图的基本概念
图由结点的有穷集合V和边的集合E组成。图中常常将结点成为顶点,边是顶点的有序偶对。若两个顶点之间存在一条边,则表示这两个顶点具有相邻关系。
边有方向的称为有向图,没有方向的称为无向图。
弧:在有向图中,通常将边称为弧,含箭头的一端成为弧头,另一端称为弧尾,记作
有向完全图:若有向图有n个顶点,则最多有n(n-1)条边(图中任意两个顶点都有两条边相连),将具有n(n-1)条边的有向图称为有向完全图。
无向完全图:若无向图中有n个顶点,则最多有n(n-1)/2条边(任意两个顶点之间都有一条边),将具有n(n-1)/2条边的无向图称为无向完全图。
图的存储结构
1.邻接矩阵
邻接矩阵是表示顶点之间相邻关系的矩阵。设G=(V, E)是具有n个顶点的图,顶点序号依次为0,1,...,n-1,则G的邻接矩阵是具有如下定义的n阶方阵A:
A[i][j]=1,表示顶点i与顶点j邻接,即i与j之间存在边或者弧;
A[i][j]=0,表示顶点i与顶点j不邻接。
邻接矩阵是图的顺序存储结构。
对于无向图,邻接矩阵是对称的,矩阵中“1”的个数为图中总边数的两倍,矩阵中第i行或第i列的元素之和即为顶点i的度。
对于有向图,矩阵中1的个数为图的边数,矩阵中第i行的元素之和为顶点i的出度,第j列元素之和即为顶点j的出度。
邻接矩阵的结构型定义如下:
typedef struct {
int no; /* 顶点编号 */
char info; /* 顶点其他信息 */
}VertexType; //顶点类型
typedef struct {
int edges[maxSize][maxSize];
int n, e;
VertexType vex[maxSize];
}MGraph; //图的邻接矩阵类型
2.邻接表
邻接表是图的一种链式存储结构。所谓邻接表就是对图中的每个顶点i建立一个单链表,每个单链表的第一个结点存放有关顶点的信息,把这一结点看作链表的表头,其余结点存放有关边的信息。它的缺点是不方便判断两个顶点之间是否有边,但是相对邻接矩阵来说更省空间。
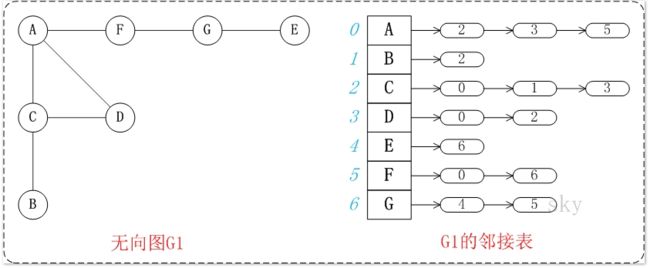
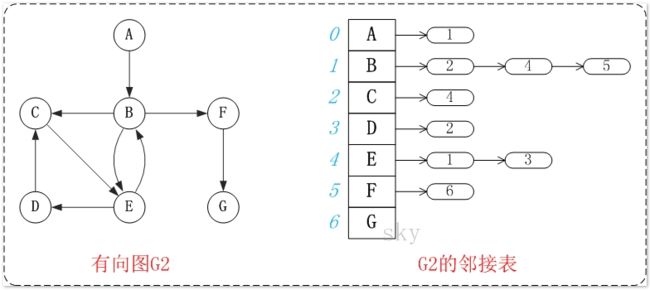
图的遍历算法操作
1.深度优先搜索遍历DFS
Depth First Search
图的DFS类似于二叉树的先序遍历。它的基本思想是:首先访问出发点v,并将其标记为已访问过;然后选取与v邻接的未被访问的任意一个顶点w,并访问它;再选取与w邻接的未被访问的任一顶点并访问,以此重复进行。当一个顶点所有的邻接顶点都被访问过时,则依次退回到最近被访问过的顶点,若该顶点还有其他邻接顶点未被访问,则从这些未被访问的顶点中取一个并重复上述访问过程,直至图中所有顶点都被访问过为止。
算法执行过程:选取一个顶点,访问之,然后检查这个顶点的所有邻接顶点,递归访问其中未被访问过的顶点。
2.广度优先搜索遍历BFS
Breadth First Search
图的广度优先搜索遍历BFS类似于树的层次遍历。它的基本思想是:首先访问起始顶点v,然后选取与v邻接的全部顶点w1,w2...wn进行访问,再依次访问与w1,w2,....wn邻接的全部顶点(已经访问过的除外),以此类推,直到所有顶点都被访问过为止。
广度优先搜索遍历图时,需要用到一个队列(二叉树的层次遍历也要用到队列),算法执行过程可简单概括如下:
- 任务图中一个顶点访问,入队,并将这个顶点标记为已访问。
- 当队列不空时循环执行:出队,依次检查出队顶点的所有邻接顶点,访问没有被访问过的邻接顶点并将其入队。
- 当队列为空时跳出循环,广度优先搜索即完成。
生成树和最小生成树
一个连通图的生成树是该连通图的一个极小连通子图,它含有图中全部顶点,但只有构成一棵树的(n-1)条边。
对于一个带权的连通无向图的不同生成树,各棵树的边上的权值之和可能不同,边上的权值之和最小的树称为最小生成树。
构成最小生成树的主要有:1.普里姆算法prim 2.克鲁斯卡尔算法kruskal
prim算法
对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。 从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为止,最小生成树构造完毕,这时集合T中包含了最小生成树中的所有边。
kruskal算法
克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。
基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
具体做法:首先构造一个只含n个顶点的森林,然后依权值从小到大从连通网中选择边加入到森林中,并使森林中不产生回路,直至森林变成一棵树为止。
最短路径
在无权图中,把路径长度最短(即经过的边数最少)的那条路径叫做最短路径,其路径长度叫做最短路径长度或最短距离。
在带权图中,把带权路径长度最短的那条路径称为最短路径,其路径长度(权值之和)称为最短路径长度或者最短距离。
求图的最短路径长度的问题分为两个方面:1.求图中的一个顶点到其余各顶点的最短路径(dijkstra迪杰斯特拉算法)
2.求图中每对顶点之间的最短路径(floyd算法)
迪杰斯特拉算法
迪杰斯特拉算法是典型的最短路径算法,用于计算一个节点到其他节点的最短路径
它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。
基本思想
通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。
此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是记录还未求出最短路径的顶点(以及该顶点到起点s的距离)。
初始时,S中只有起点s;U中是除s之外的顶点,并且U中顶点的路径是"起点s到该顶点的路径"。然后,从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 然后,再从U中找出路径最短的顶点,并将其加入到S中;接着,更新U中的顶点和顶点对应的路径。 ... 重复该操作,直到遍历完所有顶点。
操作步骤
(1) 初始时,S只包含起点s;U包含除s外的其他顶点,且U中顶点的距离为"起点s到该顶点的距离"[例如,U中顶点v的距离为(s,v)的长度,然后s和v不相邻,则v的距离为∞]。
(2) 从U中选出"距离最短的顶点k",并将顶点k加入到S中;同时,从U中移除顶点k。
(3) 更新U中各个顶点到起点s的距离。之所以更新U中顶点的距离,是由于上一步中确定了k是求出最短路径的顶点,从而可以利用k来更新其它顶点的距离;例如,(s,v)的距离可能大于(s,k)+(k,v)的距离。
(4) 重复步骤(2)和(3),直到遍历完所有顶点。
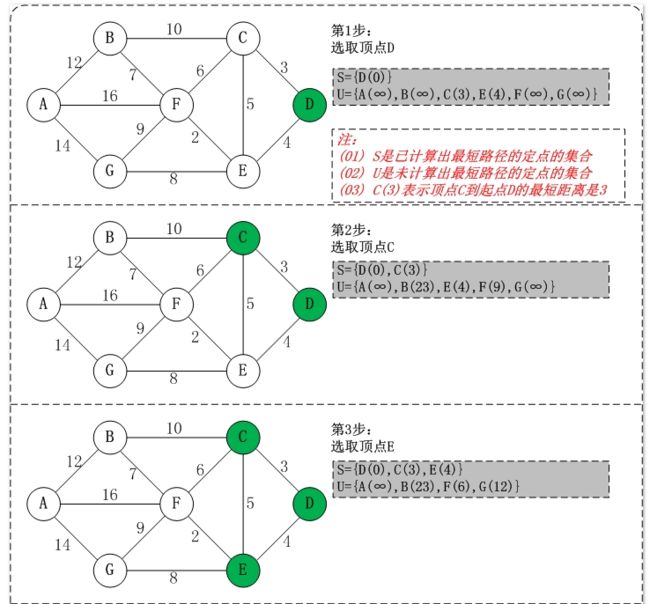
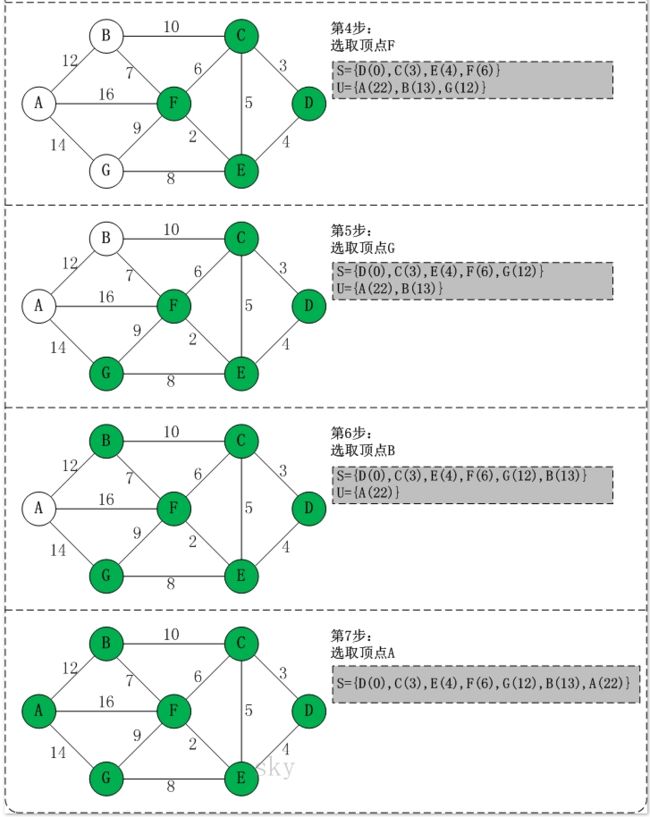 迪杰斯特拉算法示例.png
迪杰斯特拉算法示例.png
弗洛伊德算法
迪杰斯特拉算法是求图中某一顶点到其余各顶点的最短路径,如果求图中任意一对顶点间的最短路径,则通常用弗洛伊德算法。
基本思想
通过Floyd计算图G=(V,E)中各个顶点的最短路径时,需要引入一个矩阵S,矩阵S中的元素a[i][j]表示顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
假设图G中顶点个数为N,则需要对矩阵S进行N次更新。初始时,矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。 接下来开始,对矩阵S进行N次更新。第1次更新时,如果"a[i][j]的距离" > "a[i][0]+a[0][j]"(a[i][0]+a[0][j]表示"i与j之间经过第1个顶点的距离"),则更新a[i][j]为"a[i][0]+a[0][j]"。 同理,第k次更新时,如果"a[i][j]的距离" > "a[i][k]+a[k][j]",则更新a[i][j]为"a[i][k]+a[k][j]"。更新N次之后,操作完成!
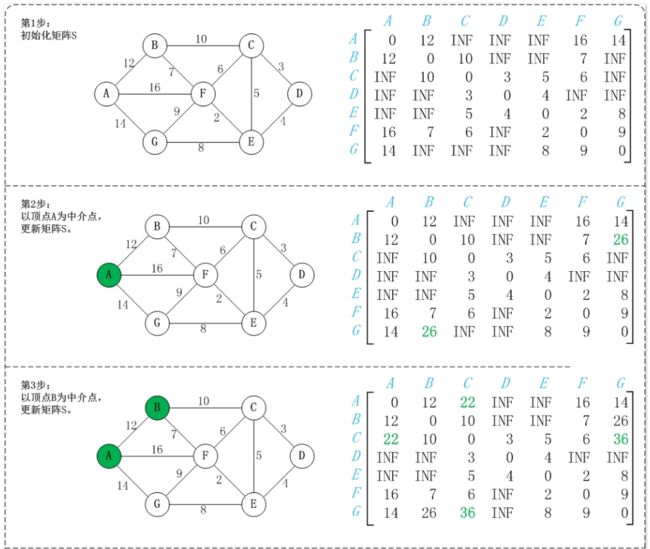
初始状态:S是记录各个顶点间最短路径的矩阵。
第1步:初始化S。
矩阵S中顶点a[i][j]的距离为顶点i到顶点j的权值;如果i和j不相邻,则a[i][j]=∞。实际上,就是将图的原始矩阵复制到S中。
注:a[i][j]表示矩阵S中顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
第2步:以顶点A(第1个顶点)为中介点,若a[i][j] > a[i][0]+a[0][j],则设置a[i][j]=a[i][0]+a[0][j]。
以顶点a[1]6,上一步操作之后,a[1][6]=∞;而将A作为中介点时,(B,A)=12,(A,G)=14,因此B和G之间的距离可以更新为26。
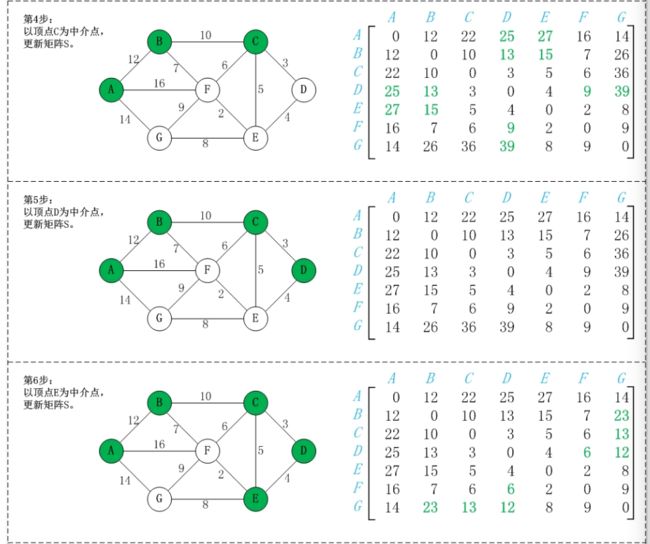
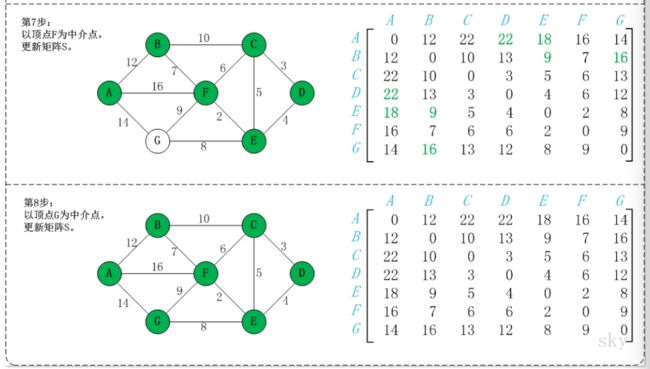
同理,依次将顶点B,C,D,E,F,G作为中介点,并更新a[i][j]的大小。