分类算法实例二:用Softmax算法预测葡萄酒质量
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
import warnings
import sklearn
from sklearn.linear_model import LogisticRegressionCV
from sklearn.linear_model.coordinate_descent import ConvergenceWarning
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import label_binarize
from sklearn import metrics
# 设置字符集,防止中文乱码
mpl.rcParams['font.sans-serif']=[u'simHei']
mpl.rcParams['axes.unicode_minus']=False
# 拦截异常
warnings.filterwarnings(action = 'ignore', category=ConvergenceWarning)
# 读取数据
path1 = "datas/winequality-red.csv"
df1 = pd.read_csv(path1, sep=";")
# 设置数据类型为红葡萄酒
df1['type'] = 1
path2 = "datas/winequality-white.csv"
df2 = pd.read_csv(path2, sep=";")
# 设置数据类型为白葡萄酒
df2['type'] = 2
# 合并两个df
df = pd.concat([df1,df2], axis=0)
# 自变量名称
names = ["fixed acidity","volatile acidity","citric acid",
"residual sugar","chlorides","free sulfur dioxide",
"total sulfur dioxide","density","pH","sulphates",
"alcohol", "type"]
# 因变量名称
quality = "quality"
# 显示前5条数据
df.head(5)

# 异常数据处理
new_df = df.replace('?', np.nan)
# 只要有列为空,就进行删除操作
datas = new_df.dropna(how = 'any')
print ("原始数据条数:%d;异常数据处理后数据条数:%d;异常数据条数:%d" % (len(df), len(datas), len(df) - len(datas)))
# 提取自变量和因变量
X = datas[names]
Y = datas[quality]
![]()
# 1. 数据分割
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.25,random_state=0)
print ("训练数据条数:%d;数据特征个数:%d;测试数据条数:%d" % (X_train.shape[0], X_train.shape[1], X_test.shape[0]))
![]()
# 2. 数据归一化
ss = MinMaxScaler()
X_train = ss.fit_transform(X_train)
# 查看y值的范围和数据
Y_train.value_counts()
# 3. 模型构建及训练
# penalty: 过拟合解决参数,l1或者l2
# solver: 参数优化方式
# 当penalty为l1的时候,参数只能是:liblinear(坐标轴下降法);
# 当penalty为l2的时候,参数可以是:lbfgs(拟牛顿法)、newton-cg(牛顿法变种)
# multi_class: 分类方式参数;参数可选: ovr(默认)、multinomial;这两种方式在二元分类问题中,效果是一样的;在多元分类问题中,效果不一样
# ovr: one-vs-rest, 对于多元分类的问题,先将其看做二元分类,分类完成后,再迭代对其中一类继续进行二元分类
# multinomial: many-vs-many(MVM),对于多元分类问题,如果模型有T类,我们每次在所有的T类样本里面选择两类样本出来,不妨记为T1类和T2类,
# 把所有的输出为T1和T2的样本放在一起,把T1作为正例,T2作为负例,进行二元逻辑回归,得到模型参数。我们一共需要T(T-1)/2次分类
# class_weight: 特征权重参数
# Softmax算法相对于Logistic算法来讲,在sklearn中体现的代码形式来讲,主要只是参数的不同而已
# Logistic算法回归(二分类)使用的是ovr;如果是softmax回归,建议使用multinomial
lr = LogisticRegressionCV(fit_intercept=True, Cs=np.logspace(-5, 1, 100),
multi_class='multinomial', penalty='l2', solver='lbfgs')
lr.fit(X_train, Y_train)

# 4. 模型效果获取
r = lr.score(X_train, Y_train)
print("R值:", r)
print("特征稀疏化比率:%.2f%%" % (np.mean(lr.coef_.ravel() == 0) * 100))
print("参数:",lr.coef_)
print("截距:",lr.intercept_)

# 5. 数据预测
# a. 使用标准化模型进行预测数据格式化(归一化)
X_test = ss.transform(X_test)
# b. 结果数据预测
Y_predict = lr.predict(X_test)
# c. 图表展示
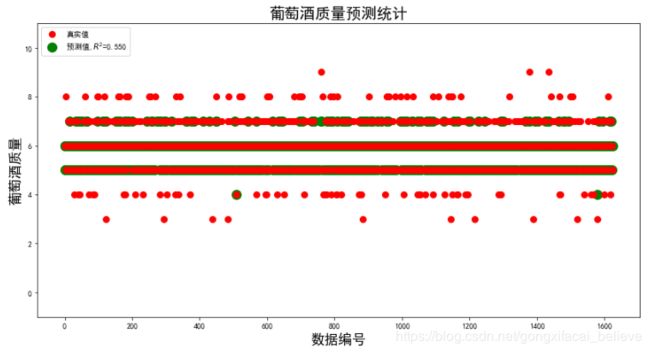
x_len = range(len(X_test))
plt.figure(figsize=(14,7), facecolor='w')
plt.ylim(-1,11)
plt.plot(x_len, Y_test, 'ro',markersize = 8, zorder=3, label=u'真实值')
plt.plot(x_len, Y_predict, 'go', markersize = 12, zorder=2, label=u'预测值,$R^2$=%.3f' % lr.score(X_train, Y_train))
plt.legend(loc = 'upper left')
plt.xlabel(u'数据编号', fontsize=18)
plt.ylabel(u'葡萄酒质量', fontsize=18)
plt.title(u'葡萄酒质量预测统计', fontsize=20)
plt.show()
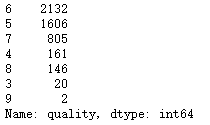
# 查看数据分布情况
[len(df[df.quality == i]) for i in range(11)]
![]()
df.quality.value_counts()

# 对数据进行降维处理后建模,查看效果:使用PCA降维(有时候进行特征抽取和数据降维对于模型的算法是没有太好的改进的)
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import Normalizer
# 1. 数据分割
X1_train,X1_test,Y1_train,Y1_test = train_test_split(X,Y,test_size=0.025,random_state=0)
print ("训练数据条数:%d;数据特征个数:%d;测试数据条数:%d" % (X1_train.shape[0], X1_train.shape[1], X1_test.shape[0]))
# 2. 数据特征转换(归一化)
ss2 = Normalizer()
# 训练模型及归一化数据
X1_train = ss2.fit_transform(X1_train)
# 3. 特征选择,只考虑3个维度
# skb = SelectKBest(chi2, k=3)
# 训练模型及特征选择
# X1_train = skb.fit_transform(X1_train, Y1_train)
# 4. 降维
# 将样本数据维度降低成为2个维度
# pca = PCA(n_components=5)
# X1_train = pca.fit_transform(X1_train)
# print("贡献率:", pca.explained_variance_)
# 5. 模型构建
lr2 = LogisticRegressionCV(fit_intercept=True, Cs=np.logspace(-5, 1, 100),
multi_class='multinomial', penalty='l2', solver='lbfgs')
lr2.fit(X1_train, Y1_train)
# 6. 模型效果输出
r = lr2.score(X1_train, Y1_train)
print("R值:", r)
print("特征稀疏化比率:%.2f%%" % (np.mean(lr2.coef_.ravel() == 0) * 100))
print("参数:",lr2.coef_)
print("截距:",lr2.intercept_)
# 7. 数据预测
# a. 预测数据格式化(归一化)
# 测试数据归一化
X1_test = ss2.transform(X1_test)
# 测试数据特征选择
# X1_test = skb.transform(X1_test)
# 测试数据降维
# X1_test = pca.fit_transform(X1_test)
# b. 结果数据预测
Y1_predict = lr2.predict(X1_test)
# c. 图表展示
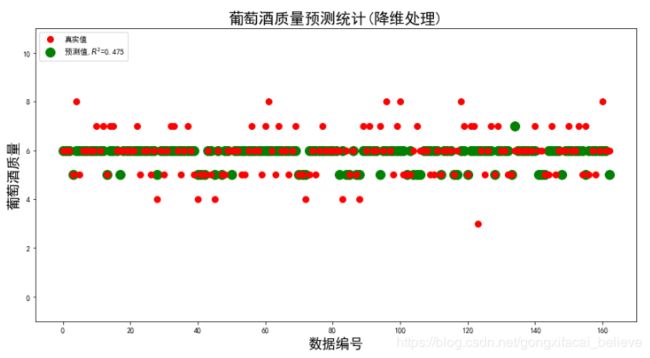
x1_len = range(len(X1_test))
plt.figure(figsize=(14,7), facecolor='w')
plt.ylim(-1,11)
plt.plot(x1_len, Y1_test, 'ro',markersize = 8, zorder=3, label=u'真实值')
plt.plot(x1_len, Y1_predict, 'go', markersize = 12, zorder=2, label=u'预测值,$R^2$=%.3f' % lr2.score(X1_train, Y1_train))
plt.legend(loc = 'upper left')
plt.xlabel(u'数据编号', fontsize=18)
plt.ylabel(u'葡萄酒质量', fontsize=18)
plt.title(u'葡萄酒质量预测统计(降维处理)', fontsize=20)
plt.show()