五种IP模型及IO多路转接详解
五种IP模型及多路转接详解
- 1.五种IO模型
- 2.非阻塞IO(fcntl)
- 3.I/O多路转接之select
- 4.I/0多路转接poll
- 5.I/O多路转接epoll
1.五种IO模型
-
阻塞IO模型:调用IO系统调用的进程会一直
阻塞,直到内核中数据拷贝完成。应用程序调用一个IO函数,导致应用程序阻塞,等待内核数据准备好。 如果数据没有准备好,一直等待到数据准备好了为止,然后将数据从内核拷贝到用户空间并且返回成功指示。
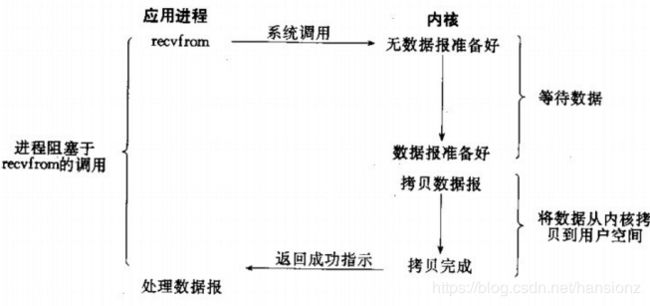
注:阻塞IO是最常见的IO模型 -
非阻塞IO:非阻塞IO通过进程
反复调用IO函数多次系统调用,并马上返回,但是在数据拷贝的过程中,进程是阻塞的。如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码。
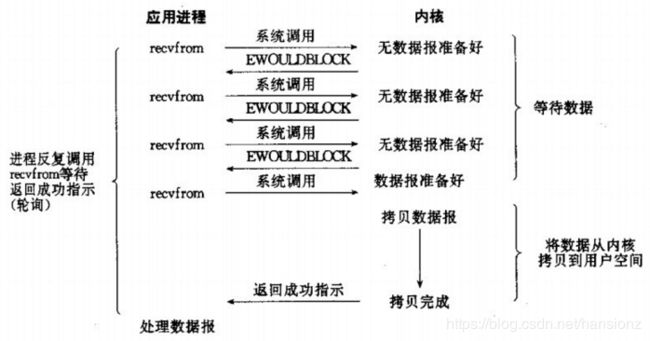
注:非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符,这个过程称为轮询。这对CPU来说是较大的浪费,一 般只有特定场景下才使用。
- 信号驱动IO:首先让套接口进行
信号驱动I/O,并捕捉一个信号处理函数,进程继续运行并不阻塞。当数据准备好时,内核向该进程发送一个SIGIO信号,可以在信号处理函数中调用I/O操作函数处理数据。两次调用,两次返回。

-
IO多路转接:主要是
select和epoll。对一个IO端口,两次调用,两次返回,比阻塞IO并没有什么优越性,关键是能实现同时对多个IO端口进行监听。I/O复用模型会用到select、poll、epoll函数,这几个函数也会使进程阻塞,但是和阻塞I/O所不同的的,这两个函数可以同时阻塞多个I/O操作。而且可以同时对存在多个读操作,多个写操作的I/O函数进行检测,直到有数据可读或可写时,才真正调用I/O操作函数。虽然从流程图上看起来和阻塞IO类似,但是实际上最核心在于IO多路转接能够同时等待多个文件描述符的就绪状态。

-
异步IO:数据拷贝的时候进程
无需阻塞。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的结果,通过状态、通知或者回调函数来通知调用者的输入输出操作。由内核在数据拷贝完成时, 通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据).
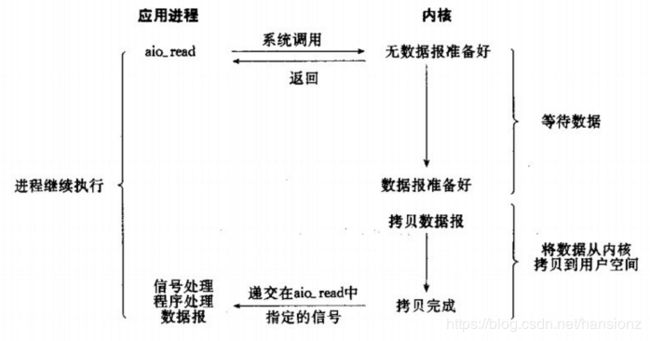
总结:任何IO过程中, 都包含两个步骤,第一是等待, 第二是拷贝,而且在实际的应用场景中, 等待消耗的时间往往都远远高于拷贝的时间,为了让IO更高效, 最核心的办法就是让等待的时间尽量少。
同步通信与异步通信的区别:
- 同步就是在发出一个
调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回结果。换句话说,就是由调用者主动等待这个调用的结果。 - 异步则是相反,调用在发出之后,这个调用就
直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果,而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
同步与互斥区别:
- 互斥是指某一资源同时只允许
一个访问者对其进行访问,具有唯一性和排它性。但互斥无法限制访问者对资源的访问顺序,即访问是无序的。 - 同步是指在
互斥的基础上(大多数情况),通过其它机制实现访问者对资源的有序访问。在大多数情况下,同步已经实现了互斥,特别是所有写入资源的情况必定是互斥的。并发进程在一些关键点上可能需要互相等待与互通消息,这种相互制约的等待与互通信息称为进程同步。 实际上进程互斥也是一种同步,他协调多个进程互斥进入同一个临界资源对应的临界区。同步是为完成某种任务而建立的两个或多个线程,这个线程需要在某些位置上协调他们的工作次序而等待、 传递信息所产生的制约关系,尤其其是在访问临界资源的时候。
阻塞和非阻塞的区别:
- 阻塞调用是指
调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。有人会把阻塞调用和同步调用等同起来,实际上他是不同的。对于同步调用来说,很多时候当前线程还是激活的,只是从逻辑上当前函数没有返回而已。 例如,我们在socket中调用recv函数,如果缓冲区中没有数据,这个函数就会一直等待,直到有数据才返回。而此时,当前线程还会继续处理各种各样的消息。 - 非阻塞调用指在不能立刻得到结果之前,该调用
不会阻塞当前线程,而是继续处理别的事。
总结:
- 同步,就是我调用一个
功能,该功能没有结束前,我死等结果。 - 异步,就是我调用一个功能,不需要知道该功能结果,该功能有结果后通知我
(回调通知),自己去做自己的事。 - 阻塞, 就是调用我(函数),我(函数)没有接收完
数据或者没有得到结果之前,我不会返回。 - 非阻塞,就是调用我(函数),我(函数)立即返回,通过
select通知调用者
2.非阻塞IO(fcntl)
fcntl: 该函数参数存在一个文件描述符,默认为阻塞IO

根据传入的cmd的值不同,后面追加的参数也不相同,它的功能有五种:
- 复制一个现有的描述符(cmd=F_DUPFD)
- 获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD)
- 获得/设置文件状态标记(cmd=F_GETFL或F_SETFL)
- 获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN)
- 获得/设置记录锁(cmd=F_GETLK,F_SETLK或F_SETLKW)
利用第三种功能, 获取/设置文件状态标记, 就可以将一个文件描述符设置为非阻塞。
基于fcntl实现轮询方式读取标准输入:
#include - 使用
F_GETFL将当前的文件描述符的属性取出来。 - 然后再使用
F_SETFL将文件描述符设置回去,设置回去的同时加上一个O_NONBLOCK参数,表示非阻塞。
3.I/O多路转接之select
操作系统提供select函数来实现多路复用输入/输出模型。select系统调用是用来让我们的程序监视多个文件描述符的状态变化的,程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变。
select函数:

参数解释:
nfds是需要监视的最大的文件描述符值+1。readfds\writefds\exceptfds分别对应于需要检测的可读文件描述符的集合,可写文件描述符的集合及异常文件描述符的集合 。- 参数timeout为结构
timeval,用来设置select的等待时间。
参数timeout:
- NULL表示
select没有timeout,select将一直被阻塞,直到某个文件描述符上发生了事件。 - 0表示仅检测
描述符集合的状态,然后立即返回并不等待外部事件的发生。 - 特定的时间值表示如果在指定的
时间段里没有事件发生,select将超时返回。
fd_set结构: 这个结构实质上就是一个整数数组,更严格的说是一个"位图"。 使用位图中对应的位来表示要监视的文件描述符。操作系统提供了一组很方便的接口来操作这个位图:
void FD_CLR(int fd, fd_set *set); // 用来清除描述词组set中相关fd 的位
int FD_ISSET(int fd, fd_set *set);// 用来测试描述词组set中相关fd 的位是否为真
void FD_SET(int fd, fd_set *set); // 用来设置描述词组set中相关fd的位
void FD_ZERO(fd_set *set); // 用来清除描述词组set的全部
timeval结构体:
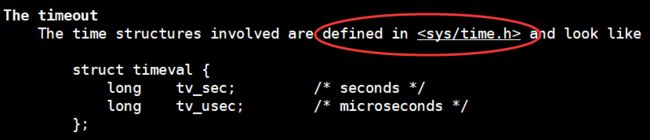
timeval结构用于描述一段时间长度,如果在这个时间内需要监视的描述符没有事件发生则函数返回,返回值为0。
select函数返回值:
- 执行成功则返回
文件描述符状态已改变的个数 - 如果返回0代表在
描述词状态改变前已超过timeout时间没有返回 - 当有错误发生时则返回
-1,错误原因存于errno,此时参数readfds,writefds, exceptfds和timeout的值变成不可预测
错误值可能为:
- EBADF 文件描述词为无效的或该
文件已关闭 - EINTR 此调用被
信号所中断 - EINVAL 参数
n为负值 - ENOMEM 核心
内存不足
select常见使用方法:
fs_set readset;
FD_SET(fd,&readset);
select(fd+1,&readset,NULL,NULL,NULL);
if(FD_ISSET(fd,readset)){//业务}
理解select执行过程:
取fd_set长度为1字节,fd_set中的每个bit可以对应一个文件描述符fd。则1字节长的fd_set最大可以对应8个fd。
- 执行
fd_set set; FD_ZERO(&set);则set用位表示是00000000。 - 若
fd=5,执行FD_SET(fd,&set);后set变为00010000(第5位置为1) - 若再加入
fd=2,fd=1,则set变为00010011 - 执行
select(6,&set,0,0,0)阻塞等待 - 若
fd=1,fd=2上都发生可读事件,则select返回,此时set变为 00000011。没有事件发生的fd=5被清空。
socket就绪条件: socket也是一种文件描述符。
读就绪:
socket在内核中接收缓冲区中的字节数大于等于低水位标记SO_RCVLOWAT。 此时可以无阻塞的读该文件描述符并且返回值大于0socketTCP通信中,对端关闭连接,此时对该socket读则返回0- 监听的
socket上有新的连接请求 socket上有未处理的错误
写就绪:
- socket内核中发送缓冲区中的可用字节数(发送缓冲区的空闲位置大小)大于等于低水位标记
SO_SNDLOWAT,此时可以无阻塞的写,并且返回值大于0 - socket的写操作被关闭
(close或者shutdown),对一个写操作被关闭的socket进行写操作会触发SIGPIPE信号 - socket使用非阻塞
connect连接成功或失败之后 - socket上有
未读取的错误
select的特点:
- 可监控的
文件描述符个数取决与sizeof(fd_set)的值。服务器上sizeof(fd_set)=512,每bit表示一个文件描述符,则服务器上支持的最大文件描述符是512*8=4096。 - 将
fd加入select监控集的同时,还要再使用一个数据结构array保存放到select监控集中的fd。 一是用于在select返回后,array作为源数据和fd_set进行FD_ISSET判断;二是select返回后会把以前加入的但并无事件发生的fd清空,则每次开始select前都要重新从array取得fd逐一加入(FD_ZERO最先),扫描array的同时取得fd最大值maxfd,用于select的第一个参数。
select的缺点:
- 每次调用
select,都需要手动设置fd集合。 - 每次调用select,都需要把
fd集合从用户态拷贝到内核态,这个开销在很多时会很大。 - 每次调用select都需要在
内核遍历传递进来的所有fd,这个开销在很多时也很大。 - select支持的
文件描述符数量太小。
#include 4.I/0多路转接poll
poll函数:
#include events和revents的取值:
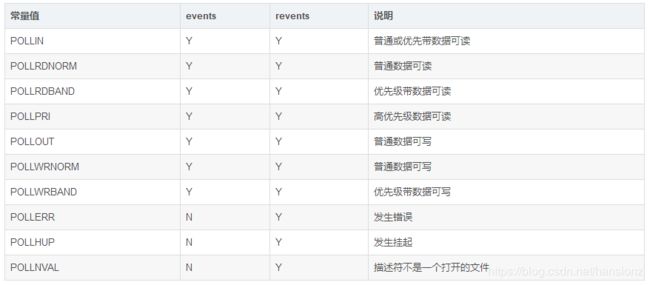
参数说明:
fds是一个poll函数监听的结构列表,每一个元素中包含了三部分内容:文件描述符,监听的事件集合,返回的事件集合。nfds表示fds数组的长度。timeout表示poll函数的超时时间,单位是毫秒(ms)。
返回值说明:
- 返回值小于0,表示出错
- 返回值等于0,表示poll函数等待超时
- 返回值大于0,表示poll由于监听的文件描述符就绪而返回
poll的优点:
-
不同与select使用三个位图来表示三个fdset的方式,poll使用一个pollfd的指针实现。
-
pollfd结构包含了要
监视的event和发生的event,不再使用select“参数-值”传递的方式,接口使用比select更方便。 -
poll并没有
最大数量限制。
poll的缺点:
- 和
select函数一样,poll返回后需要轮询pollfd来获取就绪的描述符。 - 每次调用
poll都需要把大量的pollfd结构从用户态拷贝到内核中。 - 同时连接的大量客户端在一时刻可能只有很少的处于
就绪状态, 因此随着监视的描述符数量的增长,其效率也会线性下降。
实现一个监测标准输入:
#include 5.I/O多路转接epoll
当套接字比较多的时候,每次select()都要通过遍历FD_SETSIZE个Socket来完成调度,不管哪个Socket是活跃的,都遍历一遍。这会浪费很多CPU时间。如果能给套接字注册某个回调函数,当他们活跃时,自动完成相关操作,那就避免了轮询,这正是epoll做的。
epoll支持水平触发和边缘触发,最大的特点在于边缘触发,它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。还有一个特点是,epoll使用“事件”的就绪通知方式,通过epoll_ctl注册fd,一旦该fd就绪,内核就会采用类似callback的回调机制来激活该fd,epoll_wait便可以收到通知。
epoll相关系统调用:
epoll_create: 创建一个epoll的句柄,size表示监听数目的大小。创建完句柄它会自动占用一个fd值,使用完epoll一定要记得close,不然fd会被消耗完。
int epoll_create(int size);
//size参数被忽略
epoll_ctl: 这是epoll的事件注册函数,和select不同的是select在监听的时候会告诉内核监听什么样的事件,而epoll必须在epoll_ctl先注册要监听的事件类型。
它的第一个参数是epoll_creat的执行结果。
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
参数说明:
- 它不同于
select()是在监听事件时告诉内核要监听什么类型的事件, 而是在这里先注册要监听的事件类型。 - 第一个参数是
epoll_create()的返回值(epoll的句柄)。 - 第二个参数表示
动作,用三个宏来表示。 - 第三个参数是需要监听的
fd。 - 第四个参数是告诉
内核需要监听什么类型事件。
第二个参数表示的三个宏:
- EPOLL_CTL_ADD :注册新的
fd到epfd中 - EPOLL_CTL_MOD :修改已经注册的
fd的监听事件 - EPOLL_CTL_DEL :从
epfd中删除一个fd
struct epoll_event结构体:
typedef union epoll_data {
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
events可以是以下几个宏的集合:
- EPOLLIN : 表示对应的文件描述符可以读 (包括对端
SOCKET正常关闭) - EPOLLOUT : 表示对应的文件描述符可以写
- EPOLLPRI : 表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来)
- EPOLLERR : 表示对应的文件描述符发生错误
- EPOLLHUP : 表示对应的文件描述符被挂断
- EPOLLET : 将EPOLL设为边缘触发
(Edge Triggered)模式, 这是相对于水平触发(Level Triggered)来说的 - EPOLLONESHOT:只监听一次事件, 当监听完这次事件之后, 如果还需要继续监听这个
socket的话, 需要再次把这个socket加入到EPOLL队列里
epoll_wait函数: 收集在epoll监控的事件中已经发送的事件。等待事件的发生,类似于select的调用。
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
参数说明:
- 参数
events是分配好的epoll_event结构体数组。epoll将会把发生的事件赋值到events数组中 (events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存)。 maxevents告诉内核这个events有多大,这个maxevents的值不能大于创建epoll_create()时的size。- 参数
timeout是超时时间 (毫秒,0会立即返回,-1是永久阻塞)
返回值:
- 如果函数调用成功,返回对应
I/O上已准备好的文件描述符数目 - 如返回
0表示已超时 - 返回小于
0表示函数失败
epoll的优点(和 select 的缺点对应):
- 接口使用方便: 虽然
epoll拆分成了三个函数,但是反而使用起来更方便高效。不需要每次循环都设置关注的文件描述符,也做到了输入输出参数分离开。 - 数据拷贝轻量: 只在合适的时候调用
EPOLL_CTL_ADD将文件描述符结构拷贝到内核中,这个操作并不频繁(而select/poll都是每次循环都要进行拷贝) - 事件回调机制: 避免使用
遍历,而是使用回调函数的方式,将就绪的文件描述符结构加入到就绪队列中,epoll_wait返回直接访问就绪队列就知道哪些文件描述符就绪。这个操作时间复杂度O(1),即使文件描述符数目很多,效率也不会受到影响。 - 没有数量限制: 文件描述符数目无上限。
epoll工作方式: epoll有2种工作方式水平触发(LT)和边缘触发(ET)。
水平触发Level Triggered 工作模式 :
- 当
epoll检测到socket上事件就绪的时候,可以不立刻进行处理或者只处理一部分 - 假设我们已经把一个tcp socket添加到epoll描述符.这个时候socket的另一端被写入了2KB的数据 调用epoll_wait,并且它会返回. 说明它已经准备好读取操作 然后调用read, 只读取了1KB的数据 继续调用epoll_wait。由于只读了
1K数据, 缓冲区中还剩1K数据, 在第二次调用epoll_wait时,epoll_wait仍然会立刻返回并通知socket读事件就绪。 - 直到缓冲区上所有的数据都被处理完,
epoll_wait才不会立刻返回。 - 支持
阻塞读写和非阻塞读写。
注:epoll默认状态下就是LT工作模式
边缘触发Edge Triggered工作模式 : 如果我们在第1步将socket添加到epoll描述符的时候使用了EPOLLET标志epoll进入ET工作模式。
- 当
epoll检测到socket上事件就绪时, 必须立刻处理。如上面的例子,虽然只读了1K的数据,但是缓冲区还剩1K的数据,在第二次调用epoll_wait的时候,epoll_wait不会再返回了。 - ET模式下,文件描述符上的事件就绪后只有一次处理机会。ET的性能比LT性能更高(epoll_wait 返回的次数少了很多)。Nginx默认采用
ET模式使用epoll。但是LT只支持非阻塞的读写。
理解ET模式和非阻塞文件描述符: 使用ET 模式的epoll需要将文件描述设置为非阻塞。
假设服务器接受到一个10k的请求, 会向客户端返回一个应答数据,如果客户端收不到应答, 不会发送第二个10k请求。如果服务端写的代码是阻塞式的read, 并且一次只 read 1k数据的话,剩下9k的数据在缓冲区中,此时由于epoll 是ET模式并不会认为文件描述符读就绪。epoll_wait 就不会再次返回,剩下的 9k数据会一直在缓冲区中,直到下一次客户端再给服务器写数据,epoll_wait 才能返回,**但是服务器只读到1k个数据, 要10k读完才会给客户端返回响应数据 ,客户端要读到服务器的响应, 才会发送下一个请求 ,客户端发送了下一个请求, epoll_wait 才会返回, 才能去读缓冲区中剩余的数据。**所以使用非阻塞轮询的方式来读缓冲区, 保证一定能把完整的请求都读出来。
epoll的适用场景: 对于多连接, 且多连接中只有一部分连接比较活跃时, 比较适合使用epoll。例如, 典型的一个需要处理上万个客户端的服务器, 例如各种互联网APP的入口服务器, 这样的服务器就很适合epoll. 如果只是系统内部, 服务器和服务器之间进行通信, 只有少数的几个连接, 这种情况下用epoll就并不合适. 具体要根 据需求和场景特点来决定使用哪种IO模型。
注:epoll惊群问题: http://blog.csdn.net/fsmiy/article/details/36873357
select、poll、epoll三者优缺点对比:
https://blog.csdn.net/qq1910084514/article/details/86593686
https://www.jianshu.com/p/6a6845464770
https://blog.csdn.net/jay900323/article/details/18141217