
(一) 客观世界被描述的范畴
在现实的生活中,描述一件事物,是非常简单的,但是如何将客观世界中,我们所理解,所认知的数据放到数据库中就需要人们对其进行整理、规范和加工,也就是根据其特征进行数据的抽象,然后才能存放到数据库中
然而这个抽象的过程也不是一蹴而就的,对事物的抽象,存在多个不同的层次,同时也需要采用不同的模型进行描述
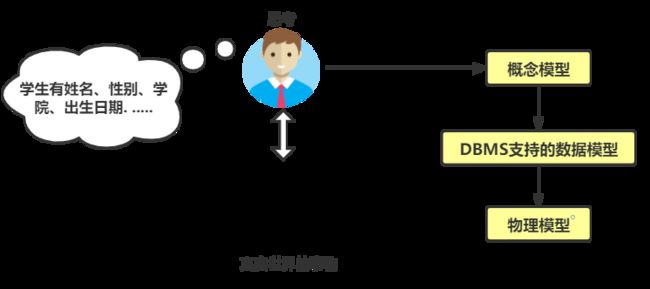
说明:图片右侧的三种模型会在后面具体介绍
可能看完上面不同层次的抽象,对于数据在实际世界与计算机中的联系过程,还是很懵,下面通过三个范畴的简单介绍,大家大致就可以有一个直观的概念了
数据从现实生活进入到数据库实际上经历了若干个阶段。一般划分三个阶段,即现实世界、信息世界和机器世界,称为数据的三种范畴。
① 现实世界:存在于人们头脑之外的客观世界,称为现实世界(别想复杂,这就是咱们生活的这个世界)
② 信息世界:也叫观念世界,是现实世界在人们头脑中的反映
- 也就是,你看到实际生活中一个东西或事物,你脑子里会咋想他,例如学生信息管理,你就会想,学生相关的,例如年龄,学号,出生日期,学院/系 等等
③ 机器世界:信息世界的信息在机器世界中以数据形式存储
- 机器毕竟只能存储数据化的一些信息,必须有一定的规范,且进行加工、编码等等步骤后才能行
(二) 数据模型
(1) 定义
在数据库系统中针对不同的使用对象和应用目的,采用不同的数据模型。根据模型的应用的不同目的,可以将这些模型划分为两类,它们分属于不同的层次(可以对应看前面第一大点的配图)
(2) 分类
A:概念数据模型
-
它也称信息模型
-
它是按用户的观点(观念世界)来对数据和信息建模,主要用于数据库设计
B:DBMS支持的基本数据模型
-
它是按计算机系统的观点进行(机器世界)数据建模,主要用于DBMS的实现
-
主要包括层次模型、网状模型、关系模型等等
(3) 数据模型的三要素
A:数据结构
-
数据结构描述数据库的组成对象以及对象之间的联系
-
数据结构用于描述系统的静态特性
-
通常按照数据结构的类型来命名数据模型
- 层次结构——层次模型
- 网状结构——网状模型
- 关系结构——关系模型
B:数据操作
-
数据操作是指对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则
-
数据库主要有检索和修改(包括插入、删除、更新)两大类操作
-
数据模型必须定义这些操作的确切含义、操作符号、操作规则(如优先级)以及实现操作的语言
-
数据操作用于描述系统的动态特征
说白了,就是你想咋 “动” 这些数据
C:数据完整性约束
-
数据完整性约束是一组完整性规则的集合
-
完整性规则是给定的数据模型中数据及其联系所具有的制约和储存规则,用以限制符合数据模型的数据库状态以及状态的变化,用以确保数据的正确、有效和相容
下面我们会分别,就概念数据模型和基本数据类型两者进行较为详细的介绍
(三) 概念模型
(1) 定义
概念模型是从现实世界中抽取出对于一个目标应用系统来说最有用的事物、事物特征以及事物之间的联系,通过各种概念精确地加以描述
简单的说就是:概念模型,就是按照用户的观点来对信息进行建模
(2) 必知概念
A:实体(Entity)
客观存在并可相互区别的客观事物或抽象事件称为实体
- 就好比你脑海中对一个东西或事物的反映
- 实体可以指人,如一名学生、一名工人等;也可以指东西,如一台电脑、一个桌子、一个杯子等
- 实体不仅可以指实际的事物,还可以指抽象的事物,如一次拜访、一次野餐、购物、演出、篮球赛等
- 甚至还可以指事物与事物之间的联系,如“学生选课记录”和“用户订餐记录”等
B:属性(Attribute)
属性是指实体所具有的某一方面的特性
- 一个实体可有多个属性,例如,学生的属性有姓名、年龄、性别、学院等。
属性值:属性所取的具体值称作属性值
- 例如,一名学生,其中一个属性 “姓名” 的取值 为 “张三”
C:域(Domain)
一个属性可能取的所有属性值的范围称为该属性的域
- 例如,教师属性“性别”的域为男、女;教师属性“职称”的域为助教、讲师、副教授、教授等
由此可见,每个属性都是个变量,属性值就是变量所取的值,而域则是变量的变化范围
因此,属性是表征实体的最基本的信息
D:码(Key)
惟一标识实体的属性集称为码
- 唯一!唯一!唯一!
- 例如学号是学生实体的码,一个学号就能确定这个学生到底哪个
E:实体型(Entity Type)
具有相同属性的实体必然具有共同的特性和性质,用实体名及其属性名集合来抽象和刻画同类实体,称为实体型
- 例如,学生(姓名,年龄,性别,学院)就是一个实体型
F:实体集(Entity Set)
同一类型实体的集合。例如,某一学校中的学生具有相同的属性,他们就构成了实体集 “学生”
(2) 实体间联系
现实世界中事物彼此的联系在概念模型中反映为实体间的联系
- 实体内部的联系通常是指组成实体的各属性之间的联系
- 实体之间的联系通常是指不同实体集之间的联系
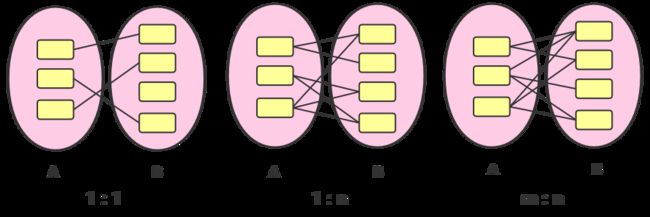
如上图,常见的联系有这么几种
定义就不给了,很繁琐枯燥,举几个例子很容易理解:
A:一对一
学校里,实体集班级与实体集班长之间的就具有1:1联系
- 一个班级只有一个班长,而一个班长只在一个班中任班长职务
B:一对多
例如,实体集班级与实体集学生就是一对多联系
- 因为一个班级中有若干名学生,而每个学生只在一个班级中学习。
C:多对多
实体集课程与实体集学生之间的联系是多对多联系(m:n)
- 因为一个课程同时有若干名学生选修,而一个学生可以同时选修多门课程。
实体型之间的这种一对一、一对多、多对多联系不仅存在于两个实体型之间,也存在于两个以上的实体型之间。
- 例如,对于课程、教师与参考书三个实体型,如果一门课程可以有若干个教师讲授,使用若干本参考书,而每一个教师只讲授一门课程,每一本参考书只供一门课程使用,则课程与教师、参考书之间的联系是一对多的
(三) 基本数据模型
目前常用的数据模型有三种:
-
① 层次模型
-
② 网状模型
-
③ 关系模型
其中层次模型和网状模型统称为非关系模型
层次模型(Hierarchical Model)
网状模型(Network Model)
关系模型(Relational Model)
半结构化数据模型(Semistructured-data Model)
面向对象模型(Object Oriented Model)
对象关系模型(Object Relational Model)
(1) 层次模型
A:基本概念
用树型结构来表示实体之间联系的模型称为层次模型
构成层次模型的树是由结点和连线组成的,结点表示实体集(文件或记录型),连线表示相连两个实体之间的联系
这种联系只能是一对一,一对多的!!!
通常把表示“一”的实体放在上方,称为父结点,而把表示“多”的实体放在下方,称为子结点
根据树结构的特点,建立数据的层次模型需要满足下列两个条件:
-
有且仅有一个结点没有父结点,这个结点即为树根结点
-
其他数据记录有且仅有一个父结点
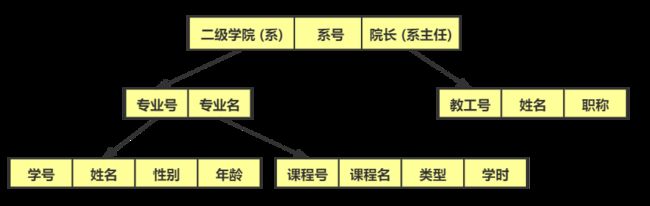
就如上图就是一个层次模型的例子
B:特点
层次模型的一个基本的特点是,任何一个给定的记录值只有按其路径查看时,才能现出它的全部意义,无一个子女记录值能够脱离双亲记录值而独立存在
层次模型最明显的特点是层次清楚、构造简单以及易于实现,它可以很方便地表示出一对一和一对多这两种实体之间的联系。
C:优点
- 层次模型的数据结构比较简单;
- 层次数据库的查询效率高;
- 因记录间的联系用有向边表示,在DBMS中用指针来实现,路径明确,快速
D:缺点
- 对于非层次性的,如多对多联系、一个结点具有多个双亲等,层次模型表示这类联系就很难受,只能通过引入冗余数据(易产生不一致性)或创建非自然组织(引入虚结点)来解决
- 对插入和删除操作的限制比较多
- 查询子结点必须通过双亲结点
- 由于结构严密,层次命令趋于程序化
(2) 网状模型
A:基本概念
网状模型和层次模型在本质上是一样的,简单对比分析一下:
-
从逻辑上看它们都是用连线表示实体之间的联系,用结点表示实体集
-
从物理上看,层次模型和网络模型都是用指针来实现两个文件之间的联系
-
其差别仅在于网状模型中的连线或指针更加复杂,更加纵横交错,从而使数据结构更复杂
网状模型去掉了层次模型的两个限制(下面的 ① ② 点),所以它是一种比层次模型更具普遍性的结构,
在数据库中,把满足以下条件的基本层次联系集合称为网状模型:
- ① 允许一个以上的结点没有双亲结点
- ②一个节点可以有多于一个双亲节点
- ③ 允许两个节点之间有多种联系
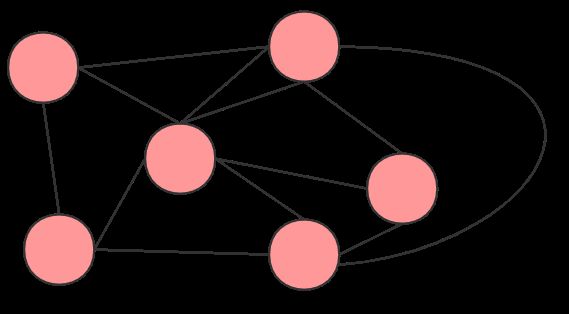
网状模型可以直接表示实体之间多对多的联系
B:优点
- 能够更为直接地描述现实世界,如一个结点可以有多个双亲
- 具有良好的性能,存取效率较高
C:缺点
- 结构比较复杂,而且随着应用环境的扩大,数据库的结构就变得越来越复杂,不利于用户最终掌握
- 其DDL,DML语言复杂,用户不容易使用
(3) 关系模型
A:基本概念
关系模型是现在非常流行的一种数据模型
关系模型是用表格数据来表示实体本身及其相互之间的联系的
-
在用户观点下,关系模型中数据的逻辑结构是一张二维表,它由行和列组成
-
关系既可以表示实体也可以用来描述实体间的联系
在关系模型中,把数据看成一个二维表,每一个二维表称为一个关系
关系表中的每一列称为属性,相当于记录中的一个数据项,对属性的命名称为属性名
表中的一行称为一个元组,相当于记录值。
对于表示关系的二维表,其最基本的要求是,表中元组的每一个分量必须是不可分的数据项,即不允许表中再有表,如下图

B:优点
- 关系模型的概念单一,数据结构比较简单,实体与实体间的联系均用关系来表示,因此,数据的结构比较简单、清晰
- 具有很高的数据独立性。在关系模型中,用户完全不涉及数据的物理存放,只与数据本身的特性发生关系。因此,数据独立性很高
- 可以直接处理多对多的联系。在关系模型中,由于使用表格数据来表示实体之间的联系,因此,可以直接描述多对多的实体联系(如下表直接表示了学生与课程之间的多对多的关系)
- 建立在严格的数学概念基础上,也有着坚实的理论基础
C:缺点
-
最主要的缺点是,查询效率往往不如非关系数据模型。
-
为提高效率,关系数据库管理系统必须对用户的查询请求进行优化,这样增加了开发DBMS的难度。
(4) 半结构化模型
A:基本概念
半结构数据是“无模式”的,数据是自描述(self describing)的
数据携带了关于其模式的信息,模式可以随着时间在单一数据库内任意改变,易于修改和变化
它是一种适于数据库集成(integration)的数据模型,适于描述包含在两个或多个数据库(这些数据库含有不同模式的相似数据)中的数据。
它也是一种标记服务的基础模型,适于在Web上共享信息
B:特点
半结构化数据类似树或图
-
叶子结点(leaf)与具体数据相关,数据的类型可以是任意原子类型,如数字和字符串。
-
内部结点(interior)至少都有一条向外的弧。每条弧都有一个标签(label),该标签指明弧开始处的结点与弧末的结点之间的关系
-
要有一个根(root)结点,它代表整个数据库,每个结点都从根可达。
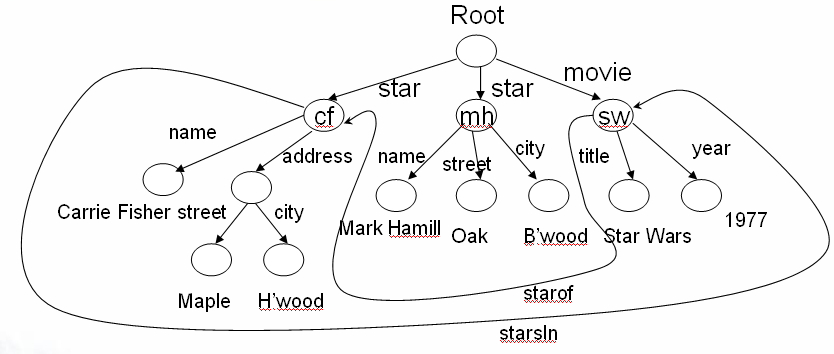
XML 适合存储半结构化数据,关于XML 在我之前的文章中可以看到一篇具体的介绍,这里就不做过多的介绍
面向对象数据模型(object-oriented data model,简称OO data model)
吸收了概念数据模型和知识表示模型的一些基本概念,同时又借鉴了面向对象程序设计语言和抽象数据类型的一些思想,是一种可扩充的数据模型。
面向对象数据模型的基本概念是对象和类。
(5) 面向对象数据模型
A:基本概念
面向对象数据模型,吸收了概念数据模型和知识表示模型的一些基本概念,同时又借鉴了面向对象程序设计语言和抽象数据类型的一些思想,是一种可扩充的数据模型。
面向对象数据模型的基本概念是对象和类。
现实世界的任意实体都是对象
一个对象可以包含多个属性,用来描述对象的状态、组成和特性
对象还包括若干方法,用以描述对象的行为特性,通过方法可以改变对象的状态,对对象进行各种数据库操作
对象是封装的,对象之间的通信是通过消息传递来实现的,即消息从外部传递给对象,存取和调用对象中的属性和方法,在内部执行要求的操作,操作的结果仍以消息的形式返回
B:类(Class)和实例(instance)
共享同一属性集合和方法集合的所有对象组合在一起构成了一个对象类(简称为类),一个对象是某一类的一个实例。
例如,学生是一个类,具体的某个学生,例如张山是学生类中的一个对象
在数据库系统中有“型”和“值”的概念,而在面向对象数据模型中,“型”就是类,对象是某个类的“值”
类属性的定义域可以为基本类,如字符串、整数、布尔型,也可以为一般类,即包括属性和方法的类一个类的属性也可以定义为这个类自身
C:类层次(Class hierarchy)
面向对象数据模型中,类的子集称为该类的子类,该类称为子类的超类。子类还可以有子类,也就是类可以有嵌套结构
系统中所有的类组成了一个有根的有向无环图,称为类层次
一个类可以从类层次的直接或间接祖先那里继承所有的属性和方法,用这个方法实现了软件的可重用性
(四) 结尾
如果文章中有什么不足,欢迎大家留言交流,感谢朋友们的支持!
如果能帮到你的话,那就来关注我吧!如果您更喜欢微信文章的阅读方式,可以关注我的公众号
在这里的我们素不相识,却都在为了自己的梦而努力 ❤
一个坚持推送原创开发技术文章的公众号:理想二旬不止
