Flink——原理与实战:AggregateFunction
一 aggregate()函数
Flink 的AggregateFunction是一个基于中间计算结果状态进行增量计算的函数。由于是迭代计算方式,所以,在窗口处理过程中,不用缓存整个窗口的数据,所以效率执行比较高。
该函数会将给定的聚合函数应用于每个窗口和键。 对每个元素调用聚合函数,以递增方式聚合值,并将每个键和窗口的状态保持在一个累加器中。
def aggregate[ACC: TypeInformation, R: TypeInformation](
aggregateFunction: AggregateFunction[T, ACC, R]): DataStream[R] = {
val accumulatorType: TypeInformation[ACC] = implicitly[TypeInformation[ACC]]
val resultType: TypeInformation[R] = implicitly[TypeInformation[R]]
asScalaStream(javaStream.aggregate(
clean(aggregateFunction), accumulatorType, resultType))
}
参数类型:AggregateFunction接口。该接口的继承关系和方法如下:
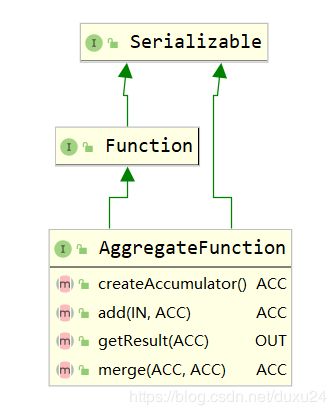
AggregateFunction需要复写的方法有:
- createAccumulator:创建一个新的累加器,开始一个新的聚合。累加器是正在运行的聚合的状态。
- add:将给定的输入添加到给定的累加器,并返回新的累加器值。
- getResult:从累加器获取聚合结果。
- merge:合并两个累加器,返回合并后的累加器的状态。
二 案例
从SocketSource接收数据,时间语义采用ProcessingTime,通过Flink 时间窗口以及aggregate方法统计用户在24小时内的平均消费金额。
代码
package org.ourhome.streamapi
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
/**
* @Author Do
* @Date 2020/4/24 22:51
*/
object WindowFunctionAggrectionTest {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
env.setParallelism(1)
val socketData: DataStream[String] = env.socketTextStream("local", 9999)
socketData.print("input ")
socketData.map(line => {
ConsumerMess(line.split(",")(0).toInt, line.split(",")(1).toDouble)
})
.keyBy(_.userId)
.timeWindow(Time.hours(24))
.aggregate(new MyAggregrateFunction)
.print("output ")
env.execute()
}
case class ConsumerMess(userId:Int, spend:Double)
// The type of the values that are aggregated (input values)
// The type of the accumulator (intermediate aggregate state).
// The type of the aggregated result
class MyAggregrateFunction extends AggregateFunction[ConsumerMess, (Int, Double), Double] {
override def createAccumulator(): (Int, Double) = (0, 0)
override def add(value: ConsumerMess, accumulator: (Int, Double)): (Int, Double) = {
(accumulator._1 + 1, accumulator._2 + value.spend)
}
override def getResult(accumulator: (Int, Double)): Double = {
accumulator._2/accumulator._1
}
override def merge(a: (Int, Double), b: (Int, Double)): (Int, Double) = {
(a._1 + b._1, b._2 + a._2)
}
}
}
输入
nc -lk 9999
123,666
123,456
123,12
123,3
123,46
123,666
输出
input > 123,666
input > 123,456
output > 561.0
input > 123,12
input > 123,3
input > 123,46
input > 123,666
output > 181.75
根据输出可见:
- 第一个窗口内,也就是第一个24小时,用户“123”共有两次消费(input开头),第一次花费666元,第二次花费456元。在窗口触发并关闭后,统计出平均每次消费金额:(666+456)/2=561.0元。
- 第二个窗口内,也就是第二个24小时,用户“123”共有4次消费(input开头),每次消费分别为:12、3、46、666元。在窗口触发并关闭后,统计出平均每次消费金额:(12+3+46+666)/4=181.75元。