CPU软中断概念与案例
CPU软中断概念&案例
1 案例一
1.1 环境部署
环境1:WEB服务器
docker run -itd --name=nginx -p 80:80 nginx
环境2:SYN攻击
curl http://xxx.xxx.xxx.xxx/
Welcome to nginx!
...
# -S 参数表示设置 TCP 协议的 SYN(同步序列号),-p 表示目的端口为 80
# -i u100 表示每隔 100 微秒发送一个网络帧
# 注:如果你在实践过程中现象不明显,可以尝试把 100 调小,比如调成 10 甚至 1
$ hping3 -S -p 80 -i u1 xxx.xxx.xxx.xxx
1.2 分析过程
1、CPU使用率不高但是软中断已经到了10%,从非idle状态的全部用在了软中断上面。

2、确认是哪个软中断导致的问题
watch -d cat /proc/softirqs
TIMER(定时中断)、NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)中,网络接收变化最快。

3、确认了网络问题,继续观察下网络收发包的情况
# -n DEV 表示显示网络收发的报告,间隔 1 秒输出一组数据
sar -n DEV 1
报告时间 | 网卡 | rxpck/s txpck/s收发帧数 | exkB/s txkB/s收发千字节数
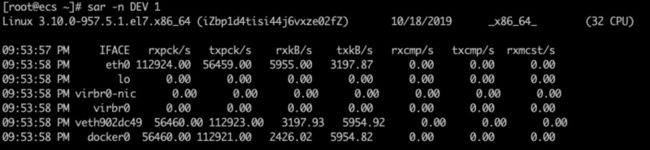
- 对网卡et0来说,收帧很大112924.00,但是数据量很小5955.00。
- 计算一下
5955.00*1024Byte/112924.00=54Byte平均每个包只有54字节即小包问题。
4、抓包确认问题
tcpdump -i eth0 -n tcp port 80
21:59:25.549573 IP 源端.40615 > 目标端.http: Flags [S], seq 270293337, win 512, length 0
21:59:25.549592 IP 源端.40616 > 目标端.http: Flags [S], seq 830767629, win 512, length 0
Flags [S]表示syn包,PPS超过1.2W确认syn flood攻击。
2 案例二
sysbench测试发现系统大量net中断

分析网络流量
sar -n DEV 1
07:33:55 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
07:33:56 PM eth0 124048.00 319294.00 10680.15 219670.82 0.00 0.00 1.00
07:33:56 PM eth1 117075.00 325641.00 14828.60 227463.34 0.00 0.00 0.00
07:33:56 PM lo 73.00 73.00 53.75 53.75 0.00 0.00 0.00
- 同样收帧很大124048.00每秒,但是数据量还不算大
10680.15*1024Byte/124048=88.16Byte字节
进一步分析数据包
sudo tcpdump -i eth0 tcp and port 3001 -n -nn -s0 -tttt -w mysql.cap
tcpdump -r mysql.cap | more
没有使用连接池大量短连接问题!
2 概念
2.1 软中断概念
linux的中断会打断CPU当前的工作,中断一般都设计的短小精悍。但是也为了解决中断处理程序执行时间过长和中断丢失的问题,Linux的中断分为两个阶段:
- 上半部用来快速处理中断,它在中断禁止模式下运行,主要处理硬件相关和时间敏感的工作
- 下半部用来延迟处理上半部未完成的工作,通常以内核线程的方式运行
网卡收数据包的例子:
网卡收到数据包后会通过硬件中断的方式,通知内核有新的数据到了:对上半部来说,既然是快速处理,其实就是要把网卡的数据读到内存中,然后更新一下硬件寄存器的状态(表示数据已经读好了),最后再发送一个软中断信号,通知下半部做进一步的处理。而下半部被软中断信号唤醒后,需要从内存中找到网络数据,再按照网络协议栈,对数据进行逐层解析和处理,直到把它送给应用程序。
- 上半部直接处理硬件请求,也就是我们常说的硬中断,特点是快速执行
- 而下半部则是由内核触发,也就是我们常说的软中断,特点是延迟执行
实际上,上半部会打断 CPU 正在执行的任务,然后立即执行中断处理程序。而下半部以内核线程的方式执行,并且每个CPU都对应一个软中断内核线程,名字为 “ksoftirqd/CPU 编号”,比如说, 0 号 CPU 对应的软中断内核线程的名字就是 ksoftirqd/0。不过要注意的是,软中断不只包括了刚刚所讲的硬件设备中断处理程序的下半部,一些内核自定义的事件也属于软中断,比如内核调度和RCU 锁(Read-Copy Update 的缩写,RCU是 Linux 内核中最常用的锁之一)等。
2.2 查看软中断和内核线程
- /proc/softirqs 提供了软中断的运行情况;
- /proc/interrupts 提供了硬中断的运行情况。
运行下面的命令,查看 /proc/softirqs 文件的内容,你就可以看到各种类型软中断在不同 CPU 上的累积运行次数
在查看 /proc/softirqs 文件内容时,你要特别注意以下这两点。
-
第一,要注意软中断的类型,也就是这个界面中第一列的内容。从第一列你可以看到,软中断包括了 10 个类别,分别对应不同的工作类型。比如 NET_RX 表示网络接收中断,而 NET_TX 表示网络发送中断。
-
第二,要注意同一种软中断在不同 CPU 上的分布情况,也就是同一行的内容。正常情况下,同一种中断在不同 CPU 上的累积次数应该差不多。比如这个界面中,NET_RX 在 CPU0 和 CPU1 上的中断次数基本是同一个数量级,相差不大。
不过你可能发现,TASKLET 在不同 CPU 上的分布并不均匀。TASKLET 是最常用的软中断实现机制,每个 TASKLET 只运行一次就会结束 ,并且只在调用它的函数所在的 CPU 上运行。
因此,使用 TASKLET 特别简便,当然也会存在一些问题,比如说由于只在一个 CPU 上运行导致的调度不均衡,再比如因为不能在多个 CPU 上并行运行带来了性能限制。
另外,刚刚提到过,软中断实际上是以内核线程的方式运行的,每个 CPU 都对应一个软中断内核线程,这个软中断内核线程就叫做 ksoftirqd/CPU 编号。那要怎么查看这些线程的运行状况呢?
其实用 ps 命令就可以做到,比如执行下面的指令:
$ ps aux | grep softirq
root 7 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/0]
root 16 0.0 0.0 0 0 ? S Oct10 0:01 [ksoftirqd/1]
这些线程的名字外面都有中括号,这说明 ps 无法获取它们的命令行参数(cmline)。一般来说,ps 的输出中,名字括在中括号里的,一般都是内核线程。