Flink学习 - 6. Flink on yarn 提交流程 及 资源管理
Flink学习 - 6. Flink on yarn 提交流程 及 资源管理
- Flink On Yarn
- Flink On Yarn 执行任务两种方式
- Flink Session (Session-Cluster)
- Flink run (Per-Job-Cluster)
- 提交流程
- Flink资源管理
- JobManager(master)
- TaskManager(workers)
- job
- subtask
- task 和 operator chains
- slot
- 共享Slot : SlotSharingGroup 和 CoLocationGroup
Flink On Yarn
Flink On Yarn 执行任务两种方式
Flink Session (Session-Cluster)
在yarn上启动一个守护进程,用于启动多个job,即启动一个application master 用来管理多个job
启动命令:
./yarn-session.sh -n 4 -jm 1024 -tm 5120 -s 5 -nm yarn-session-jobs -d
参数说明:
- -n : 指定number of task manager,指定taskmanager个数
- -jm: jobmanager所占用的内存数,单位为MB
- -tm: 指定每个taskmanager所占用的内存,单位为MB
- -s: 指定每个taskmanager可使用的cpu核数
- -nm: 指定Application的名称
- -d : 后台启动,session启动后,进程关闭
启动流程说明:
(1) 启动session 后,yarn首先会分配一个Container,用于启动APP master和jobmanager, 所占用内存为-jm指定的内存大小,cpu为1核
(2) 没有启动job之前,jobmanager是不会启动taskmanager的(jobmanager会根据job的并行度,即所占用的slots,来动态的分配taskmanager)
(3) 提交任务到APP master
./flink run -p 3 -yid application_id -d -c com.kb.rt.Test01 ~/jar/kb-1.0-SNAPSHOT.jar
用于启动一个job到指定的APP master中
参数说明:
- -p:指定任务的并行度,如果你在程序代码中指定了并行度的话,那么此处的并行度参数不起作用
- -yid:指定任务提交到哪一个application—id,默认是提交到本节点最新提交的一个application
- -c: job的主入口 + jar path
注:job参数要写在-c之前,不然指定参数不起作用…
Flink run (Per-Job-Cluster)
启动一个单独的job提交到yarn集群上,即单job单session,实现资源的完全隔离。
启动job的命令跟yarn-session 中有差异 ,通过指定 -m yarn-cluster,参数较session都带有-y
./flink run \
-m yarn-cluster \
-yn 2 \
-yjm 1024 \
-ytm 3076 \
-p 2 \
-ys 3 \
-yD name=hadoop \
-ynm RTC_KB_FLINK_TEST \
-yqu rt_constant \
-c com.kb.rt.Test02 ~/jar/kb-1.0-SNAPSHOT.jar
参数说明:
- -m :yarn-cluster,代表启动单session提交单一job
- -yn:taskmanager个数
- -yjm:jobmanager的内存占用
- -ytm:每个taskmanager的内存占用
- -ys: 每个taskmanager可使用的CPU核数
- -ynm:application 名称
- -yqu:指定job的队列名称
- -c: 程序主入口+ jar path
- -p: 指定任务的并行度
- -yD: 动态参数设置
提交流程
流程图大致如下:
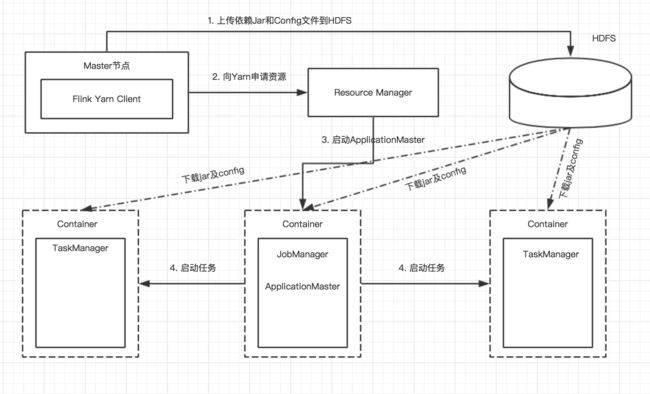
- flink-client将任务提交到yarn,会将所有依赖的jar和config等均上传到hdfs中
- 向resourceManager申请资源,Resourcemanager中主要包含两部分:ApplicationManager和resourceScheduler
- ApplicationManager启动ApplicationMaster,ResourceScheduler分配运行ApplicationMaster所需要的Container。
- 在ApplicationMaster上启动Flink的JobManager,并采用轮询的方式通过RPC向ResourceManager申请资源
- ResourceManager接收到请求后,会分配相应的Container,用于将来启动TaskManager,并从hdfs上下载相应的jar和config。
- ApplicationMater 要求相应的Container启动任务。
- 至此相应的JobManager和TaskManager启动完成。
Flink资源管理
JobManager(master)
主要用于与taskmanager通信,调度job,管理checkpoint,恢复等功能
TaskManager(workers)
主要用于执行具体的task
job
提交的任务
subtask
每个算子的一个并行化实例,可以简单理解成为 每个算子的并行度或者分区
task 和 operator chains
在整个dataflow处理过程中,存在很多operator,也可以理解成算子,相邻的operator之间存在一定的关联关系,将相邻的operator连接在一起形成chain是flink高效进行分布式计算的关键,它能够减少线程间的切换及消息的序列化和反序列化。
operator :

operator chain && task :

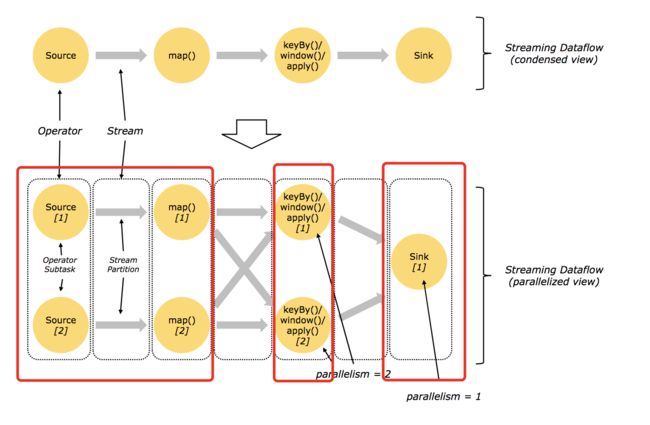
ono-to-one streams : source 和 map之间,并没有发生分区的变化以及分区间数据交换。
redistributing streams :map和keyby/window之间 以及 keyby/window和sink之间,出现了分区间数据交换或者分区数变化。
slot
slots 一般是指对于taskmanager的固定资源子集,或者说是线程。如果一个taskmanager中有3个slot,那么每个slot管理1/3的内存托管。
内存资源由于slots的存在不会出现内存竞争的情况,而slots对内存进行了隔离,但是注意的是并没有隔离cpu
Slots和parallelism是有区别的,Slot是一个静态的概念,是说taskmanager能够具有的并行执行的能力,而parallelism只有在程序执行时才有意义,是一个动态的概念,是指程序运行时实际使用的并发能力,但是两者又有关系。parallelism不能大于slots数。
共享Slot : SlotSharingGroup 和 CoLocationGroup
默认情况下,Flink 允许subtasks共享slot,条件是它们都来自同一个Job的,且拥有相同SlotSharingGroup(默认的名称是 default) 的不同task的subtask。 那么也就意味着名称不同的task的subtask之间共享到一个slot中,这样就会使得一个slot有机会持有一个完成的pipeline。因此在默认的slotsharing情况下,job启动所需要的slot数量和job中operator的最大的parallelism相等。

上图中是一个source - map - reduce 的模型job,如图中左下角显示,其中,source 和 map的 parallelism 是 4 ,reduce的 parallelism 是 3 。每个圆表示一个subtask; 而整个job中operator的最大的parallelism 是 4;如果将该任务提交执行,则可以知道job所需要的slot是 4个 ;如果将job提交到2个taskManager,每个taskmanager有3个slot,如图中右侧所示,其中有3个slot中存在有完整的 source-map-reduce 模型的pipeline。但是其中没有画出来数据进行shuffle的过程。
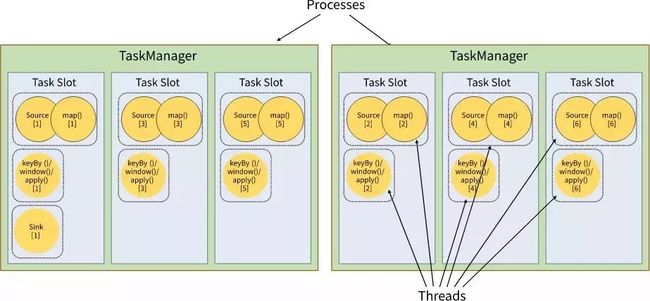
上图包含 source - map , keyBy/window/apply , sink 的模型job,其中 source-map的parallelism是6 ,keyBy/window/apply的parallelism是6 , sink的parallelism是1,那么该job提交所需要的slot为6个,分配后,左侧第一个slot中拥有完整的pipeline,运行3个subtask,其余5个slot分别运行这2个subtask,最终数据再传输给sink进行输出。