解决Spark窗口统计函数rank()、row_number()、percent_rank()不能忽略空值问题
目录
【问题背景】
【解决方法1:计算空值占比、非空排序最小值,对结果进行映射】
【解决方法2:将排序列单独选出来,filter空值后再排序】
【解决方法3:进行两次排序,根据两次排序结果计算最终结果】
【优缺点对比】
【解决方法推荐】
【问题背景】
假如我们手头上有100w篇文章,想根据阅读量、点赞率对文章进行评分(阅读量>1000时,点赞率才有效)。这里拿5篇文章作为例子,构造一个三列的dataFrame:msg_id(文章ID), like_rate(点赞率), read_cnt(阅读量),取值为:
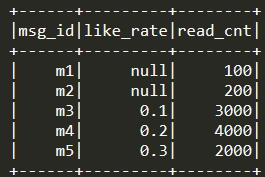
对like_rate进行percent_rank(),从文章m1到m5,
期望的结果是:null, null, 0.0, 0.5, 1.0
实际的结果是:0.0, 0.0, 0.5, 0.75, 1.0
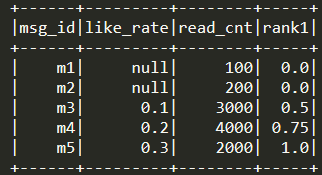
空值也参与到排序里面去了,得不到预期的结果。如果99%的文章的点赞率字段都为空,会使得有点赞率的文章的点赞率排序结果挤在[0.99, 1.0],没点赞率的文章得分全为0,不同点赞率的文章得分没有区分性。附上此例子代码:
package high_quality._history
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
object test {
def main(args: Array[String]) {
Logger.getRootLogger.setLevel(Level.ERROR)
val spark = SparkSession.builder().master("local[*]").getOrCreate()
import spark.implicits._
var df = Seq(("m1", 0.4, 100), ("m2", 0.5, 200), ("m3", 0.1, 3000), ("m4", 0.2, 4000), ("m5", 0.3, 2000))
.toDF("msg_id", "like_rate", "read_cnt")
.withColumn("like_rate", when($"read_cnt" > 1000, $"like_rate"))
.withColumn("rank1", percent_rank().over(Window.orderBy("like_rate")))
df.orderBy("msg_id").show()
}
}【解决方法1:计算空值占比、非空排序最小值,对结果进行映射】
看完上述例子,相信大家都能想到:将得分为0的文章,得分改为0.5;将得分>0的文章,通过 (x-0.99) / (1 - 0.99)的方式便能映射到[0, 1]区间上。
问题的关键就是要知道非空的数据量有多大,可以计算点赞率非空的数据的最小排序取值,也可以直接统计取值为空的数据量:
(1)计算点赞率非空数据的最小取值
df.persist()
// 计算点赞率非空数据的排序最小值
val min_rank_like_rate = df
.withColumn("tmp_rank", when($"rank1" > 0, $"rank1"))
.select(min("tmp_rank")).rdd.collect()(0)(0).toString.toDouble
// 取值缩放
df = df
.withColumn("rank2", when($"rank1" === 0, 0.5).
otherwise(($"rank1" - min_rank_like_rate) / (1 - min_rank_like_rate)))
df.show()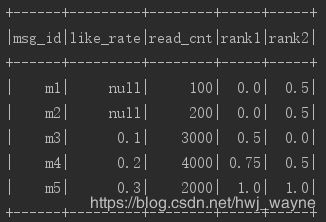
(2)计算非空数据的占比
df.persist()
// 计算空值占比(注意最终结果取值为[0,1],因此需要将数据总量减去1)
val null_ratio = df
.withColumn("is_null", when($"like_rate".isNull, 1))
.select(sum("is_null") / (sum(lit(1)) - 1)).rdd.collect()(0)(0).toString.toDouble
// 取值缩放
df = df
.withColumn("rank3", when($"rank1" === 0, 0.5).
otherwise(($"rank1" - null_ratio) / (1 - null_ratio)))
df.show()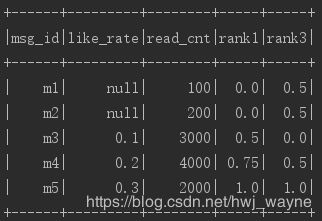
若在percent_rank()过程中需要partitionBy()操作。在计算非空最小值、空值占比后可以重新join到原数据上,或者写一个udf函数来对每一行做map,后者计算量低一点。这里只抛砖引玉一下。
【解决方法2:将排序列单独选出来,filter空值后再排序】
既然空值造成了影响,那就先把空值放一边,先对非空数据拉出来排序,排完再join回去:
df.persist()
// 提取非空数据进行排序
val not_null_rank = df
.filter($"like_rate".isNotNull)
.withColumn("rank4", percent_rank().over(Window.orderBy("like_rate")))
.select("msg_id", "rank4")
df = df.join(not_null_rank, Seq("msg_id"), "left")
.withColumn("rank4", when($"rank4".isNotNull, $"rank4").otherwise(0.5))
df.show()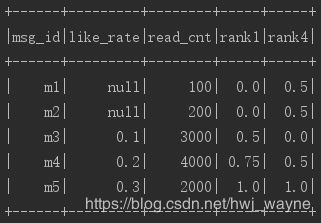
【解决方法3:进行两次排序,根据两次排序结果计算最终结果】
注意到percent_rank()函数orderBy()内的内容后输入一个小数点后还有可选的接口:
留意其中四个选择:
asc_nulls_first:升序排序,空值放最前
asc_nulls_last:升序排序,空值放最后
desc_nulls_first:降序排序,空值放最前
desc_nulls_last:降序排序,空值放最后
对于刚才的例子: null, null, 0.1, 0.2, 0.3,四个选择的排序结果分别是:
asc_nulls_first: 0.0, 0.0, 0.5, 0.75, 1.0
asc_nulls_last: 0.75, 0.75, 0.0, 0.25, 0.5
desc_nulls_first:0.0, 0.0, 1.0, 0.75, 0.5
desc_nulls_last:0.75, 0.75, 0.5, 0.25, 0.0
前两种选择或后两种选择单独对比就会发现,对于点赞率非空的数据,两种结果相减,能得到点赞率非空数据的排序结果的最小值,用这个最小值映射一下就能得到最终结果:
df = df
.withColumn("rank5", percent_rank().over(Window.orderBy($"like_rate".asc_nulls_first)))
.withColumn("rank6", percent_rank().over(Window.orderBy($"like_rate".asc_nulls_last)))
.withColumn("min_rank", $"rank5" - $"rank6")
.withColumn("rank7", when($"like_rate".isNull, 0.5).
otherwise(($"rank5" - $"min_rank") / (lit(1) - $"min_rank")))
df.show()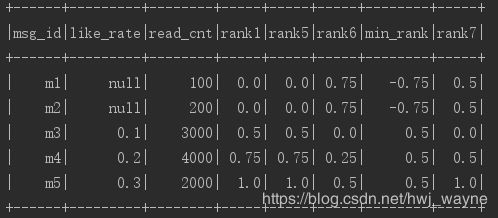
【优缺点对比】
方法1、计算空值占比、非空排序最小值,对结果进行映射:
优点:
(1)逻辑简单,不易出错。
(2)计算消耗相对较低。
缺点:
(1)需要对数据进行persist()
(2)若percent_rank()时需要partitionBy()操作,则可能额外增加一次shuffle操作(在join的步骤)
(3)当spark脚本中多个中间过程需要排序,怎会由于persist增加大量消耗。
方法2、将排序列单独选出来,filter空值后再排序:
优点:
(1)逻辑简单,不易出错。
(2)每一次percent_rank()接受的数数据量较小,降低了计算消耗。
缺点:
(1)需要对数据进行persist()
(2)每排序一列就需要额外join一次,计算消耗巨大,速度很慢
(3)当DAG链过长时会造成OOM问题,可通过中途persist()解决。假设DAG链能容忍连续70次transform操作,则每对35个字段进行排序就需要一次persist操作(每个字段都涉及一次percent_rank和join操作),而方法1可以每70个字段才persist()。
(4)当spark脚本中多个中间过程需要排序,怎会由于persist增加大量消耗。
方法3、进行两次排序,根据两次排序结果计算最终结果:
优点:
(1)不需要persist()
(2)编程灵活性较好
缺点:
(1)逻辑复杂,需要对边际条件有充分考虑,容易出错
(2)额外增加了一倍percent_rank()操作(计算消耗比方法2所增加的join少)
(3)与方法2一样,对DAG链不友好
【解决方法推荐】
(1)当内存充足,而且数据较小(persist带来的I/O消耗不大),首选方法1
(2)当代码较长(涉及到非常多的中间转换),或追求编程规范性、灵活性,首选方法3
(3)当需要partitionBy(),而且又怕出错、需要排序的字段不多时,推荐方法2
个人强烈推荐方法3,虽然相比方法1会牺牲一点点CPU消耗,但是能节省内存,而且规范性好很多。由于方法3有较多边际情况容易出错,因此鄙人将其封装成一个函数,具体如下:
// 忽略空值的percent_rank()
val NEG_PLACEHOLDER=-999
def df_percent_rank_ignore_null(df: DataFrame, prefix: String, cols: Seq[String], par_key: Seq[String] = List(), na_fill_value: Double = PESUDO_NULL, neg_placeholder_to_null: Boolean = true): DataFrame = {
/*
注意:空值需要设置为:null、NEG_PLACEHOLDER 或 PESUDO_NULL
在percent_rank过程中忽略null数据,[null, null, null, 1, 2, 3]为[null, null, null, 0, 0.5, 1.0] (原本是[0, 0, 0, 0.6, 0.8, 1.0])
需要额外消耗多一次percent_rank操作,但不需要persist数据。
row_number()不需要此接口,只需要排序的时候指定 .desc_nulls_last并确保null数据不取row_number结果
[args]
df: 需要排序的dataFrame
prefix: 字段排序后新增前缀
cols: 排序的字段,Window.partitionBy().orderBy()中的orderBy的参数
par_key: 分区字段,Window.partitionBy().orderBy()中的partitionBy的参数。默认为空
na_fill_value: 对于null数据,排序后的填充值
neg_placeholder_to_null: 若字段取值等于NEG_PLACEHOLDER,则将字段转换成null
*/
var rank_df = df
// 输入字段判断。若取值为PESUDO_NULL、NEG_PLACEHOLDER则置为null
val to_null_list = if (neg_placeholder_to_null) List(PESUDO_NULL, NEG_PLACEHOLDER) else List(PESUDO_NULL)
for (f <- cols) rank_df = rank_df.withColumn(f, when(!col(f).cast(DoubleType).isin(to_null_list: _*), col(f)))
// 字段排序
for (f <- cols) {
rank_df = if (par_key.nonEmpty)
rank_df
.withColumn("rnk_asc_null_last_" + f, when(col(f).isNotNull,
percent_rank().over(Window.partitionBy(par_key.head, par_key.tail: _*).orderBy(col(f).asc_nulls_last))))
.withColumn("rnk_asc_null_first_" + f, when(col(f).isNotNull,
percent_rank().over(Window.partitionBy(par_key.head, par_key.tail: _*).orderBy(col(f).asc_nulls_first))))
else
rank_df
.withColumn("rnk_asc_null_last_" + f, when(col(f).isNotNull,
percent_rank().over(Window.orderBy(col(f).asc_nulls_last))))
.withColumn("rnk_asc_null_first_" + f, when(col(f).isNotNull,
percent_rank().over(Window.orderBy(col(f).asc_nulls_first))))
rank_df = rank_df
.withColumn(prefix + f, when(col("rnk_asc_null_last_" + f) - col("rnk_asc_null_first_" + f) + 1 === 0, 0).otherwise(
col("rnk_asc_null_last_" + f) / (col("rnk_asc_null_last_" + f) - col("rnk_asc_null_first_" + f) + 1)))
.drop("rnk_asc_null_last_" + f, "rnk_asc_null_first_" + f)
// 输出字段处理
if (na_fill_value != PESUDO_NULL) rank_df = rank_df.na.fill(Map(prefix + f -> na_fill_value))
}
rank_df
}假如想对dataFrame a进行排序,排序列是 c1和c2,根据k1来做partitionBy,空值填充为0.5 (这里把null和NEG_PLACEHOLDER都同时认为是空值了,NEG_PLACEHOLDER这个变量是为了一定的编程灵活性,如果不想要这个特性,可以把参数neg_placeholder_to_null置为false),排序后给原字段增加前缀"s_",那么可以这么编写:
var df :DataFrame = null // 构造一个伪DF
df = df_percent_rank_ignore_null(df,prefix = "s_",cols=List("c1","c2"),par_key = List("k1"),na_fill_value = 0.5)