HRM人力资源管理平台技术总结
HRM人力资源管理平台技术总结
项目名称:
hrm人力资源管理系统
项目背景:
在如今互联网求职为主流求职的大环境下,各种招聘网站都在发光发热,但是普通的招聘网站仍存在一些问题:
求职者在求职时投递简历,收到面试官面试邀请后很可能应为没有经验或者没有足够的能力来胜任该工作导致被pass掉,久而久之会对自己的能力产生怀疑,对招聘者产生怀疑,不敢投递简历。
招聘者招聘面试者因为不清楚面试者能力,只能广面积撒网,导致招到很多不满意的求职者来进行面试,从而费时费力,还招不到满意的应聘者,而且会与求职产生恶性影响。
一些优秀的培训机构可能教学质量很好,但是宣传能力太差,无法拥有足够的学员来进行学习,导致机构的收益无法保证,而想学习的学员也无法准确招到优秀的培训机构进行学习。
本系统就是为了解决上诉问题而开发的一款B/S架构的软件,求职者可以在该平台上进行求职和培训课程购买。而招聘者可以在这个平台上进行招聘,也能和培训机构合作,从培训机构中直接招聘能够胜任岗位的员工。培训机构能够在该平台上进行课程的售卖,发布。该项目很好的解决了三方的问题。
项目技术:
1.该项目是一个B/S(浏览器/服务器)微服务架构的软件,项目后端通过SpringBoot进行项目开发,SpringCloud进行服务间的治理。前端通过基于Vue.js的element-ui进行展示。
2.本项目才去前后端分离的模式,后端采取maven多模块的方式进行搭建,通过合理的模块拆分,实现代码的复用。
3.使用mybatisplus代替mybayis实现基础crud,条件构造器,分页插件集成。
4.在集群和分布式环境下,必须使用分布式文件系统统一管理文件,该项目采用fastDFS进行管理
fastdfs工具类,通过该工具类即可操作fastdfs进行上传下载等操作
public class FastDfsApiOpr {
public static String CONF_FILENAME = FastDfsApiOpr.class.getClassLoader()
.getResource("fast_client.conf").getFile();
/**
* 上传文件
* @param file
* @param extName
* @return
*/
public static String upload(byte[] file,String extName) {
try {
ClientGlobal.init(CONF_FILENAME);
TrackerClient tracker = new TrackerClient();
TrackerServer trackerServer = tracker.getConnection();
StorageServer storageServer = null;
StorageClient storageClient = new StorageClient(trackerServer, storageServer);
NameValuePair nvp [] = new NameValuePair[]{
new NameValuePair("age", "18"),
new NameValuePair("sex", "male")
};
String fileIds[] = storageClient.upload_file(file,extName,nvp);
System.out.println(fileIds.length);
System.out.println("组名:" + fileIds[0]);
System.out.println("路径: " + fileIds[1]);
return "/"+fileIds[0]+"/"+fileIds[1];
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 上传文件
* @param extName
* @return
*/
public static String upload(String path,String extName) {
try {
ClientGlobal.init(CONF_FILENAME);
TrackerClient tracker = new TrackerClient();
TrackerServer trackerServer = tracker.getConnection();
StorageServer storageServer = null;
StorageClient storageClient = new StorageClient(trackerServer, storageServer);
String fileIds[] = storageClient.upload_file(path, extName,null);
System.out.println(fileIds.length);
System.out.println("组名:" + fileIds[0]);
System.out.println("路径: " + fileIds[1]);
return "/"+fileIds[0]+"/"+fileIds[1];
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 下载文件
* @param groupName
* @param fileName
* @return
*/
public static byte[] download(String groupName,String fileName) {
try {
ClientGlobal.init(CONF_FILENAME);
TrackerClient tracker = new TrackerClient();
TrackerServer trackerServer = tracker.getConnection();
StorageServer storageServer = null;
StorageClient storageClient = new StorageClient(trackerServer, storageServer);
byte[] b = storageClient.download_file(groupName, fileName);
return b;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
/**
* 删除文件
* @param groupName
* @param fileName
*/
public static void delete(String groupName,String fileName){
try {
ClientGlobal.init(CONF_FILENAME);
TrackerClient tracker = new TrackerClient();
TrackerServer trackerServer = tracker.getConnection();
StorageServer storageServer = null;
StorageClient storageClient = new StorageClient(trackerServer,
storageServer);
int i = storageClient.delete_file(groupName,fileName);
System.out.println( i==0 ? "删除成功" : "删除失败:"+i);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("删除异常,"+e.getMessage());
}
}
}
4.通过jedis将课程类型的数据存储到redis数据库中,之后查询便通过redis查询减少数据库压力,提高查询速度,给用户提供更好的体验。
public List loadDataTree() {
//1、从缓存中获取数据
AjaxResult result = redisClient.getStr(KEY);
if(!result.isSuccess()){
return null;
}
//2、判断缓存中的数据是否存在
String courseTypes = (String) result.getResultObj();
if(StringUtils.isEmpty(courseTypes)){
//缓存不存在
synchronized (this){
result = redisClient.getStr(KEY);
if(!result.isSuccess()){
return null;
}
courseTypes = (String) result.getResultObj();
if(StringUtils.isEmpty(courseTypes)){
logger.debug("缓存中没有数据,查询数据库并缓存......");
List courseTypeList = null;
//4、如果不存在,则查询数据库,将查询结果缓存到redis中
courseTypeList = loopMapCourseTypes();
String jsonString = JSONArray.toJSONString(courseTypeList);
redisClient.setStr(KEY,jsonString);
//5、再将结果返回
return courseTypeList;
}
}
}
logger.debug("从缓存中获取到了数据......");
//3、如果存在,则将缓存中获取的数据直接返回 - fastjson
List courseTypeList = JSONArray.parseArray(courseTypes, CourseType.class);
return courseTypeList;
}
5.使用Velocity模板技术,利用rabbitmq中间件接受数据改变的信息,对服务进行解耦,自动生成静态化页面,提高访问速度;
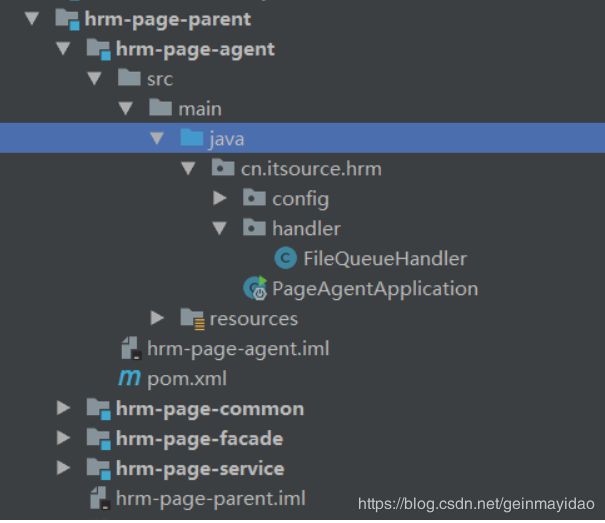
通过在页面服务中添加服务agent,集成rabbitmq,达到监听作用,当数据改变时,自动生成页面。
@Component
public class FileQueueHandler {
@Autowired
private FileClient fileClient;
@Value("${project.home.path}")
private String projectPath;
@RabbitListener(queues = {RabbitConfig.QUEUE_COURSE_HOME})
public void receive_email(String fileId, Message message, Channel channel) {
InputStream inputStream = null;
OutputStream outputStream = null;
//从fastdfs中下载文件
try {
Response response = fileClient.download(fileId);
Response.Body body = response.body();
inputStream = body.asInputStream();
//前端项目该文件的路径
outputStream = new FileOutputStream(projectPath);
IOUtils.copy(inputStream,outputStream);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (outputStream!=null)
outputStream.close();
if(inputStream!=null)
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
6.数据库使用到垂直分表的形式和反三范式的表设计;
在将课程的详细信息从课程表中抽取出来单独作为一张表,因为课程详细信息字段占用空间大,而且用户不会经常查看,只会对感兴趣的课程进行详细信息查询,但是如果不抽取出来,每次查询都会耗费很多时间,效率十分低。
在课程类型表中使用到反三范式,课程描述本来可以通过查询课程详细信息,但是冗余到课程类型中,达到以空间换时间的目的。
7.用户注册中通过集成hutool的图片验证接口和阿里云的短信验证接口实现。
阿里云短信验证的sdk代码
public void sendSMS(String phoneNum,String signName,String templateCode,String templateParam) throws ClientException {
DefaultProfile profile = DefaultProfile.getProfile("cn-hangzhou", SMSConst.ACCESS_KEY, SMSConst.SECRET);
IAcsClient client = new DefaultAcsClient(profile);
CommonRequest request = new CommonRequest();
request.setMethod(MethodType.POST);
request.setDomain("dysmsapi.aliyuncs.com");
request.setVersion("2017-05-25");
request.setAction("SendSms");
request.putQueryParameter("RegionId", "cn-hangzhou");
request.putQueryParameter("PhoneNumbers", phoneNum);
request.putQueryParameter("SignName", signName);
request.putQueryParameter("TemplateCode", templateCode);
request.putQueryParameter("TemplateParam", templateParam);
CommonResponse response = client.getCommonResponse(request);
}
项目中遇到的问题:
1.跨域问题
端口号从一个id->另一个端口或资源只要ip或者端口不同,都认定为不同的域,如果之间有资源访问,这种行为就叫做跨域访问。
解决:
因为微服务所有服务通过网关调用,因此在网关中添加过滤器类和配置
@Component
public class AccessTokenFilter extends ZuulFilter {
@Autowired
private RedisClient redisClient;
private Logger logger = LoggerFactory.getLogger(AccessTokenFilter.class);
/**
* 过滤器的类型,它决定过滤器在请求的哪个生命周期中执行。
* 这里定义为pre,代表会在请求被路由之前执行。
*
* @return
*/
@Override
public String filterType() {
return "pre";
}
/**
* filter执行顺序,通过数字指定。
* 数字越大,优先级越低。
*
* @return
*/
@Override
public int filterOrder() {
return 0;
}
/**
* 判断该过滤器是否需要被执行。这里我们直接返回了true,因此该过滤器对所有请求都会生效。
* 实际运用中我们可以利用该函数来指定过滤器的有效范围。
*
* @return
*/
@Override
public boolean shouldFilter() {
return true;
}
/**
* 过滤器的具体逻辑
*
* @return
*/
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
ctx.addZuulResponseHeader("Content-type", "text/json;charset=UTF-8");
ctx.getResponse().setCharacterEncoding("UTF-8");
String requestURI = request.getRequestURI();
logger.debug("*************请求地址:"+requestURI+"***************");
//放行
if(requestURI.contains("api-docs")||requestURI.contains("/sso/login")||requestURI.contains("/sso/register")){
return null;
}
//获取token请求头
String token = request.getHeader("token");
//验证请求头
if(StringUtils.isEmpty(token)) {
ctx.setSendZuulResponse(false);
ctx.setResponseBody(JSONObject.toJSONString(AjaxResult.me().setSuccess(false).setMessage("请先认证!")));
ctx.setResponseStatusCode(HttpStatus.UNAUTHORIZED.value());
}
//验证token的准确性
Boolean exists = (Boolean) redisClient.exists("ACCESS_TOKEN:"+token).getResultObj();
if(!exists){
ctx.setSendZuulResponse(false);
ctx.setResponseBody(JSONObject.toJSONString(AjaxResult.me().setSuccess(false).setMessage("token不正确!")));
ctx.setResponseStatusCode(HttpStatus.UNAUTHORIZED.value());
}
return null;
}
}
配置类:
@Configuration
public class GlobalCorsConfig {
@Bean
public CorsFilter corsFilter() {
//1.添加CORS配置信息
CorsConfiguration config = new CorsConfiguration();
//1) 允许的域,不要写*,否则cookie就无法使用了
//浏览器认为127.0.0.1和localhost不是同一个域
config.addAllowedOrigin("http://127.0.0.1:6001");
config.addAllowedOrigin("http://localhost:6001");
config.addAllowedOrigin("http://127.0.0.1:6002");
config.addAllowedOrigin("http://localhost:6001");
config.addAllowedOrigin("http://localhost:6003");
config.addAllowedOrigin("http://127.0.0.1:6003");
//2) 是否发送Cookie信息
config.setAllowCredentials(true);
//3) 允许的请求方式
config.addAllowedMethod("OPTIONS");
config.addAllowedMethod("HEAD");
config.addAllowedMethod("GET");
config.addAllowedMethod("PUT");
config.addAllowedMethod("POST");
config.addAllowedMethod("DELETE");
config.addAllowedMethod("PATCH");
// 4)允许的头信息
config.addAllowedHeader("*");
//2.添加映射路径,我们拦截一切请求
UrlBasedCorsConfigurationSource configSource = new
UrlBasedCorsConfigurationSource();
configSource.registerCorsConfiguration("/**", config);
//3.返回新的CorsFilter.
return new CorsFilter(configSource);
}
}
2.无限级别课程类型查询
在查询课程类型时,层级关系的查询常规方式是通过递归进行依次查询,但是存在
的问题一方面是万一层级太深,递归会导致栈溢出,因此采用循环+map的方式进行查询。另一方面是每次查询都会查询数据库,效率低。
解决:循环+map
private List loopMapCourseTypes(){
//创建一个List存放结果(一级类型)
List coursesTypes = new ArrayList<>();
//一次性查询出所有的类型数据
List allCoursetTypes = baseMapper.selectList(null);
//将所有类型放入map中,key为类型的id,value为当前类型对象
Map courseTypeMap = new HashMap<>();
for (CourseType coursetType : allCoursetTypes) {
courseTypeMap.put(coursetType.getId(),coursetType);
}
//嵌套循环
for (CourseType courseType : allCoursetTypes) {
if(courseType.getPid()==0){
//如果是一级类型,直接添加到结果里面去
coursesTypes.add(courseType);
}else{
//如果不是一级类型,则找到对应的父类型,添加到父类型的children属性中
CourseType parent = courseTypeMap.get(courseType.getPid());
if(parent!=null){
parent.getChildren().add(courseType);
}
}
}
return coursesTypes;
}
courseType.getPid()==0){
//如果是一级类型,直接添加到结果里面去
coursesTypes.add(courseType);
}else{
//如果不是一级类型,则找到对应的父类型,添加到父类型的children属性中
CourseType parent = courseTypeMap.get(courseType.getPid());
if(parent!=null){
parent.getChildren().add(courseType);
}
}
}
return coursesTypes;
}