【Flink】Flink中的窗口函数、时间语义及watermark
1、支持的数据类型
Flink 流应用程序处理的是以数据对象表示的事件流。所以在 Flink 内部,我们需要能够处理这些对象。它们需要被序列化和反序列化,以便通过网络传送它们;或者从状态后端、检查点和保存点读取它们。为了有效地做到这一点,Flink 需要明确知道应用程序所处理的数据类型。Flink 使用类型信息的概念来表示数据类型,并为每个数据类型生成特定的序列化器、反序列化器和比较器。
Flink 还具有一个类型提取系统,该系统分析函数的输入和返回类型,以自动获取类型信息,从而获得序列化器和反序列化器。但是,在某些情况下,例如 lambda 函数或泛型类型,需要显式地提供类型信息,才能使应用程序正常工作或提高其性能。
Flink 支持 Java 和 Scala 中所有常见数据类型。使用最广泛的类型有以下几种。
基础数据类型
Flink 支持所有的 Java 和 Scala 基础数据类型,Int, Double, Long, String, …
val numbers: DataStream[Long] = env.fromElements(1L, 2L, 3L, 4L)
numbers.map( n => n + 1 )
Java 和 Scala 元组(Tuples)
val persons: DataStream[(String, Integer)] = env.fromElements(
("Adam", 17),
("Sarah", 23) )
persons.filter(p => p._2 > 18)
Scala 样例类(case class)
case class Person(name: String, age: Int)
val persons: DataStream[Person] = env.fromElements(
Person("Adam", 17),
Person("Sarah", 23) )
persons.filter(p => p.age > 18)
Java 简单对象(POJO)
public class Person {
public String name;
public int age;
public Person() {}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}
DataStream persons = env.fromElements(
new Person("Alex", 42),
new Person("Wendy", 23));
其它(Arrays,Lists,Maps,Enums, 等等)
Flink 对 Java 和 Scala 中的一些特殊目的的类型也都是支持的,比如 Java 的 ArrayList,HashMap,Enum 等等。
2、实现 UDF 函数——更细粒度的控制流
函数类(Function Classes)
Flink 暴露了所有 udf 函数的接口(实现方式为接口或者抽象类)。例如
MapFunction,FilterFunction,ProcessFunction 等等。
下面例子实现了 FilterFunction 接口:
class FilterFilter extends FilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains("flink")
}
}
val flinkTweets = tweets.filter(new FlinkFilter)
还可以将函数实现成匿名类:
val flinkTweets = tweets.filter(
new RichFilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains("flink")
}
}
)
我们 filter 的字符串"flink"还可以当作参数传进去。
val tweets: DataStream[String] = ...
val flinkTweets = tweets.filter(new KeywordFilter("flink"))
class KeywordFilter(keyWord: String) extends FilterFunction[String] {
override def filter(value: String): Boolean = {
value.contains(keyWord)
}
}
匿名函数(Lambda Function)
val tweets: DataStream[String] = ...
val flinkTweets = tweets.filter(_.contains("flink"))
富函数(Rich Function)
“富函数”是 DataStream API 提供的一个函数类的接口,所有 Flink 函数类都
有其 Rich 版本。它与常规函数的不同在于,可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能。
- RichMapFunction
- RichFlatMapFunction
- RichFilterFunction
Rich Function 有一个生命周期的概念。典型的生命周期方法有:
- open()方法是 rich function 的初始化方法,当一个算子例如 map 或者 filter 被调用之前 open()会被调用。
- close()方法是生命周期中的最后一个调用的方法,做一些清理工作。
- getRuntimeContext()方法提供了函数的 RuntimeContext 的一些信息,例如函数执行的并行度,任务的名字,以及 state 状态
class MyFlatMap extends RichFlatMapFunction[Int, (Int, Int)] {
var subTaskIndex = 0
override def open(configuration: Configuration): Unit = {
subTaskIndex = getRuntimeContext.getIndexOfThisSubtask
// 以下可以做一些初始化工作 , 例如建立一个和 HDFS 的连接
}
override def flatMap(in: Int, out: Collector[(Int, Int)]): Unit = {
if (in % 2 == subTaskIndex) {
out.collect((subTaskIndex, in))
}
}
override def close(): Unit = {
// 以下做一些清理工作,例如断开和 HDFS 的连接。
}
}
2、Sink
Flink 没有类似于 spark 中 foreach 方法,让用户进行迭代的操作。虽有对外的输出操作都要利用 Sink 完成。最后通过类似如下方式完成整个任务最终输出操作。
stream.addSink(new MySink(xxxx))
官方提供了一部分的框架的 sink。除此以外,需要用户自定义实现 sink。

Kafka
pom.xml
< dependency>
< groupId>org.apache.flink
< artifactId>flink-connector-kafka-0.11_2.11
< version>1.7.2
主函数中添加 sink:
val union = high.union(low).map(_.temperature.toString)
union.addSink(new FlinkKafkaProducer011[String]("localhost:9092", "test", new SimpleStringSchema()))
Redis
pom.xml
< dependency>
< groupId>org.apache.bahir
< artifactId>flink-connector-redis_2.11
< version>1.0
定义一个 redis 的 mapper 类,用于定义保存到 redis 时调用的命令:
class MyRedisMapper extends RedisMapper[SensorReading]{
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET, "sensor_temperature")
}
override def getValueFromData(t: SensorReading): String = t.temperature.toString
override def getKeyFromData(t: SensorReading): String = t.id
}
val conf = new FlinkJedisPoolConfig.Builder().setHost("localhost").setPort(6379).build()
dataStream.addSink( new RedisSink[SensorReading](conf, new MyRedisMapper) )
Elasticsearch
pom.xml
org.apache.flink
flink-connector-elasticsearch6_2.11
1.7.2
在主函数中调用:
val httpHosts = new util.ArrayList[HttpHost]()
httpHosts.add(new HttpHost("localhost", 9200))
val esSinkBuilder = new ElasticsearchSink.Builder[SensorReading]( httpHosts, new ElasticsearchSinkFunction[SensorReading] {
override def process(t: SensorReading, runtimeContext: RuntimeContext, requestIndexer: RequestIndexer): Unit = {
println("saving data: " + t)
val json = new util.HashMap[String, String]()
json.put("data", t.toString)
val indexRequest = Requests.indexRequest().index("sensor").`type`("readingData").source(json)
requestIndexer.add(indexRequest)
println("saved successfully")
}
})
dataStream.addSink( esSinkBuilder.build() )
JDBC 自定义 sink
pom.xml
mysql
mysql-connector-java
5.1.44
添加 MyJdbcSink:
class MyJdbcSink() extends RichSinkFunction[SensorReading]{
var conn: Connection = _
var insertStmt: PreparedStatement = _
var updateStmt: PreparedStatement = _
// open 主要是创建连接
override def open(parameters: Configuration): Unit = {
super.open(parameters)
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123456")
insertStmt = conn.prepareStatement("INSERT INTO temperatures (sensor, temp) VALUES (?, ?)")
updateStmt = conn.prepareStatement("UPDATE temperatures SET temp = ? WHERE sensor = ?")
}
// 调用连接,执行 sql
override def invoke(value: SensorReading, context: SinkFunction.Context[_]): Unit = {
updateStmt.setDouble(1, value.temperature)
updateStmt.setString(2, value.id)
updateStmt.execute()
if (updateStmt.getUpdateCount == 0) {
insertStmt.setString(1, value.id)
insertStmt.setDouble(2, value.temperature)
insertStmt.execute()
}
}
override def close(): Unit = {
insertStmt.close()
updateStmt.close()
conn.close()
}
}
在 main 方法中增加,把明细保存到 mysql 中:
dataStream.addSink(new MyJdbcSink())
3、Window
Window 概述
streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 window 是一种 切割无限数据流为有限块进行处理的手段。
Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
Window 类型
Window 可以分成两类:
- CountWindow:按照指定的数据条数生成一个 Window,与时间无关。
- TimeWindow:按照时间生成 Window。
对于 TimeWindow,可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)。
滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口。 长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个 5 分钟大小的滚动窗口,窗口的创建如下图所示:
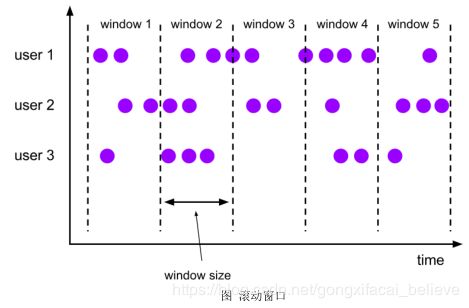
适用场景:适合做 BI 统计等(做每个时间段的聚合计算)。
滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定, 可以。 有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有 10 分钟的窗口和 5 分钟的滑动,那么每个窗口中 5 分钟的窗口里包含着上个 10 分钟产生的数据,如下图所示:
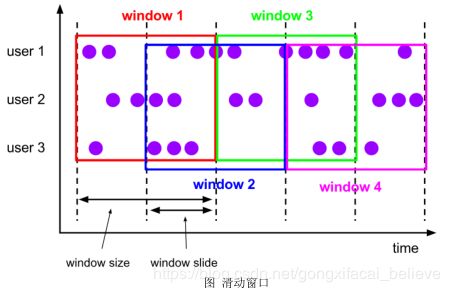
适用场景:对最近一个时间段内的统计(求某接口最近 5min 的失败率来决定是否要报警)。
会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的 session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去。
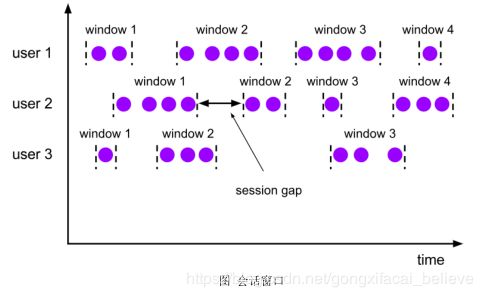
Window API
TimeWindow
TimeWindow 是将指定时间范围内的所有数据组成一个 window,一次对一个 window 里面的所有数据进行计算。
滚动窗口(TumblingEventTimeWindows )
Flink 默认的时间窗口根据 Processing Time 进行窗口的划分,将 Flink 获取到的数据根据进入 Flink 的时间划分到不同的窗口中。
val minTempPerWindow = dataStream
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
时间间隔可以通过 Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一个来指定。
滑动窗口(SlidingEventTimeWindows)
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是 window_size,一个是 sliding_size。
下面代码中的 sliding_size 设置为了 5s,也就是说,窗口每 5s 就计算一次,每一次计算的 window 范围是 15s 内的所有元素。
val minTempPerWindow: DataStream[(String, Double)] = dataStream
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.timeWindow(Time.seconds(15), Time.seconds(5))
.reduce((r1, r2) => (r1._1, r1._2.min(r2._2)))
.window(EventTimeSessionWindows.withGap(Time.minutes(10))
时间间隔可以通过 Time.milliseconds(x),Time.seconds(x),Time.minutes(x)等其中的一个来指定。
CountWindow
CountWindow 根据窗口中相同 key 元素的数量来触发执行,执行时只计算元素数量达到窗口大小的 key 对应的结果。
注意:CountWindow 的 window_size 指的是相同 Key 的元素的个数,不是输入的所有元素的总数。
滚动窗口
默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
val minTempPerWindow: DataStream[(String, Double)] = dataStream
.map(r => (r.id, r.temperature))
.keyBy(_._1)
.countWindow(5)
.reduce((r1, r2) => (r1._1, r1._2.max(r2._2)))
滑动窗口
滑动窗口和滚动窗口的函数名是完全一致的,只是在传参数时需要传入两个参数,一个是 window_size,一个是 sliding_size。
下面代码中的 sliding_size 设置为了 2,也就是说,每收到两个相同 key 的数据就计算一次,每一次计算的 window 范围是 5 个元素。
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream .map(r => (r.id, r.temperature)) .keyBy(0)
// 每当某一个 key 的个数达到 2 的时候 , 触发计算,计算最近该 key 最近 10 个元素的内容
val windowedStream: WindowedStream[(String, Int), Tuple, GlobalWindow] = keyedStream.countWindow(10,2)
val sumDstream: DataStream[(String, Int)] = windowedStream.sum(1)
window function
window function 定义了要对窗口中收集的数据做的计算操作,主要可以分为两类:
- 增量聚合函数(incremental aggregation functions)
每条数据到来就进行计算,保持一个简单的状态。典型的增量聚合函数有ReduceFunction,AggregateFunction。 - 全窗口函数(full window functions)
先把窗口所有数据收集起来,等到计算的时候会遍历所有数据。
ProcessWindowFunction 就是一个全窗口函数。
其它可选 API
- .trigger() —— 触发器
定义 window 什么时候关闭,触发计算并输出结果 - .evitor() —— 移除器
定义移除某些数据的逻辑 - .allowedLateness() —— 允许处理迟到的数据
- .sideOutputLateData() —— 将迟到的数据放入侧输出流
- .getSideOutput() —— 获取侧输出流

4、时间语义与 Watermark
Flink 中的时间语义
在 Flink 的流式处理中,会涉及到时间的不同概念,如下图所示:
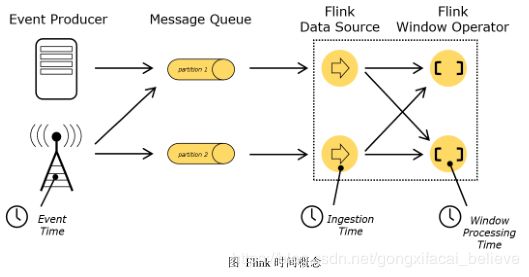
- Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
- Ingestion Time:是数据进入 Flink 的时间。
- Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
一个例子——电影《星球大战》:
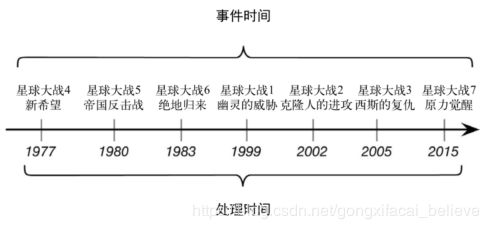
例如,一条日志进入 Flink 的时间为 2017-11-12 10:00:00.123,到达 Window 的系统时间为 2017-11-12 10:00:01.234,日志的内容如下:
2017-11-02 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计 1min 内的故障日志个数,哪个时间是最有意义的?
eventTime,因为我们要根据日志的生成时间进行统计。
EventTime 的引入
在 在 Flink 的流式处理中,绝大部分的业务都会使用 eventTime,一般只在
eventTime 无法使用时,才会被迫使用 ProcessingTime 或者 IngestionTime。
如果要使用 EventTime,那么需要引入 EventTime 的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给 env 创建的每一个 stream 追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
Watermark 的基本概念
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的,虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的。
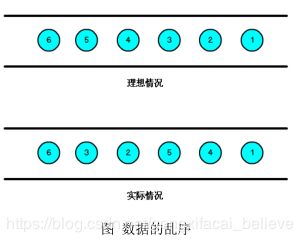
那么此时出现一个问题,一旦出现乱序,如果只根据 eventTime 决定 window 的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发 window 去进行计算了,这个特别的机制,就是 Watermark。
- Watermark 是一种衡量 Event Time 进展的机制。
- Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用
Watermark 机制结合 window 来实现。 - 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的。
- Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 eventTime 小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于 maxEventTime – t,那么这个窗口被触发执行。
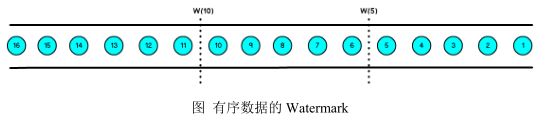
有序流的 Watermarke 如下图所示:(Watermark 设置为 0)
乱序流的 Watermarker 如下图所示:(Watermark 设置为 2)
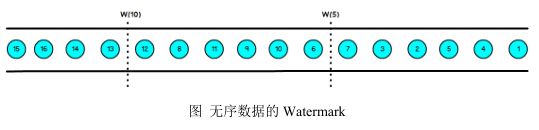
当 Flink 接收到数据时,会按照一定的规则去生成 Watermark,这条 Watermark 就等于当前所有到达数据中的 maxEventTime - 延迟时长,也就是说,Watermark 是由数据携带的,一旦数据携带的 Watermark 比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于 Watermark 是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为 2s,所以时间戳为 7s 的事件对应的 Watermark 是 5s,时间戳为 12s 的事件的 Watermark 是 10s,如果我们的窗口 1是 1s~5s,窗口 2 是 6s~10s,那么时间戳为 7s 的事件到达时的 Watermarker 恰好触发窗口 1,时间戳为 12s 的事件到达时的 Watermark 恰好触发窗口 2。
Watermark 就是触发前一窗口的“关窗时间”,一旦触发关门那么以当前时刻
为准在窗口范围内的所有所有数据都会收入窗中。
只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。
Watermark 的引入
watermark 的引入很简单,对于乱序数据,最常见的引用方式如下:
dataStream.assignTimestampsAndWatermarks( new BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.milliseconds(1000)) {
override def extractTimestamp(element: SensorReading): Long = {
element.timestamp * 1000
}
})
Event Time 的使用一定要 指定数据源中的时间戳。否则程序无法知道事件的事件时间是什么(数据源里的数据没有时间戳的话,就只能使用 Processing Time 了)。
我们看到上面的例子中创建了一个看起来有点复杂的类,这个类实现的其实就是分配时间戳的接口。Flink 暴露了 TimestampAssigner 接口供我们实现,使我们可以自定义如何从事件数据中抽取时间戳。
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给 env 创建的每一个 stream 追加时间特性
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val readings: DataStream[SensorReading] = env
.addSource(new SensorSource)
.assignTimestampsAndWatermarks(new MyAssigner())
MyAssigner 有两种类型:
- AssignerWithPeriodicWatermarks
- AssignerWithPunctuatedWatermarks
以上两个接口都继承自 TimestampAssigner。
Assigner with periodic watermarks
周期性的生成 watermark:系统会周期性的将 watermark 插入到流中(水位线也是一种特殊的事件!)。默认周期是 200 毫秒。可以使用
ExecutionConfig.setAutoWatermarkInterval()方法进行设置。
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 每隔 5 秒产生一个 watermark
env.getConfig.setAutoWatermarkInterval(5000)
产生 watermark 的逻辑:每隔 5 秒钟,Flink 会调用
AssignerWithPeriodicWatermarks 的 getCurrentWatermark()方法。如果方法返回一个时间戳大于之前水位的时间戳,新的 watermark 会被插入到流中。这个检查保证了水位线是单调递增的。如果方法返回的时间戳小于等于之前水位的时间戳,则不会产生新的 watermark。
例如,自定义一个周期性的时间戳抽取:
class PeriodicAssigner extends AssignerWithPeriodicWatermarks[SensorReading] {
val bound: Long = 60 * 1000 // 延时为 1 分钟
var maxTs: Long = Long.MinValue // 观察到的最大时间戳
override def getCurrentWatermark: Watermark = {
new Watermark(maxTs - bound)
}
override def extractTimestamp(r: SensorReading, previousTS: Long) = {
maxTs = maxTs.max(r.timestamp)
r.timestamp
}
}
一种简单的特殊情况是,如果我们事先得知数据流的时间戳是单调递增的,也就是说没有乱序,那我们可以使用 assignAscendingTimestamps,这个方法会直接使用数据的时间戳生成 watermark。
val stream: DataStream[SensorReading] = ...
val withTimestampsAndWatermarks = stream
.assignAscendingTimestamps(e => e.timestamp)
>> result: E(1), W(1), E(2), W(2), ...
而对于乱序数据流,如果我们能大致估算出数据流中的事件的最大延迟时间,就可以使用如下代码:
val stream: DataStream[SensorReading] = ...
val withTimestampsAndWatermarks = stream.assignTimestampsAndWatermarks(
new SensorTimeAssigner
)
class SensorTimeAssigner extends BoundedOutOfOrdernessTimestampExtractor[SensorReading](Time.seconds(5)) {
// 抽取时间戳
override def extractTimestamp(r: SensorReading): Long = r.timestamp
}
>> relust: E(10), W(0), E(8), E(7), E(11), W(1), ...
Assigner with punctuated watermarks
间断式地生成 watermark。和周期性生成的方式不同,这种方式不是固定时间的,而是可以根据需要对每条数据进行筛选和处理。直接上代码来举个例子,我们只给 sensor_1 的传感器的数据流插入 watermark:
class PunctuatedAssigner extends AssignerWithPunctuatedWatermarks[SensorReading] {
val bound: Long = 60 * 1000
override def checkAndGetNextWatermark(r: SensorReading, extractedTS: Long): Watermark = {
if (r.id == "sensor_1") {
new Watermark(extractedTS - bound)
} else {
null
}
}
override def extractTimestamp(r: SensorReading, previousTS: Long): Long = {
r.timestamp
}
}
EventTime 在 window 中的使用
滚动窗口(TumblingEventTimeWindows )
def main(args: Array[String]): Unit = {
// 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val dstream: DataStream[String] = env.socketTextStream("localhost",7777)
val textWithTsDstream: DataStream[(String, Long, Int)] = dstream.map{
text => val arr: Array[String] = text.split(" ")
(arr(0), arr(1).toLong, 1)
}
val textWithEventTimeDstream: DataStream[(String, Long, Int)] =
textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
})
val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDstream.keyBy(0)
textKeyStream.print("textkey:")
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.seconds(2)))
val groupDstream: DataStream[mutable.HashSet[Long]] = windowStream.fold(new mutable.HashSet[Long]()) { case (set, (key, ts, count)) => set += ts}
groupDstream.print("window::::").setParallelism(1)
env.execute()
}
结果是按照 Event Time 的时间窗口计算得出的,而无关系统的时间(包括输入的快慢)。
滑动窗口(SlidingEventTimeWindow)
def main(args: Array[String]): Unit = {
// 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val dstream: DataStream[String] = env.socketTextStream("localhost",7777)
val textWithTsDstream: DataStream[(String, Long, Int)] = dstream.map {
text => val arr: Array[String] = text.split(" ")
(arr(0), arr(1).toLong, 1)
}
val textWithEventTimeDstream: DataStream[(String, Long, Int)] = textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
})
val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDstream.keyBy(0)
textKeyStream.print("textkey:")
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.seconds(2),Time.milliseconds(500)))
val groupDstream: DataStream[mutable.HashSet[Long]] = windowStream.fold(new mutable.HashSet[Long]()) { case (set, (key, ts, count)) => set += ts }
groupDstream.print("window::::").setParallelism(1)
env.execute()
}
会话窗口(EventTimeSessionWindow)
相邻两次数据的 EventTime 的时间差超过指定的时间间隔就会触发执行。如果加入 Watermark, 会在符合窗口触发的情况下进行延迟。到达延迟水位再进行窗口触发。
def main(args: Array[String]): Unit = {
// 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val dstream: DataStream[String] = env.socketTextStream("localhost",7777)
val textWithTsDstream: DataStream[(String, Long, Int)] = dstream.map {
text => val arr: Array[String] = text.split(" ")
(arr(0), arr(1).toLong, 1)
}
val textWithEventTimeDstream: DataStream[(String, Long, Int)] = textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
})
val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDstream.keyBy(0)
textKeyStream.print("textkey:")
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(EventTimeSessionWindows.withGap(Time.milliseconds(500)))
windowStream.reduce((text1,text2)=> ( text1._1,0L,text1._3+text2._3))
.map(_._3)
.print("windows:::")
.setParallelism(1)
env.execute()
}