Python3 pyspider(一)互动百科词条爬取保存到Postgresql(初学)
pyspider互动百科词条爬取
首页:
http://www.baike.com/
百科类网站在反爬方面一般不会很难,但是在数据完整度上面要求更加高,难度几乎都是在怎么才能拿到大量的完整数据,互动百科有1700万词条,想要拿到大部分数据,在爬取规则上面就要多想一点。
先看一下要爬取的一般词条网页信息:

开始也走了一些弯路,因为爬取规则的问题,爬到的数据量太少,当然最后也找到了一条路。
先是找到了这么一个页面,当然依赖这个爬出来的数据也不全面。但这也给了我思路,依赖分类去爬取数据。
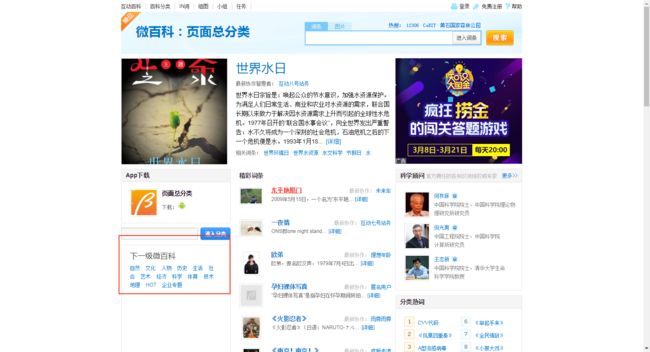
首先就是这个总分类界面能看到上面的大分类,我就依赖这个先进行广度+深度的分类内容的爬取。看到上图的其他内容,有类似“精彩词条,分类热词”的就是我需要的东西,当然这也不全面啊。
接着往下拉页面,又能看到这个“全部词条”,这个全部词条里面就是与这个分类有关的一些词条。现在数据就相对完整了。再往下拉界面,应该可以看到下图,“全部词条”里面的内容和这个分页所包含的差不多,所以就用“全部词条“里面的了。其实这分页也是反爬手段,最多给100页(我试过下下图的拼url,也只能拿到下图能看到的页数)
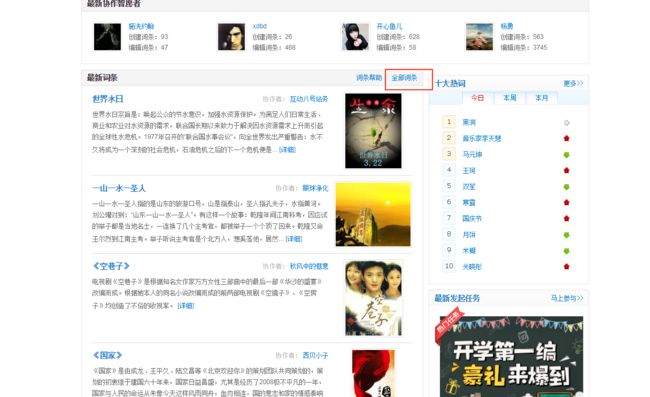

当然有一点肯定有人有疑问:怎么确定依赖分类就能爬全。仔细看一下第二张图,词条标题下有一个开放分类,而且是每一个词条都有这个分类,所以只要拿到这个词条所属分类就能拿到这个词条。
因为是初学者,所以代码写的比较差劲,但也给大家看看吧。。。
from pyspider.libs.base_handler import *
import json
import re
from abc import abstractclassmethod
import psycopg2
class Handler(BaseHandler):
crawl_config = {
}
#从页面总分类开始的
@every(minutes=1 * 30)
def on_start(self):
self.conn = psycopg2.connect(dbname="postgres", user="postgres",password="root", host="127.0.0.1", port="5432")
self.conn.autocommit = True
print("已打开数据库链接")
self.crawl('http://fenlei.baike.com/%E9%A1%B5%E9%9D%A2%E6%80%BB%E5%88%86%E7%B1%BB/', callback=self.index_page, last_modified=False, etag=False)
def on_finished(self):
if hasattr(self, 'conn'):
self.conn.close()
print("数据库链接已关闭!")
@config(age=1 * 1 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://fenlei\.baike\.com/(%\w+)+/\?prd=fenleishequ_zifenlei",each.attr.href):
self.crawl(each.attr.href, callback=self.next_page)
elif re.match("http://fenlei\.baike\.com/(%\w+)+",each.attr.href):
self.crawl(each.attr.href, callback=self.next_page)
elif re.match("http://www\.baike\.com/wiki/",each.attr.href):
sceneStr = each.attr.href
url = sceneStr.replace(' ','+')
self.crawl(url, callback=self.detail_page)
elif re.match("http://www\.baike\.com/wiki/[\u4e00-\u9fa5]+(%\w+)+",each.attr.href):
sceneStr = each.attr.href
url = sceneStr.replace(' ','+')
self.crawl(url, callback=self.detail_page)
@config(age=1 * 1 * 60 * 60)
def next_page(self, response):
for each in response.doc('a[href^="http"]').items():
if re.match("http://fenlei\.baike\.com/(%\w+)+/\?prd=fenleishequ_zifenlei",each.attr.href):
self.crawl(each.attr.href, callback=self.next_page)
elif re.match("http://fenlei\.baike\.com/(%\w+)+",each.attr.href):
self.crawl(each.attr.href, callback=self.next_page)
elif re.match("http://fenlei\.baike\.com/[\u4e00-\u9fa5]+/list/",each.attr.href):
print(each.attr.href)
self.crawl(each.attr.href, callback=self.next_page)
elif re.match("http://fenlei\.baike\.com/(%\w+)+/list/",each.attr.href):
print(each.attr.href)
self.crawl(each.attr.href, callback=self.next_page)
elif re.match("http://www\.baike\.com/wiki/",each.attr.href):
sceneStr = each.attr.href
url = sceneStr.replace(' ','+')
self.crawl(url, callback=self.detail_page)
elif re.match("http://www\.baike\.com/wiki/[\u4e00-\u9fa5]+(%\w+)+",each.attr.href):
sceneStr = each.attr.href
url = sceneStr.replace(' ','+')
self.crawl(url, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
task_id = self.task['taskid']
crawl_url = response.url
crawl_name = response.doc('#primary > div.w-990 > div.l.w-640 > div.content-h1 > h1').text()
crawl_task_info = json.dumps(self.task)
crawl_dom = response.text.replace("'", "\"")
if not hasattr(self, 'conn'):
self.conn = psycopg2.connect(dbname="postgres", user="postgres",password="root", host="127.0.0.1", port="5432")
self.conn.autocommit = True
print("已重新获取数据库链接")
cursor = self.conn.cursor()
sql = "INSERT INTO baike(task_id,crawl_url,crawl_name,crawl_task_info,crawl_time,crawl_dom) VALUES('" + task_id + "','" + crawl_url + "','" +crawl_name+"','"+ crawl_task_info + "',now(),'" + crawl_dom + "');"
print(sql)
cursor.execute(sql)
cursor.close()
print("数据保存成功")在不同的界面爬取的数据(有的是在分类界面有的在分类/list界面),所以同一个词条的url并不唯一,因为要做一些数据方面的支持,所以这些数据我也需要。因此数据库里会出现词条名字相同但url不同的两个或以上数据,所以不要奇怪以为爬重复了。用Pyspider框架可以设置age不会在时间内重复请求。
还有一些数据fetch_error,如果网不好不必担心还能再次fetch到,但也有些数据得完善代码才能拿到(有的url格式很怪正则能匹配到,但就是fetch_error似乎是编码问题,但这样的数据量很少80万数据也就几百,一般是某个电器的型号)。
写完了才发现代码没写注释。。。耐心看吧,新手所以写代码水平比较差,大家多包涵....