以太坊的数据结构(状态树、交易树、收据树)及代码分析
文章目录
- 一、状态树
- 1.1 trie
- 1.2 Patricia tree(trie)
- 1.3 Merkle Patricia tree(trie)
- 1.4 Modified Merkle Patricia tree(trie)
- 1.5 账户状态值存储
- 二、交易树、收据树
- 2.1 概述
- 2.2 Modified Merkle Patricia tree(trie)
- 2.3 布隆过滤器(bloom filter)
- 2.4 总结:交易驱动的状态机
- 三、区块及数据结构代码分析
- 3.1 区块信息结构体
- 3.2 交易树和收据树的创建
- 3.3 bloom filter的创建和查询
一、状态树
以太坊是基于账户的账本,因此需要进行账户地址和账户状态的映射,如下所示:

我们尝试寻找一种合适的数据结构来完成这个需求:
- 如果以哈希表的形式保存状态数据,可以非常有效率地查找、更新账户状态数据,但是由于状态数据只保存在区块体中,轻节点难以进行Merkle Proof,那么接下来考虑构建Merkle tree;
- 如果将账户数据简单组织成Merkle tree,不进行排序,就需要发布所有账户到区块中,保证根哈希一致,但是数量级太大,不可行;如果只发布状态变化的账户,就会导致所有节点的根哈希不一致,无法共识;
- 如果使用排序的Merkle tree,各个节点的根哈希就会相同,但是增加账户时,需要重构Merkle tree,代价太大。另外Merkle tree不能够快速查找、更新状态数据。以太坊中使用的是一种新的数据结构Merkle Patricia trie。
1.1 trie
trie是一种字典前缀树,信息检索较为方便。如果有General、Genesis、Go、God、Good这几个单词,组成trie如下所示:
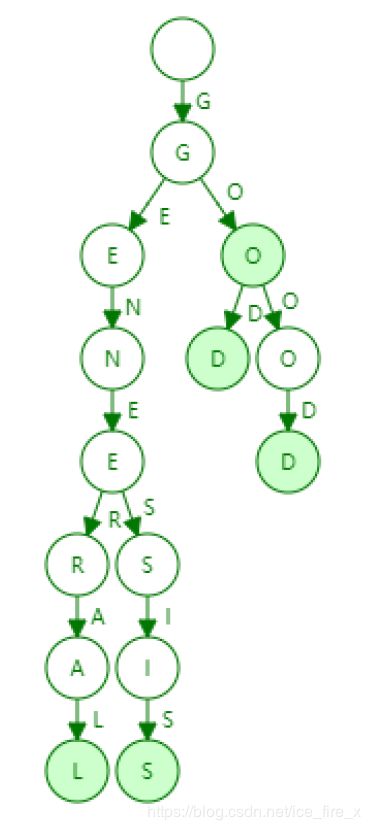
- 每个节点的分支取决于元素范围,上面例子中为26个英文字母和结束标志,最多27个分叉。在以太坊中使用16进制(0~F)表示账户,加上结束标志,最多17个分支;
- 查找效率取决于key值长度,键值越长,查找访问次数越多。以太坊中账户为40位16进制数,因此查找长度固定是40;
- 不会出现碰撞,哈希表则有碰撞的问题;
- 给定一组输入,构成的trie一致;
- 更新数据非常容易,只需访问局部分支。
1.2 Patricia tree(trie)
Patricia tree称为路径压缩前缀树,可以节省存储空间,同时还可以降低了查找访问次数,提高查找效率。例如将上例中的trie改进为Patricia tree,如下图所示:
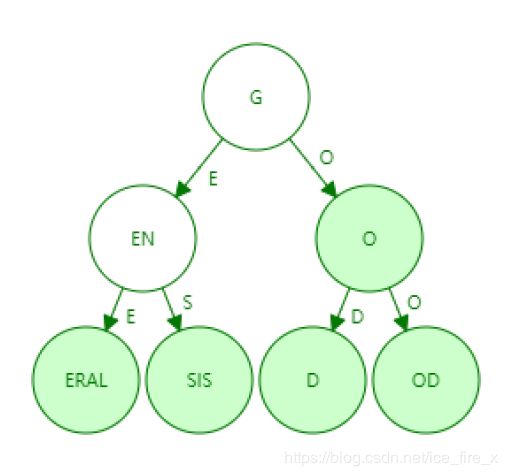
Patricia tree适合键值分布比较稀疏的数据,压缩效果比较明显,如下图所示:
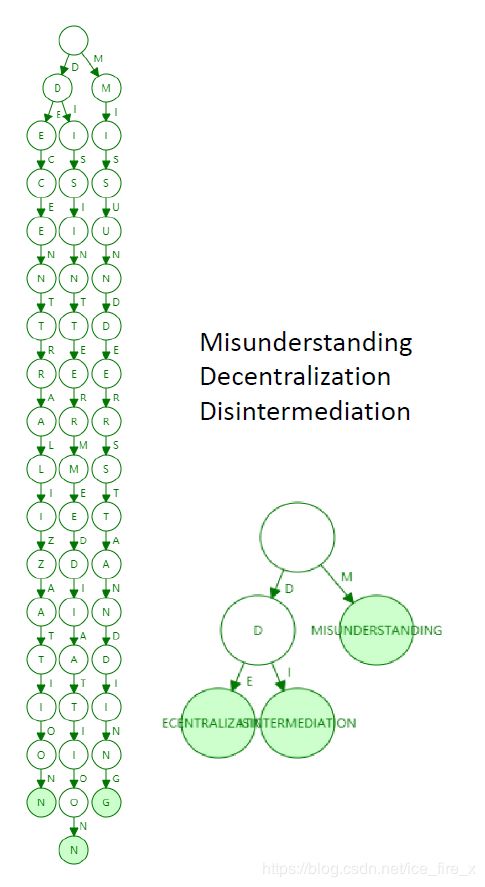
在以太坊中,为防止碰撞,使用了160bit长的账户,非常稀疏,因此适合使用Patricia tree数据结构。
1.3 Merkle Patricia tree(trie)
将Patricia tree的指针全部换成哈希指针,就构建成了Merkle Patricia tree,可以计算出根哈希值,保存在区块头中。
- 通过根哈希保证树不被篡改,每个账户的状态都是不可篡改的;
- 通过Merkle proof,可以用来证明任意一个账户的状态,比如账户余额;
- 通过Merkle proof,可以证明某个账户不存在。
1.4 Modified Merkle Patricia tree(trie)
以太坊使用的是修改版的Merkle Patricia tree,与Merkle Patricia tree没有本质区别。例如下图中有4个7位的地址,保存账户余额信息(value),树中有3种节点,每个节点存储关联节点的哈希值:
- Extension Node:扩展节点,保存路径压缩压缩数据,即shared nibbles中保存的16进制数据;
- Branch Node:分支节点,无法压缩;
- Leaf Node:叶子节点,保存账户状态数据;
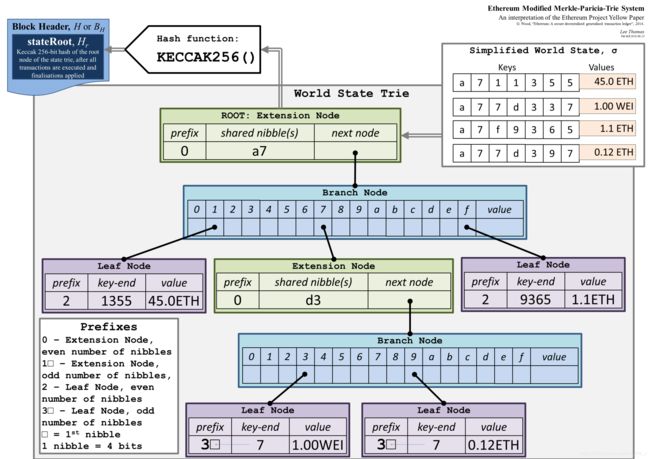
新发布一个区块的时候,某些账户的状态会发生变化,新区快中会为变化的账户重新建立分支,大部分不变的数据则指向历史区块中的分支,因此区块间会共享大部分不变的状态分支。如下图所示:
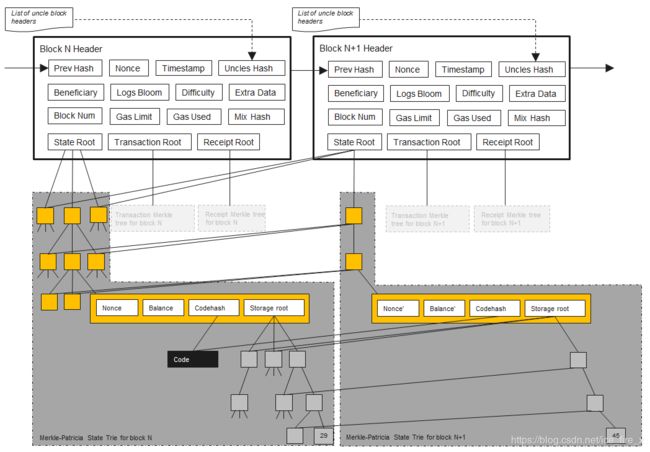
保留历史状态的好处:
未胜出的临时性分叉需要回滚才能继续出块,由于智能合约的执行不易反推执行,保留起始与结束的记录,回滚才比较方便。
账户树中保存全部账户信息的原因:
查找某个账户更快速,如果区块内只保存区块内交易的相关账户信息,查询某个很久没有交易的账户就要花费很长时间,最坏的情况是如果转账给一个从未进行交易的账户,就必须追溯到创世区块,最后有可能发现区块内没有该账户的信息。
1.5 账户状态值存储
账户状态数据经过RLP(Recursive Length Prefix)序列化后存储,RLP序列化方式相比protobuf较为简单,只支持字符嵌套数组(nested array of bytes),实现起来比较容易。
二、交易树、收据树
2.1 概述
区块内的交易列表组成交易树,与比特币的Merkle tree作用类似。
每个交易执行完会有一个收据,记录这个交易的相关信息,与交易树上的节点一一对应。以太坊中以太坊的智能合约执行过程比较复杂,增加收据树,有助于快速查询一些交易执行结果。
2.2 Modified Merkle Patricia tree(trie)
交易树与收据树同样采用的是MPT数据结构,这样三棵树的代码更加统一,便于管理。同时MPT具有良好的数据查询性能。
与状态树不同的是,交易树和收据树都只把当前区块发布的交易包含进来,独立于其他区块,没有共享分支。
MPT的作用:
MPT可以给轻节点提供Merkle proof,交易树可以证明某个交易确实属于某个区块,收据树同样可以证明某个交易结果。
2.3 布隆过滤器(bloom filter)
布隆过滤器给包含很多元素的集合计算出一个很紧凑的摘要,用较少的空间来表示较大集合的存在关系,可以高效地查找某个元素是否在一个大的集合里。
对于给定输入集合,用Hash函数给集合中元素分别计算出地址,分别在位串的这些地址上标记为1。在查找时,进行同样的计算过程,并查看位串上的元素,如果是 1,则说明较大概率是存在该输入。如下图所示:

通常用多个哈希函数来防止哈希碰撞,可以降低误判率,仍存在着误报(FalsePositive)的情况,但绝对不会漏报(False Negative)。
布隆过滤器的作用:
每个交易执行完会形成一个收据,收据里面包含bloom filter,记录交易类型、地址等信息,发布的区块头里面会有一个总的bloom filter,是区块内所有交易的bloom filter的并集,根据区块头里的bloom filter,即使是轻节点就可以过滤掉大部分区块,然后向全节点请求候选区块体数据,查询区块内每个交易的bloom filter,得知哪些区块有想要的交易,当然也有可能某些区块是误报,里面没有想要的交易。
如上所述,交易树通过布隆过滤器可以进行更加复杂的查询,比如查询过去10天跟某个智能合约所有有关的交易,或者查询过去10天内某种类型(众筹、发行新币等)的事件。
2.4 总结:交易驱动的状态机
以太坊是一个交易驱动的状态机(transaction-driven state machine),状态指的是所有账户的状态,即状态树包含的内容,交易指的是区块内包含的那些交易,通过执行这些交易会驱动系统从当前状态转移到下一个状态,且状态的转移具有确定性。
比特币同样可以认为是一个交易驱动的状态机,比特币的状态是UTXO,每次发布的区块内的交易会驱动状态机从当前状态确定地转移到下一个状态。
三、区块及数据结构代码分析
3.1 区块信息结构体
区块头的结构定义如下所示:
ParentHash表示父区块的哈希,UncleHash是叔父区块哈希,Coinbase是示矿工账户地址,Root是状态树的根哈希,TxHash是交易树的根哈希,ReceiptHash是收据树的根哈希,Bloom是块头的bloom filter,Difficulty是挖矿难度(可根据需要调整),GasLimit和GasUsed与汽油费相关,Time是区块大致产生时间,MixDigest与挖矿过程相关,从Nonce经过一些列计算而来,Nonce是挖矿的谜底随机数。
// Header represents a block header in the Ethereum blockchain.
type Header struct {
ParentHash common.Hash `json:"parentHash" gencodec:"required"`
UncleHash common.Hash `json:"sha3Uncles" gencodec:"required"`
Coinbase common.Address `json:"miner" gencodec:"required"`
Root common.Hash `json:"stateRoot" gencodec:"required"`
TxHash common.Hash `json:"transactionsRoot" gencodec:"required"`
ReceiptHash common.Hash `json:"receiptsRoot" gencodec:"required"`
Bloom Bloom `json:"logsBloom" gencodec:"required"`
Difficulty *big.Int `json:"difficulty" gencodec:"required"`
Number *big.Int `json:"number" gencodec:"required"`
GasLimit uint64 `json:"gasLimit" gencodec:"required"`
GasUsed uint64 `json:"gasUsed" gencodec:"required"`
Time uint64 `json:"timestamp" gencodec:"required"`
Extra []byte `json:"extraData" gencodec:"required"`
MixDigest common.Hash `json:"mixHash"`
Nonce BlockNonce `json:"nonce"`
}
区块结构如下所示:
header为指向区块头(Header)的指针,uncles为指向叔父区块头的指针,transactions为区块内的交易列表。
// Block represents an entire block in the Ethereum blockchain.
type Block struct {
header *Header
uncles []*Header
transactions Transactions
// caches
hash atomic.Value
size atomic.Value
// Td is used by package core to store the total difficulty
// of the chain up to and including the block.
td *big.Int
// These fields are used by package eth to track
// inter-peer block relay.
ReceivedAt time.Time
ReceivedFrom interface{}
}
发布的区块信息:
extblock为发布到网络中的区块信息,包括区块头、交易列表、叔父区块头。
// "external" block encoding. used for eth protocol, etc.
type extblock struct {
Header *Header
Txs []*Transaction
Uncles []*Header
}
3.2 交易树和收据树的创建
NewBlock函数里包含交易树、收据树的创建以及叔父区块处理。
创建交易树的步骤:
- 判断交易列表是否为空,如果为空,那么块头的根哈希就是空哈希值
- 如果不为空,调用DeriveSha函数得到交易树的根哈希值
- 然后创建区块的交易列表
创建收据树的步骤:
- 判断收据列表是否为空,如果为空,那么根哈希就是空哈希值
- 如果不为空,调用DeriveSha函数得到收据树的根哈希值
- 然后调用CreateBloom函数创建块头里的bloom filter
处理叔父区块:
- 判断叔父区块列表是否为空,如果为空,那么块头的叔父区块哈希值就是空的哈希值
- 如果不为空,调用CalcUncleHash计算哈希值
- 通过一个循环构建区块里的叔父数组
如下所示:
// NewBlock creates a new block. The input data is copied,
// changes to header and to the field values will not affect the
// block.
//
// The values of TxHash, UncleHash, ReceiptHash and Bloom in header
// are ignored and set to values derived from the given txs, uncles
// and receipts.
func NewBlock(header *Header, txs []*Transaction, uncles []*Header, receipts []*Receipt) *Block {
b := &Block{header: CopyHeader(header), td: new(big.Int)}
// TODO: panic if len(txs) != len(receipts)
if len(txs) == 0 {
b.header.TxHash = EmptyRootHash
} else {
b.header.TxHash = DeriveSha(Transactions(txs))
b.transactions = make(Transactions, len(txs))
copy(b.transactions, txs)
}
if len(receipts) == 0 {
b.header.ReceiptHash = EmptyRootHash
} else {
b.header.ReceiptHash = DeriveSha(Receipts(receipts))
b.header.Bloom = CreateBloom(receipts)
}
if len(uncles) == 0 {
b.header.UncleHash = EmptyUncleHash
} else {
b.header.UncleHash = CalcUncleHash(uncles)
b.uncles = make([]*Header, len(uncles))
for i := range uncles {
b.uncles[i] = CopyHeader(uncles[i])
}
}
return b
}
DeriveSha函数如下所示,创建了trie结构体:
func DeriveSha(list DerivableList) common.Hash {
keybuf := new(bytes.Buffer)
trie := new(trie.Trie)
for i := 0; i < list.Len(); i++ {
keybuf.Reset()
rlp.Encode(keybuf, uint(i))
trie.Update(keybuf.Bytes(), list.GetRlp(i))
}
return trie.Hash()
}
Trie是一个Merkle Patricia Trie,如下所示:
// Trie is a Merkle Patricia Trie.
// The zero value is an empty trie with no database.
// Use New to create a trie that sits on top of a database.
//
// Trie is not safe for concurrent use.
type Trie struct {
db *Database
root node
}
3.3 bloom filter的创建和查询
每个交易执行完,形成一个收据,记录交易执行结果,其中Status为交易执行情况。如下所示,Bloom域即布隆过滤器,每个收据可以包含多个Log,Bloom就是根据Log产生的:
// Receipt represents the results of a transaction.
type Receipt struct {
// Consensus fields: These fields are defined by the Yellow Paper
PostState []byte `json:"root"`
Status uint64 `json:"status"`
CumulativeGasUsed uint64 `json:"cumulativeGasUsed" gencodec:"required"`
Bloom Bloom `json:"logsBloom" gencodec:"required"`
Logs []*Log `json:"logs" gencodec:"required"`
// Implementation fields: These fields are added by geth when processing a transaction.
// They are stored in the chain database.
TxHash common.Hash `json:"transactionHash" gencodec:"required"`
ContractAddress common.Address `json:"contractAddress"`
GasUsed uint64 `json:"gasUsed" gencodec:"required"`
// Inclusion information: These fields provide information about the inclusion of the
// transaction corresponding to this receipt.
BlockHash common.Hash `json:"blockHash,omitempty"`
BlockNumber *big.Int `json:"blockNumber,omitempty"`
TransactionIndex uint `json:"transactionIndex"`
}
块头里Bloom域就是通过CreateBloom函数创建的,由这个块中所有receipts的Bloom Filter组合得到。
CreateBloom的参数是区块的所有收据,通过for循环对每个收据调用LogsBloom函数来生成收据的Bloom Filter,通过Or函数合并这些Bloom Filter,得到整个区块的Bloom Filter。
LogsBloom函数的功能是生成收据的Bloom Filter,参数为Receipt结构体里的Log数组,外层循环对log数组里的每个log进行处理,把log的地址取哈希后加到Bloom Filter里,内层循环把log包含的每个topic包含到Bloom Filter里。这样就得到了收据的Bloom Filter。
bloom9函数是Bloom Filter中使用的哈希函数,把输入映射到digest的3个位置,这3个位置的值置为1。首先生成参数的32字节哈希值,然后是3轮循环,取前6字节,每2个字节一组,拼接在一起,和2047进行“与运算”(相当于对2048取余),得到2047区间内的数,之所以这样做是因为以太坊Bloom Filter的长度是2048,然后将数字1左移这么多的长度,然后合并到上一轮得到的Bloom Filter,3轮循环结束后,就得到了3个位置被置为1的Bloom Filter。
BloomLookup函数的功能是查询Bloom Filter中是否有感兴趣的topic,首先调用bloom9函数将topic转换成bit数据,然后和Bloom Filter进行“与运算”,这样Bloom Filter有其他的topic也不会有影响,然后再跟自身比较,如果相等,说明Bloom Filter中对应位置确实是1,即该Bloom Filter中包含感兴趣的topic。
func CreateBloom(receipts Receipts) Bloom {
bin := new(big.Int)
for _, receipt := range receipts {
bin.Or(bin, LogsBloom(receipt.Logs))
}
return BytesToBloom(bin.Bytes())
}
func LogsBloom(logs []*Log) *big.Int {
bin := new(big.Int)
for _, log := range logs {
bin.Or(bin, bloom9(log.Address.Bytes()))
for _, b := range log.Topics {
bin.Or(bin, bloom9(b[:]))
}
}
return bin
}
func bloom9(b []byte) *big.Int {
b = crypto.Keccak256(b)
r := new(big.Int)
for i := 0; i < 6; i += 2 {
t := big.NewInt(1)
b := (uint(b[i+1]) + (uint(b[i]) << 8)) & 2047
r.Or(r, t.Lsh(t, b))
}
return r
}
var Bloom9 = bloom9
func BloomLookup(bin Bloom, topic bytesBacked) bool {
bloom := bin.Big()
cmp := bloom9(topic.Bytes())
return bloom.And(bloom, cmp).Cmp(cmp) == 0
}