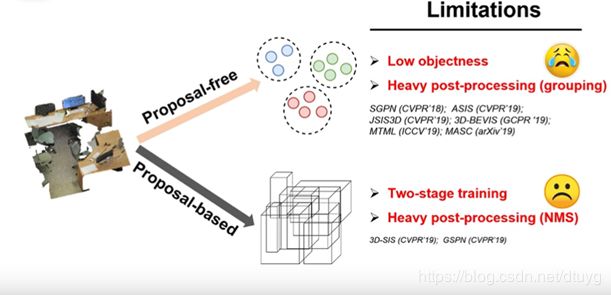
平面的实例分割方法有mask rcnn准确率较高,平面的方法很难用到三维上,而三维的目前少有框架处理实例分割。目前三维实例分割的工作有两种方向
1)目标
希望使网络是one-stage的训练,一次性把所有物体分割出来,为避免先训一截网络再训一截网络来缩短时间及减少调参操作;希望不像2D框架那样有锚点关键点。挑战为每帧的物体的数量不定;物体的顺序不定;少有成熟的网络借鉴
2)基本想法
直接检测少量的物体,直接预测少量的边框,使用global feature直接预测少量的边界箱,每个边框里直接做二分,这样不会轻易把一个角落的东西和另一个角落的东西认为是一个

在对边界框的预测时,global feature可以由pointnet或pointnet++得到,然后直接预测指定数量的框的位置,并给框打分。预测出来边框后交给下面每个点,用mlp对每个点做个分类
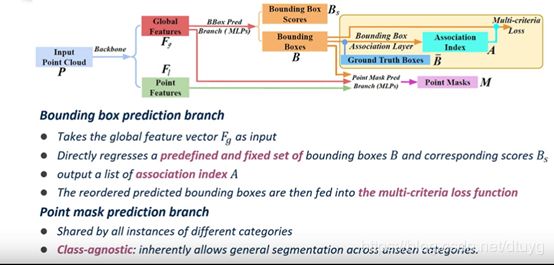
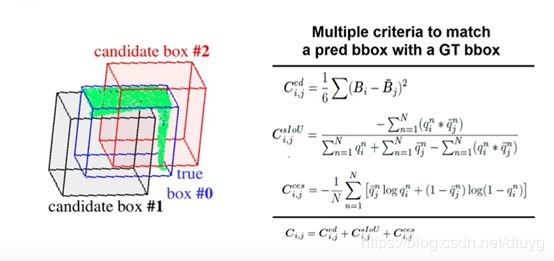
至于如何预测边框,假设学习H个边框,每个框用最小顶点和最大顶点的xyz6个值表示,则一共学习H个分数和6H个值即可。难点在于如何监督该网络学边框

匹配一个箱主要考虑:顶点欧氏距离,重合度,更大的框(使点圈得更中心)
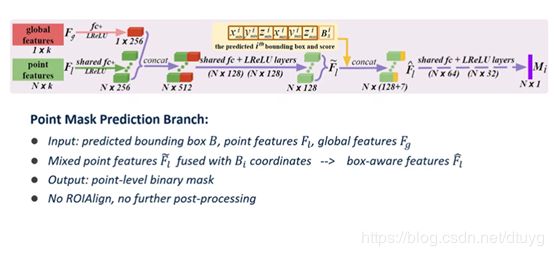
在point mask prediction时,将得到的7个值给每个点,classify这些点是属于前景点还是背景点。使用shared全连接层,但后面implement时是同时的。接着便可训练网络。
对于整体的代价函数,匹配好边框后便要最小化代价函数,但是只是监督配对上的,并且尽量使没匹配上的分数变为0,匹配上的变为1的方向变化。加上其他的代价得到整体的代价函数

在ScanNet上的表现如下
