CS224n 2019 Winter 笔记(二):神经网络(矩阵求导、反向传播推导)
CS224n 2019 Winter 笔记(二):神经网络(矩阵求导、反向传播推导)
- 一、交叉熵损失函数(Cross Entropy Loss Function)
- 二、Derivative of Matrix
- (一)矩阵的几种乘积
- (1)点积(内积)
- (2)点乘(hadamard product,哈达码积)
- (3)克罗内克积(kronecker product)
- (二)矩阵的运算
- (1)微分运算
- (2)点乘运算
- (3)迹运算
- (4)其他运算
- (三)标量对矩阵求导
- (四)矩阵对矩阵求导
- (1)Jacobian Matrix
- (2)结论
- **1.矩阵乘以列向量,对列向量求导**
- **2.行向量乘以矩阵,对行向量求导**
- **3.向量对自身求导**
- **4.向量的逐元素函数求导**
- 三、人工神经元(Artificial Neurals)
- 单层的神经网络
- 多层的神经网络
- 四、神经网络(Neural Networks)
- (一)前馈计算
- (二)最大间隔目标函数(Maximum margin objection function)
- (三)反向传播
- 1、目标函数对权重的梯度计算
- 2、 δ ( k ) \boldsymbol{\delta}^{(k)} δ(k) 的解释
- 3、权重梯度的反向传播
- 4、 δ ( k + 1 ) \boldsymbol{\delta}^{(k+1)} δ(k+1) 到 δ ( k ) \boldsymbol{\delta}^{(k)} δ(k)的传播
- 5、偏置梯度
- 五、Some Tips
- Reference
笔记只记个人学习重点和难点,不追求全面,只做读书过程中的疑惑解释,既做个人心得记录,也供读者参考
如有错误,烦请留言指点,谢过!
如有错误,烦请留言指点,谢过!
如有错误,烦请留言指点,谢过!
一、交叉熵损失函数(Cross Entropy Loss Function)

上图表示某训练集 { x i , y i } i = 1 N \left\{ \boldsymbol{x}_i,y_i \right\}_{i=1}^N {xi,yi}i=1N, x i \boldsymbol{x}_i xi 是 d d d 维的输入, y i y_i yi 是标签。
传统机器学习中的线性分类器,目的就是训练出一个能够较好将样本分类的直线(或是超平面),我们令其表达式的权重表示为 W ∈ R C × d \boldsymbol{W} \in \mathbb{R}^{C \times d} W∈RC×d
在上一次课中提到,为了衡量样本 x i x_i xi 属于 y i y_i yi 类的概率,而用softmax函数来模拟其概率: p ( y ∣ x ) = exp x ∑ i = 1 C exp x i p(y|x) = \frac{\exp{x}}{\sum_{i=1}^C \exp{x}_i} p(y∣x)=∑i=1Cexpxiexpx
在线性分类器中,目标函数的优化就是为了让预测的分类 y ′ y\prime y′ 能够以1的概率接近标签值 y y y: p ( y ∣ y ′ ) = exp y ′ ∑ i = 1 C exp y i ′ → 1 y ′ = W y ⋅ x p(y|y \prime) = \frac{\exp{y \prime}}{\sum_{i=1}^C \exp{y}_i^\prime} \rightarrow 1 \quad \quad y \prime = \boldsymbol{W}_{y \cdot} \boldsymbol{x} p(y∣y′)=∑i=1Cexpyi′expy′→1y′=Wy⋅x W y ⋅ \boldsymbol{W}_{y \cdot} Wy⋅表示矩阵的行向量
所以,在这里softmax变为: p ( y ∣ x ) = exp ( W y ⋅ x ) ∑ c = 1 C exp ( W c ⋅ x ) = s o f t m a x ( f y ) p \left( \boldsymbol{y} | \boldsymbol{x} \right) = \frac{\exp{ ( \boldsymbol{W}_{y \cdot} \boldsymbol{x} )}}{ \sum_{c=1}^C \exp{( \boldsymbol{W}_{c \cdot} \boldsymbol{x} )}} = softmax(f_y) p(y∣x)=∑c=1Cexp(Wc⋅x)exp(Wy⋅x)=softmax(fy)其中, W y ⋅ x = ∑ i = 1 d W y i x i = f y \boldsymbol{W}_{y \cdot} \boldsymbol{x} = \sum_{i=1}^d \boldsymbol{W}_{yi} x_i = f_y Wy⋅x=∑i=1dWyixi=fy,这个式子也可以写成向量 $\boldsymbol{x} $ 与权重矩阵 W \boldsymbol{W} W 相乘的形式: f = W x f=\boldsymbol{W}\boldsymbol{x} f=Wx
此外,对于每一个训练样本 ( x i , y i ) (\boldsymbol{x}_i,y_i) (xi,yi)来说,训练的最终目的是为了最大化上述概率,等价于最小化该概率的负对数形式: max ( x i , y i ) { p ( y ∣ x ) } ⇔ min ( x i , y i ) { − log p ( y ∣ x ) } = min ( x i , y i ) − log ( exp ( f y ) ∑ c = 1 C exp ( f c ) ) \max_{(\boldsymbol{x}_i,y_i)} \left\{ p\left( \boldsymbol{y} | \boldsymbol{x} \right) \right \}\Leftrightarrow \min_{(\boldsymbol{x}_i,y_i)} \left\{ -\log p\left( \boldsymbol{y} | \boldsymbol{x} \right) \right \} = \min_{(\boldsymbol{x}_i,y_i)} -\log \left( \frac{\exp(f_y)}{\sum_{c=1}^C \exp(f_c)} \right) (xi,yi)max{p(y∣x)}⇔(xi,yi)min{−logp(y∣x)}=(xi,yi)min−log(∑c=1Cexp(fc)exp(fy))
如果令真实的概率分布为 p p p,预测的概率分布为 q q q,则交叉熵定义如下: H ( p , q ) = − ∑ c = 1 C p ( c ) log q ( c ) H(p,q) = -\sum_{c=1}^C p(c) \log q(c) H(p,q)=−c=1∑Cp(c)logq(c)
考虑上述softmax模拟的概率,在具体的操作中,我们一般把多分类的类别概率使用独热(one-hot)编码表示,这也是我们预测的概率要逼近的真实概率。以三分类为例(如下表),类别标签中只有1个类别为1,其余为零,分别表示该类型的概率。而在预测的时候,则会有一个较大的类别趋近于1,其他的都是趋近于0的。真实值的类别为2。
参考博客:[1]2019斯坦福CS224n深度学习自然语言处理笔记(3)——分类模型与神经网络)
| 类型名 | 类别1 | 类别2 | 类别3 |
|---|---|---|---|
| 真实值 p ( c ) p(c) p(c) | 0 | 1 | 0 |
| 预测值 q ( c ) q(c) q(c) | 0.05 | 0.9 | 0.05 |
也就是说,对于真实值 p ( c ) p(c) p(c) 来说,只有“类别2”才起作用,因为其余均为0。因此,平均交叉加粗样式熵损失函数可以表示为: J ( θ ) = 1 N ∑ i = 1 N − log ( e f y i ∑ c = 1 C e f c ) J (\theta) = \frac{1}{N} \sum_{i=1}^N - \log \left( \frac{e^{f_{yi}}}{\sum_{c=1}^C e^{f_c}} \right) J(θ)=N1i=1∑N−log(∑c=1Cefcefyi)
二、Derivative of Matrix
符号约定:
- 标量由小写字母表示,如 x x x
- 向量由粗体小写字母表示,如 a \boldsymbol{a} a
- 矩阵由大写加粗字母表示,如 A \boldsymbol{A} A
- 如无特殊说明,向量均表示列向量(行向量通过列向量转置来表示,如 a T \boldsymbol{a}^T aT)
- 如无特殊说明,向量的元素表示均为行向量表示,如 { x 1 , ⋯ , x n } \{x_1, \cdots, x_n\} {x1,⋯,xn}表示多个标量按水平方向排列,即行向量,相应的 { x 1 , ⋯ , x n } T \{x_1, \cdots, x_n\}^T {x1,⋯,xn}T则表示列向量
(一)矩阵的几种乘积
(1)点积(内积)
- 向量点积,也称为内积: a ⋅ b = ∑ i = 1 n a i b i \boldsymbol{a} \cdot \boldsymbol{b} = \sum_{i=1}^n a_i b_i a⋅b=i=1∑naibi
- 矩阵内积(两个矩阵对应元素乘积,并求和): A ⋅ B = ∑ i = 1 m ∑ j = 1 n a i j b i j = t r ( A T B ) \boldsymbol{A} \cdot \boldsymbol{B} = \sum_{i=1}^m \sum_{j=1}^n a_{ij} b_{ij} = tr(\boldsymbol{A}^T \boldsymbol{B}) A⋅B=i=1∑mj=1∑naijbij=tr(ATB)
(2)点乘(hadamard product,哈达码积)
矩阵点乘,也称元素积(element-wise product, point-wise product),表示两个矩阵对应元素相乘,要求两个矩阵大小完全一致。若 A m × n , B m × n \boldsymbol{A}_{m \times n},\boldsymbol{B}_{m \times n} Am×n,Bm×n,则有: A ∗ B = [ a i j b i j ] m × n \boldsymbol{A} * \boldsymbol{B} = \left[ a_{ij} b_{ij} \right]_{m \times n} A∗B=[aijbij]m×n
(3)克罗内克积(kronecker product)
也称直积、张量积。若 A m × n , B p × q \boldsymbol{A}_{m \times n},\boldsymbol{B}_{p \times q} Am×n,Bp×q,则有: A ⊗ B = [ a 11 B ⋯ a 1 n B ⋮ ⋮ a m 1 B ⋯ a m n B ] m p × n q \boldsymbol{A} \otimes \boldsymbol{B} = \left[ \begin{matrix} a_{11}\boldsymbol{B} & \cdots & a_{1n}\boldsymbol{B} \\ \vdots & & \vdots \\ a_{m1}\boldsymbol{B} & \cdots & a_{mn}\boldsymbol{B} \end{matrix} \right]_{mp \times nq} A⊗B=⎣⎢⎡a11B⋮am1B⋯⋯a1nB⋮amnB⎦⎥⎤mp×nq
(二)矩阵的运算
来源博客:矩阵求导术、矩阵微积分(一)
关于矩阵的函数: d f = ∂ f ∂ X ⋅ d X (1) \mathrm{d}f = \frac{\partial f}{\partial X}\cdot \mathrm{d}X \tag{1} df=∂X∂f⋅dX(1)
(1)微分运算
- 加(减)法 d ( A ± B ) = d A ± d B \mathrm{d}(\boldsymbol{A}\pm \boldsymbol{B})=\mathrm{d} \boldsymbol{A} \pm\mathrm{d} \boldsymbol{B} d(A±B)=dA±dB
- 乘法 d ( A B ) = ( d A ) B + A d B \mathrm{d}(\boldsymbol{A} \boldsymbol{B})=(\mathrm{d} \boldsymbol{A} )\boldsymbol{B} + \boldsymbol{A} \mathrm{d} \boldsymbol{B} d(AB)=(dA)B+AdB
- 转置 d A T = ( d A ) T \mathrm{d} \boldsymbol{A}^T=(\mathrm{d} \boldsymbol{A})^T dAT=(dA)T
- 迹(trace) d ( t r ( A ) ) = t r ( d A ) \mathrm{d} \left( tr(\boldsymbol{A})\right) = tr(\mathrm{d}\boldsymbol{A}) d(tr(A))=tr(dA)
- d A = 0 \mathrm{d} \boldsymbol{A} = \boldsymbol{0} dA=0 A \boldsymbol{A} A是常量矩阵, 0 \boldsymbol{0} 0是零矩阵
- 推论: 若 A , B \boldsymbol{A},\boldsymbol{B} A,B是常量矩阵,则: d ( A X B ) = A ( d X ) B \mathrm{d} (\boldsymbol{A}\boldsymbol{X}\boldsymbol{B}) = \boldsymbol{A}(\mathrm{d}\boldsymbol{X})\boldsymbol{B} d(AXB)=A(dX)B
- 行列式 d ∣ A ∣ = t r ( A ∗ d A ) \mathrm{d}|\boldsymbol{A}|=tr(A^*\mathrm{d} \boldsymbol{A}) d∣A∣=tr(A∗dA)其中 A ∗ \boldsymbol{A}^* A∗ 表示 A \boldsymbol{A} A 的伴随矩阵。如果 A \boldsymbol{A} A 可逆,则又有: d ∣ A ∣ = ∣ A ∣ t r ( A − 1 d A ) \mathrm{d}|\boldsymbol{A}|=|\boldsymbol{A}|tr(\boldsymbol{A}^{-1}\mathrm{d} \boldsymbol{A}) d∣A∣=∣A∣tr(A−1dA)
- Hadamard 积:逐元素乘法
定义矩阵 A \boldsymbol{A} A与 B \boldsymbol{B} B的Hadamard积为 [ A i j B i j ] n × m \left[ A_{ij}B_{ij} \right]_{n \times m} [AijBij]n×m,记作 A ⊙ B \boldsymbol{A}\odot \boldsymbol{B} A⊙B,有结论: d ( A ⊙ B ) = d A ⊙ B + A ⊙ d B \mathrm{d}(\boldsymbol{A}\odot \boldsymbol{B})=\mathrm{d} \boldsymbol{A} \odot \boldsymbol{B} + \boldsymbol{A}\odot \mathrm{d} \boldsymbol{B} d(A⊙B)=dA⊙B+A⊙dB - 逐元素标量函数 d h ( A ) = h ′ ( A ) ⊙ d A \mathrm{d}h(\boldsymbol{A})=h'(\boldsymbol{A})\odot \mathrm{d}\boldsymbol{A} dh(A)=h′(A)⊙dA其中, h ( X ) h(\boldsymbol{X}) h(X) 为对矩阵 X \boldsymbol{X} X 进行逐元素运算的标量函数
- 逆 d X − 1 = − X − 1 ( d X ) X − 1 \mathrm{d} \boldsymbol{X}^{-1} = -\boldsymbol{X}^{-1}(\mathrm{d}\boldsymbol{X})\boldsymbol{X}^{-1} dX−1=−X−1(dX)X−1
(2)点乘运算
注意:点乘是矩阵对应元素相乘,要求参加运算的两个矩阵形状相同
- 定义式 A ⋅ B = t r ( A T B ) \boldsymbol{A}\cdot \boldsymbol{B} = tr(\boldsymbol{A}^T \boldsymbol{B}) A⋅B=tr(ATB)对于向量来说,该式可以进一步简化: a ⋅ b = a T b \boldsymbol{a} \cdot \boldsymbol{b} = \boldsymbol{a}^T \boldsymbol{b} a⋅b=aTb
- 交换律 A ⋅ B = B ⋅ A \boldsymbol{A} \cdot \boldsymbol{B} = \boldsymbol{B} \cdot \boldsymbol{A} A⋅B=B⋅A
- 加法分配律 A ⋅ ( B + C ) = A ⋅ B + A ⋅ C \boldsymbol{A}\cdot( \boldsymbol{B}+\boldsymbol{C}) = \boldsymbol{A} \cdot \boldsymbol{B} + \boldsymbol{A} \cdot \boldsymbol{C} A⋅(B+C)=A⋅B+A⋅C
- 与逐元素乘法的结合律 A ⋅ ( B ⊙ C ) = ( A ⊙ B ) ⋅ C \boldsymbol{A}\cdot(\boldsymbol{B}\odot \boldsymbol{C})=(\boldsymbol{A}\odot \boldsymbol{B})\cdot \boldsymbol{C} A⋅(B⊙C)=(A⊙B)⋅C
- 转置的交换 A T ⋅ B = A ⋅ B T \boldsymbol{A}^T\cdot \boldsymbol{B} = \boldsymbol{A} \cdot \boldsymbol{B}^T AT⋅B=A⋅BT
(3)迹运算
注意:迹运算的对象必须为方阵
- 标量的迹等于其自身 t r ( x ) = x tr(x) = x tr(x)=x
- 线性 t r ( A ± B ) = t r ( A ) ± t r ( B ) tr( \boldsymbol{A}\pm \boldsymbol{B})=tr(\boldsymbol{A})\pm tr(\boldsymbol{B}) tr(A±B)=tr(A)±tr(B)
- 乘法可交换性 t r ( A B ) = t r ( B A ) tr(\boldsymbol{A}\boldsymbol{B}) = tr(\boldsymbol{B}\boldsymbol{A}) tr(AB)=tr(BA)要求 A \boldsymbol{A} A 和 B T \boldsymbol{B}^T BT 的形状相同,这样才能保证 A B \boldsymbol{A}\boldsymbol{B} AB 为方阵
- 转置迹不变 t r ( A T ) = t r ( A ) tr(\boldsymbol{A}^T)=tr(\boldsymbol{A}) tr(AT)=tr(A)
- 迹与点乘的转换 t r ( A B ) = A T ⋅ B tr(A\boldsymbol{B}) = \boldsymbol{A}^T\cdot \boldsymbol{B} tr(AB)=AT⋅B
(4)其他运算
( A T ) T = A ( A B ) T = B T A T ( A − 1 ) − 1 = A A A − 1 = A − 1 A = I ( A B ) − 1 = B − 1 A − 1 ( A T ) − 1 = ( A − 1 ) T ∣ A − 1 ∣ = ∣ A ∣ − 1 ( k A ) − 1 = k − 1 A − 1 \begin{aligned} &(\boldsymbol{A}^T)^T = \boldsymbol{A} \\ &(\boldsymbol{A}\boldsymbol{B})^T = \boldsymbol{B}^T \boldsymbol{A}^T \\ &(\boldsymbol{A}^{-1})^{-1} = \boldsymbol{A} \\ &\boldsymbol{A}\boldsymbol{A}^{-1} = \boldsymbol{A}^{-1}\boldsymbol{A} = I \\ &(\boldsymbol{A}\boldsymbol{B})^{-1} = \boldsymbol{B}^{-1}\boldsymbol{A}^{-1} \\ &(\boldsymbol{A}^T)^{-1} = (\boldsymbol{A}^{-1})^T \\ &|\boldsymbol{A}^{-1}| = |\boldsymbol{A}|^{-1} \\ &(k\boldsymbol{A})^{-1} = k^{-1}\boldsymbol{A}^{-1} \end{aligned} (AT)T=A(AB)T=BTAT(A−1)−1=AAA−1=A−1A=I(AB)−1=B−1A−1(AT)−1=(A−1)T∣A−1∣=∣A∣−1(kA)−1=k−1A−1
(三)标量对矩阵求导
参考博客:矩阵求导术
原则:标量 f f f对矩阵 X \boldsymbol{X} X 求导,遵循一个原则,即 f f f对矩阵 X \boldsymbol{X} X 的导数 d f d X \frac{\mathrm{d}f}{\mathrm{d}\boldsymbol{X}} dXdf形状与矩阵 X \boldsymbol{X} X 的形状一致。
例:设 y = a T X b \displaystyle y=\boldsymbol{a}^T \boldsymbol{X} \boldsymbol{b} y=aTXb,求 ∂ y ∂ X \displaystyle \frac{\partial y}{\partial \boldsymbol{X}} ∂X∂y。其中 a \boldsymbol{a} a 为 m × 1 m\times 1 m×1 向量, X \boldsymbol{X} X 为 m × n m\times n m×n 矩阵, b \boldsymbol{b} b 为 n × 1 n\times 1 n×1 向量, y y y 为标量。
解: d y = a T d X b = t r ( a T d X b ) = t r ( b a T d X ) = t r ( ( a b T ) T d X ) = a b T ⋅ d X \begin{aligned} \mathrm{d}y &= \boldsymbol{a}^T \mathrm{d}\boldsymbol{X} \boldsymbol{b} \\ &= tr(\boldsymbol{a}^T \mathrm{d} \boldsymbol{X} \boldsymbol{b}) \\ &= tr(\boldsymbol{b} \boldsymbol{a}^T \mathrm{d} \boldsymbol{X}) \\ &= tr((\boldsymbol{a} \boldsymbol{b}^T)^T \mathrm{d} \boldsymbol{X}) \\ &= \boldsymbol{a} \boldsymbol{b}^T \cdot \mathrm{d} \boldsymbol{X} \end{aligned} dy=aTdXb=tr(aTdXb)=tr(baTdX)=tr((abT)TdX)=abT⋅dX根据公式 ( 1 ) (1) (1) 得到: ∂ y ∂ X = a b T ∈ R m × n \frac{\partial y}{\partial \boldsymbol{X}}=\boldsymbol{a} \boldsymbol{b}^T \in \mathbb{R}^{m \times n} ∂X∂y=abT∈Rm×n与矩阵 X \boldsymbol{X} X 的形状一致。
例:线性回归的损失函数定义为 l = ∣ ∣ X w − y ∣ ∣ 2 2 \displaystyle l=||\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y}||_2^2 l=∣∣Xw−y∣∣22,求 w \boldsymbol{w} w 的最小二乘估计,即 w \boldsymbol{w} w 为何值时 l l l 可取得最小值。其中 y \boldsymbol{y} y 为 m × 1 m\times 1 m×1 列向量, X \boldsymbol{X} X 为 m × n m\times n m×n 矩阵, w \boldsymbol{w} w 为 n × 1 n\times 1 n×1 向量, l l l 为标量
解:要求极小值,只需找到 ∂ l ∂ w \displaystyle \frac{\partial l}{\partial \boldsymbol{w}} ∂w∂l 的零点。
我们的运算规则中并未定义二阶范数的微分,但根据向量范数的定义,我们可以将它表示成内积的形式: l = ( X w − y ) ⋅ ( X w − y ) = ( X w − y ) T ( X w − y ) l=(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})\cdot(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})=(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})^T(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y}) l=(Xw−y)⋅(Xw−y)=(Xw−y)T(Xw−y)
接下来,求 l l l 对 w \boldsymbol{w} w 的微分:
d l = d ( X w − y ) T ( X w − y ) + ( X w − y ) T d ( X w − y ) = ( X d w ) T ( X w − y ) + ( X w − y ) T ( X d w ) = 2 ( X w − y ) T X d w = 2 X T ( X w − y ) ⋅ d w \begin{aligned} \mathrm{d}l &= \mathrm{d}(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})^T(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y}) + (\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})^T \mathrm{d}(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y}) \\ &= (\boldsymbol{X} \mathrm{d}\boldsymbol{w})^T(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})+(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})^T(\boldsymbol{X} \mathrm{d}\boldsymbol{w}) \\ &= 2(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})^T \boldsymbol{X} \mathrm{d}\boldsymbol{w} \\ &= 2\boldsymbol{X}^T(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y})\cdot \mathrm{d}\boldsymbol{w} \end{aligned} dl=d(Xw−y)T(Xw−y)+(Xw−y)Td(Xw−y)=(Xdw)T(Xw−y)+(Xw−y)T(Xdw)=2(Xw−y)TXdw=2XT(Xw−y)⋅dw根据公式 ( 1 ) (1) (1) 可得: ∂ l ∂ w = 2 X T ( X w − y ) \frac{\partial l}{\partial \boldsymbol{w}}=2X^T(\boldsymbol{X} \boldsymbol{w}- \boldsymbol{y}) ∂w∂l=2XT(Xw−y)
令 ∂ l ∂ w = 0 \displaystyle \frac{\partial l}{\partial \boldsymbol{w}}=\boldsymbol{0} ∂w∂l=0 得(加粗的 0 \boldsymbol{0} 0 代表零向量,其形状与 w \boldsymbol{w} w 相同):
w = ( X T X ) − 1 X T y \boldsymbol{w}=(X^T X)^{-1}X^T \boldsymbol{y} w=(XTX)−1XTy
(四)矩阵对矩阵求导
这部分内容主要以cs224n官方给的矩阵求导的pdf为主,下载请戳这里
(1)Jacobian Matrix
假设函数 f : R n → R m \boldsymbol{f}: \mathbb{R}^{n} \rightarrow \mathbb{R}^{m} f:Rn→Rm 能将 n n n 维向量映射为 m m m 维: f ( x ) = [ f 1 ( x 1 , ⋯ , x n ) , f 2 ( x 1 , ⋯ , x n ) , ⋯ , f m ( x 1 , ⋯ , x n ) ] \boldsymbol{f}(\boldsymbol{x}) = \left[ f_1(x_1, \cdots, x_n),f_2(x_1, \cdots, x_n), \cdots, f_m(x_1, \cdots, x_n) \right] f(x)=[f1(x1,⋯,xn),f2(x1,⋯,xn),⋯,fm(x1,⋯,xn)]则对应的Jacobian Matrix为: ∂ f ∂ x = [ ∂ f 1 x 1 ⋯ ∂ f 1 x n ⋮ ⋱ ⋮ ∂ f m x 1 ⋯ ∂ f m x n ] m × n \frac{\partial \boldsymbol{f}}{\partial \boldsymbol{x}} =\left[ \begin{matrix} \frac{\partial f_1}{x_1} & \cdots & \frac{\partial f_1}{x_n} \\ \vdots & \ddots& \vdots \\ \frac{\partial f_m}{x_1} & \cdots & \frac{\partial f_m}{x_n}\end{matrix} \right]_{m \times n} ∂x∂f=⎣⎢⎡x1∂f1⋮x1∂fm⋯⋱⋯xn∂f1⋮xn∂fm⎦⎥⎤m×n
利用Jacobian 矩阵和链式法则,即可计算矩阵的导数,下面列举一些结论,方便以后手动计算。
(2)结论
1.矩阵乘以列向量,对列向量求导
若 W ∈ R n × m , x ∈ R m × 1 \boldsymbol{W} \in\mathbb{R}^{n \times m}, \boldsymbol{x} \in \mathbb{R}^{m \times 1} W∈Rn×m,x∈Rm×1且 z = W x \boldsymbol{z} = \boldsymbol{W}\boldsymbol{x} z=Wx,则 ∂ z ∂ x = W \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}} = \boldsymbol{W} ∂x∂z=W
证明:将 z \boldsymbol{z} z看作一个映射函数: R m → R n \mathbb{R}^{m} \rightarrow \mathbb{R}^{n} Rm→Rn (因为 x \boldsymbol{x} x由 m m m维变为 n n n维),其中 z i = ∑ k = 1 m W i k x k \boldsymbol{z}_i = \sum_{k=1}^m W_{ik} x_k zi=∑k=1mWikxk,则对应的Jacobian矩阵是 n × m n \times m n×m 维的:
∂ z ∂ x = [ z 1 x 1 ⋯ z 1 x m ⋮ ⋱ ⋮ z n x 1 ⋯ z n x m ] n × m = [ w 11 ⋯ w 1 m ⋮ ⋱ ⋮ w n 1 ⋯ w n m ] n × m = W \begin{aligned} \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}} &= \left[ \begin{matrix} \frac{z_{1}}{x_1} & \cdots &\frac{z_{1}}{x_m}\\ \vdots & \ddots & \vdots \\ \frac{z_{n}}{x_1} & \cdots & \frac{z_{n}}{x_m} \end{matrix} \right]_{n \times m}\\ &=\left[ \begin{matrix} w_{11} & \cdots & w_{1m}\\ \vdots & \ddots & \vdots \\ w_{n1} & \cdots & w_{nm} \end{matrix} \right]_{n \times m}\\ &=\boldsymbol{W} \end{aligned} ∂x∂z=⎣⎢⎡x1z1⋮x1zn⋯⋱⋯xmz1⋮xmzn⎦⎥⎤n×m=⎣⎢⎡w11⋮wn1⋯⋱⋯w1m⋮wnm⎦⎥⎤n×m=W
2.行向量乘以矩阵,对行向量求导
若 x T ∈ R 1 × m , W ∈ R m × n \boldsymbol{x}^T \in \mathbb{R}^{1 \times m} ,\boldsymbol{W} \in\mathbb{R}^{m \times n} xT∈R1×m,W∈Rm×n且 z = x W \boldsymbol{z} = \boldsymbol{x} \boldsymbol{W} z=xW,则 ∂ z ∂ x T = W T \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}^T} = \boldsymbol{W}^T ∂xT∂z=WT(证明同上,略)
3.向量对自身求导
若列向量 z = x \boldsymbol{z} = \boldsymbol{x} z=x,则 ∂ z ∂ x = I \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}} = \boldsymbol{I} ∂x∂z=I
4.向量的逐元素函数求导
若 x ∈ R m × 1 , z ∈ R m × 1 \boldsymbol{x} \in \mathbb{R}^{m \times 1},\boldsymbol{z} \in \mathbb{R}^{m \times 1} x∈Rm×1,z∈Rm×1且 z = f ( x ) \boldsymbol{z} = f (\boldsymbol{x}) z=f(x),其中 f f f 是对向量进行逐元素操作的函数,即 z i = f ( x i ) z_{i} = f(x_{i}) zi=f(xi),则 f o r m u l a formula formula
证明:将 f \boldsymbol{f} f看作一个映射函数: R m → R m \mathbb{R}^{m} \rightarrow \mathbb{R}^{m} Rm→Rm ,则对应的Jacobian矩阵是 m × m m \times m m×m 维的:
∂ z ∂ x = [ ∂ z 1 ∂ x 1 ⋯ ∂ z 1 ∂ x m ⋮ ⋱ ⋮ ∂ z m ∂ x 1 ⋯ ∂ z m ∂ x m ] m × m = [ f ′ ( x 1 ) 0 ⋯ 0 0 f ′ ( x 2 ) ⋱ ⋮ ⋮ ⋮ ⋱ 0 0 0 ⋯ f ′ ( x m ) ] m × m = d i a g ( f ′ ( x 1 ) , f ′ ( x 1 ) , ⋯ , f ′ ( x m ) ) \begin{aligned} \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}} &= \left[ \begin{matrix} \frac{\partial z_{1}}{\partial x_1} & \cdots &\frac{\partial z_{1}}{\partial x_m}\\ \vdots & \ddots & \vdots \\ \frac{\partial z_{m}}{\partial x_1} & \cdots & \frac{\partial z_{m}}{\partial x_m} \end{matrix} \right]_{m \times m}\\ &=\left[ \begin{matrix} f^{\prime}(x_1) & 0 & \cdots & 0\\ 0 & f^{\prime}(x_2) &\ddots & \vdots \\ \vdots&\vdots&\ddots&0\\ 0 &0&\cdots & f^{\prime}(x_m) \end{matrix} \right]_{m \times m}\\ &=diag \left( f^{\prime}(x_1),f^{\prime}(x_1),\cdots,f^{\prime}(x_m) \right) \end{aligned} ∂x∂z=⎣⎢⎡∂x1∂z1⋮∂x1∂zm⋯⋱⋯∂xm∂z1⋮∂xm∂zm⎦⎥⎤m×m=⎣⎢⎢⎢⎢⎡f′(x1)0⋮00f′(x2)⋮0⋯⋱⋱⋯0⋮0f′(xm)⎦⎥⎥⎥⎥⎤m×m=diag(f′(x1),f′(x1),⋯,f′(xm))
也可写成 ∂ z ∂ x = d i a g ( f ′ ( x ) ) \frac{\partial \boldsymbol{z}}{\partial \boldsymbol{x}} = diag (f^{\prime}(\boldsymbol{x})) ∂x∂z=diag(f′(x))
Since multiplication by a diagonal matrix is the same as doing elementwise multiplication by the diagonal, we could also write ∘ f ′ ( x ) \circ f^{\prime}(\boldsymbol{x}) ∘f′(x) when applying the chain rule
由于乘以一个对角阵,等同于按element-wise乘以一个对角阵,所以当应用链式法则时也写作 ∘ f ′ ( x ) \circ f^{\prime}(\boldsymbol{x}) ∘f′(x)
三、人工神经元(Artificial Neurals)

神经元是一个通用的计算单元,具有 n n n 个输入和 1 个输出,如图所示。 f f f 是非线性激活函数, x i , w i x_i, w_i xi,wi是输入和权重, b b b 是偏置。输入经加权求和偏置后,通过激活函数 f f f 的作用输出,即为神经元的输出。公式如下: h w , b ( x i ) = f ( w i x i + b i ) f ( z i ) = 1 1 + e − z i x = [ x 1 , ⋯ , x n ] w = [ w 1 , ⋯ , w n ] b = [ b 1 , ⋯ , b n ] z = [ z 1 , ⋯ , z n ] h_{\boldsymbol{w},\boldsymbol{b}}(x_i) = f(w_i x_i+b_i) \\ f (z_i) = \frac{1}{1+e^{-z_i}} \\ \boldsymbol{x}=\left[ x_1,\cdots,x_n\right] \quad \boldsymbol{w}=\left[ w_1,\cdots,w_n\right] \quad \boldsymbol{b}=\left[ b_1,\cdots,b_n\right] \quad \boldsymbol{z}=\left[ z_1,\cdots,z_n\right] hw,b(xi)=f(wixi+bi)f(zi)=1+e−zi1x=[x1,⋯,xn]w=[w1,⋯,wn]b=[b1,⋯,bn]z=[z1,⋯,zn]也可以表示向量形式: h = f ( w T x + b ) = 1 1 + exp ( − ( w T x + b ) ) h = f \left( \boldsymbol{w}^T \boldsymbol{x} + \boldsymbol{b} \right) = \frac{1}{1+\exp{\left( -\left( \boldsymbol{w}^T \boldsymbol{x} + \boldsymbol{b} \right) \right)}} h=f(wTx+b)=1+exp(−(wTx+b))1
单层的神经网络
参考博客:神经网络浅讲:从神经元到深度学习
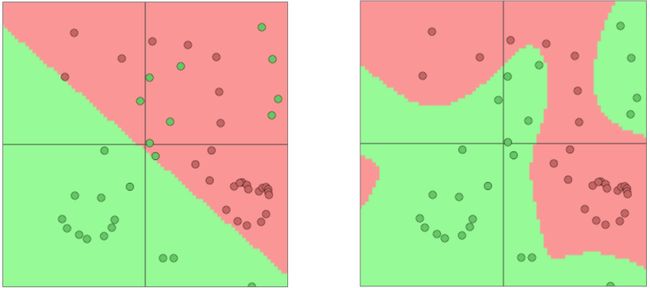
一个神经元就可以看成是一个单层的神经网络。从形式上来看,它与感知机(感知机是基础的线性二分类模型)非常像。但由于感知机通常采用阶跃激活函数,即 f ( x ) = { n / 2 , if w ⋅ x + b > 0 3 n + 1 , otherwise f(x) = \begin{cases} n/2, \quad \text{if } w \cdot x+b>0\\ 3n+1,\quad \text{otherwise} \end{cases} f(x)={n/2,if w⋅x+b>03n+1,otherwise缺乏非线性的激活函数,故只能做线性决策,下图(左)。相对于感知机,神经元采用非线性激活函数的神经元可以拟合曲线函数,下图(右)。
多层的神经网络
Without non-linearities, deep neural networks can’t do anything more than a linear transform
译:没有非线性,深度神经网络不能比线性变换做的更多
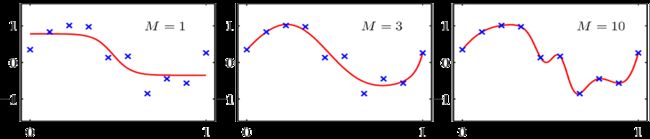
神经网络之所以能够拟合各种非线性函数,主要的功劳都归于非线性函数 f f f。神经网络每深一层都可以看作是一次线性变换,layer越多就拟合更复杂的非线性函数(如下图)。
四、神经网络(Neural Networks)
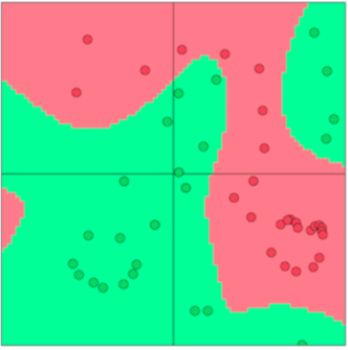
We established in our previous discussions the need for non-linear classifiers since most data are not linearly separable and thus, our classification performance on them is limited. Neural networks are
a family of classifiers with non-linear decision boundary as seen in Figure 1.
译:我们在之前的讨论中确定了非线性分类器的必要性,因为大多数数据不是线性可分的,它们的分类性能是有限的。神经网络是一类具有非线性决策边界的分类器,如图1所示。
一般来说,人们较喜欢选择“sigmoid”(也称为“二元逻辑函数”)作为神经元的激活函数。 s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1+ e^{-x}} sigmoid(x)=1+e−x1函数图像如下:
可以看出,sigmoid函数连续光滑且严格单调,以(0,0.5)中心对称,是一个非常良好的阈值函数。此外,Sigmoid函数的导数是其本身的函数,即: f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f^{\prime} (x) = f(x)\left(1-f(x)\right) f′(x)=f(x)(1−f(x)),计算非常方便,也非常节省计算时间。
因此,即可得到上述所列的神经元公式。公式如下: h w , b ( x i ) = f ( w i x i + b i ) f ( z i ) = 1 1 + e − z i x = [ x 1 , ⋯ , x n ] w = [ w 1 , ⋯ , w n ] b = [ b 1 , ⋯ , b n ] z = [ z 1 , ⋯ , z n ] h_{\boldsymbol{w},\boldsymbol{b}}(x_i) = f(w_i x_i+b_i) \\ f (z_i) = \frac{1}{1+e^{-z_i}} \\ \boldsymbol{x}=\left[ x_1,\cdots,x_n\right] \quad \boldsymbol{w}=\left[ w_1,\cdots,w_n\right] \quad \boldsymbol{b}=\left[ b_1,\cdots,b_n\right] \quad \boldsymbol{z}=\left[ z_1,\cdots,z_n\right] hw,b(xi)=f(wixi+bi)f(zi)=1+e−zi1x=[x1,⋯,xn]w=[w1,⋯,wn]b=[b1,⋯,bn]z=[z1,⋯,zn]即: h w , b ( x i ) = 1 1 + e − ( w i x i + b i ) h_{\boldsymbol{w},\boldsymbol{b}}(x_i) =\frac{1}{1+e^{-(w_i x_i+b_i)}} hw,b(xi)=1+e−(wixi+bi)1也可以表示向量形式: h = f ( w T x + b ) = 1 1 + exp ( − ( w T x + b ) ) h = f \left( \boldsymbol{w}^T \boldsymbol{x} + \boldsymbol{b} \right) = \frac{1}{1+\exp{\left( -\left( \boldsymbol{w}^T \boldsymbol{x} + \boldsymbol{b} \right) \right)}} h=f(wTx+b)=1+exp(−(wTx+b))1
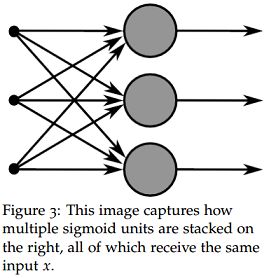
将上述神经元的思想扩展到多个神经元,考虑多个神经元共享输入 x \boldsymbol{x} x 的情况,如下图所示。
为清晰描述,下面先统一数学表示:
- x = { x 1 , ⋯ , x n } T ∈ R n × 1 \boldsymbol{x}=\{x_1, \cdots, x_n\}^T \in \mathbb{R}^{n \times 1} x={x1,⋯,xn}T∈Rn×1为输入
- w ( i ) = { w 1 , ⋯ , w n } T ∈ R m × 1 \boldsymbol{w}^{(i)}=\{w_1, \cdots, w_n\}^T \in \mathbb{R}^{m \times 1} w(i)={w1,⋯,wn}T∈Rm×1 表示第 i i i个神经元的权重向量
- W = { w ( 1 ) T , ⋯ , w ( m ) T } T ∈ R m × n \boldsymbol{W}=\{{\boldsymbol{w}^{(1)}}^T, \cdots ,{\boldsymbol{w}^{(m)}}^T\}^T \in \mathbb{R}^{m \times n} W={w(1)T,⋯,w(m)T}T∈Rm×n表示整个网络的权重矩阵
- b = { b 1 , ⋯ , b m } T ∈ R m × 1 \boldsymbol{b}=\{b_1, \cdots, b_m\}^T \in \mathbb{R}^{m \times 1} b={b1,⋯,bm}T∈Rm×1 为偏置
- z = W x + b \boldsymbol{z}=\boldsymbol{W}\boldsymbol{x}+\boldsymbol{b} z=Wx+b
- σ ( ⋅ ) \sigma ( \cdot) σ(⋅)表示激活函数
- h = σ ( z ) = σ ( W x + b ) = { h 1 , ⋯ , h m } T ∈ R m × 1 \boldsymbol{h} = \sigma (\boldsymbol{z}) = \sigma (\boldsymbol{W}\boldsymbol{x}+\boldsymbol{b}) =\{h_1, \cdots, h_m\}^T \in \mathbb{R}^{m \times 1} h=σ(z)=σ(Wx+b)={h1,⋯,hm}T∈Rm×1为神经元输出
综上即有: h i = 1 1 + exp ( w ( i ) T x + b i ) h_i = \frac{1}{1+\exp{ \left( {\boldsymbol{w}^{(i)}}^T \boldsymbol{x} + \boldsymbol{b}_i \right)}} hi=1+exp(w(i)Tx+bi)1
(一)前馈计算
从上图可以发现,图片显示的是单层多神经元的网络,它有 n n n个输出。假设有这么一个命名实体识别(NER)的task,需要在下面句子中找出中心词“Pairs”是不是命名实体:
“Museums in Paris are amazing”
notes03中说到:
it is very likely that we would not just want to capture the presence of words in the window of word vectors
but some other interactions between the words in order to make the classification
译:我们很有可能不仅想要捕获单词向量窗口中的单词,还想要捕获单词之间的其他交互,以便进行分类
我们更希望捕获词之间的信息,因此以窗口内的几个词向量的combine作为输入。此外,我们不希望网络的输出有 n n n个,而是类似得分的一个输出,直接得出“Pairs”是不是命名实体的结果。这时就需对上图网络进行修改,如下图:
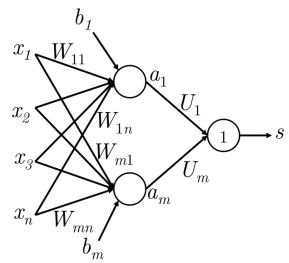
Dimensions for a single hidden layer neural network: If we represent each word using a 4-dimensional word vector and we use a 5-word window as input, then the input x ∈ R 20 \boldsymbol{x} \in \mathbb{R}^{20} x∈R20. If we use 8 sigmoid units in the hidden layer and generate 1 score output from the activations, then W ∈ R 8 × 20 , b ∈ R 8 , u ∈ R 8 × 1 , s ∈ R \boldsymbol{W} \in \mathbb{R}^{8 \times 20}, \boldsymbol{b} \in \mathbb{R}^8, \boldsymbol{u} \in \mathbb{R}^{8 \times 1}, s \in \mathbb{R} W∈R8×20,b∈R8,u∈R8×1,s∈R. The stage-wise feed-forward computation is then: z = W x + b h = σ ( z ) s = u T h \boldsymbol{z} = \boldsymbol{W}\boldsymbol{x}+\boldsymbol{b}\\ \boldsymbol{h} = \sigma (\boldsymbol{z})\\ s = \boldsymbol{u}^T\boldsymbol{h} z=Wx+bh=σ(z)s=uTh
译:只有一个隐含层的神经网络的维度:如果我们使用4维的词向量表示word,且滑动窗口大小为5,那么输入向量为 x ∈ R 20 \boldsymbol{x} \in \mathbb{R}^{20} x∈R20。如果在隐含层中使用8个sigmoid函数,并从激活中生成一个分数输出,那么 W ∈ R 8 × 20 , b ∈ R 8 , u ∈ R 8 × 1 , s ∈ R \boldsymbol{W} \in \mathbb{R}^{8 \times 20}, \boldsymbol{b} \in \mathbb{R}^8, \boldsymbol{u} \in \mathbb{R}^{8 \times 1}, s \in \mathbb{R} W∈R8×20,b∈R8,u∈R8×1,s∈R,前馈计算公式为:
z = W x + b h = σ ( z ) s = u T h \boldsymbol{z} = \boldsymbol{W}\boldsymbol{x}+\boldsymbol{b}\\ \boldsymbol{h} = \sigma (\boldsymbol{z})\\ s = \boldsymbol{u}^T\boldsymbol{h} z=Wx+bh=σ(z)s=uTh
如上所述,修改就是多加一层神经元,新增的权重向量为 u ∈ R m × 1 \boldsymbol{u} \in \mathbb{R}^{m \times 1} u∈Rm×1
(二)最大间隔目标函数(Maximum margin objection function)
在上述NER任务中,我们目标是:
ensure that the score computed for “true” labeled data points is higher than the score computed for
“false” labeled data points.
确保正确标签数据点的分数要大于错误标签数据点的分数
换句话说,就是正样本的分数要高于负样本的分数。于是,假设有两个样本,一个是正样本,一个是负样本。
- Museums in Paris are amazing(正样本)
- Not all museums in Paris(负样本)
正样本的center word是 “Paris”,是命名实体;负样本的center word是 “museums”,不是命名实体。假设正样本和负样本的分数分别为 s , s c s,s_c s,sc,那么训练神经网络的目标就是(具体推导详见note03): min J = max ( 1 + s c − s , 0 ) \min J = \max(1+s_c-s,0) minJ=max(1+sc−s,0)
其中, s = u T σ ( W x + b ) , s c = u T σ ( W x c + b ) s = \boldsymbol{u}^T \sigma \left( \boldsymbol{W}\boldsymbol{x}+\boldsymbol{b} \right) \quad , \quad s_c = \boldsymbol{u}^T \sigma \left( \boldsymbol{W}\boldsymbol{x}_c+\boldsymbol{b} \right) s=uTσ(Wx+b),sc=uTσ(Wxc+b)
(三)反向传播
训练过程就是最小化目标函数的过程,具体怎么最小化呢?用梯度下降法(或者梯度下降的变种算法)!
在神经网络的训练中,利用反向传播算法将目标函数的梯度在网络中反向传播,权重根据梯度调整值,并重复迭代。迭代的具体公式如下: θ ( t + 1 ) = θ ( t ) − α ∇ θ ( t ) J \theta^{(t+1)}=\theta^{(t)}-\alpha \nabla_{\theta^{(t)}}J θ(t+1)=θ(t)−α∇θ(t)J
下面,举个例子说明反向传播的工作流程。下图显示的是一个“4-2-1”的神经网络。做以下表示说明:
- x = { x 1 , ⋯ , x 4 } T ∈ R 4 × 1 \boldsymbol{x}=\{x_1, \cdots, x_4\}^T \in \mathbb{R}^{4 \times 1} x={x1,⋯,x4}T∈R4×1为网络的输入
- s s s 为网络的输出
- z j ( k ) \boldsymbol{z}_j^{(k)} zj(k) 表示第 k k k层的第 j j j个神经元的输入(标量)
- z ( k ) \boldsymbol{z}^{(k)} z(k) 表示第 k k k层的输入
- h j ( k ) = σ ( z j ( k ) ) \boldsymbol{h}_j^{(k)} = \sigma(\boldsymbol{z}_j^{(k)}) hj(k)=σ(zj(k)) 表示第 k k k层的第 j j j个神经元的输出(标量)
- h ( k ) = σ ( z ( k ) ) \boldsymbol{h}^{(k)} = \sigma(\boldsymbol{z}^{(k)}) h(k)=σ(z(k)) 表示第 k k k层的输出
- δ j ( k ) \delta_j^{(k)} δj(k) 表示来自 z j ( k ) \boldsymbol{z}_j^{(k)} zj(k)的反向传播误差
- W ( k ) \boldsymbol{W}^{(k)} W(k)表示第 k k k层到第 k + 1 k+1 k+1层的权重矩阵
- W i j ( k ) \boldsymbol{W}_{ij}^{(k)} Wij(k)表示第 k k k 层的第 j j j 个神经元到第 k + 1 k+1 k+1 层的第 i i i 个神经元的权重(是一个标量,见“前馈传播示意图”)
于是,在这个“4-2-1”的神经网络中,有下列式子成立:
s = h 1 ( 3 ) = W ( 2 ) h ( 2 ) = U h ( 2 ) h ( 1 ) = z ( 1 ) = x (第一层是输入层,不是隐藏层,无激活函数) W ( 1 ) = W W ( 2 ) = U z ( k ) = W ( k − 1 ) h ( k − 1 ) \begin{aligned} s = \boldsymbol{h}_1^{(3)} &= \boldsymbol{W}^{(2)}\boldsymbol{h}^{(2)} = \boldsymbol{U}\boldsymbol{h}^{(2)}\\ \quad \boldsymbol{h}^{(1)} &= \boldsymbol{z}^{(1)} = \boldsymbol{x} \text{(第一层是输入层,不是隐藏层,无激活函数)}\\ \boldsymbol{W}^{(1)} &= \boldsymbol{W} \\ \boldsymbol{W}^{(2)} &= \boldsymbol{U} \\ \boldsymbol{z}^{(k)} &= {\boldsymbol{W}^{(k-1)}} \boldsymbol{h}^{(k-1)} \end{aligned} s=h1(3)h(1)W(1)W(2)z(k)=W(2)h(2)=Uh(2)=z(1)=x(第一层是输入层,不是隐藏层,无激活函数)=W=U=W(k−1)h(k−1)
各参数的维度为:
s x i z i ( k ) h i ( k ) W i j ( k ) ∈ R x , z ( 1 ) , z ( 2 ) , h ( 1 ) ∈ R 4 × 1 h ( 2 ) ∈ R 2 × 1 W ( 1 ) ∈ R 2 × 4 W ( 2 ) = U ∈ R 1 × 2 \begin{aligned} s \quad x_i \quad \boldsymbol{z}_i^{(k)} \quad \boldsymbol{h}_i^{(k)} \quad \boldsymbol{W}_{ij}^{(k)} &\in \mathbb{R}\\ \boldsymbol{x},\boldsymbol{z}^{(1)},\boldsymbol{z}^{(2)},\boldsymbol{h}^{(1)} &\in \mathbb{R}^{4 \times 1} \\ \boldsymbol{h}^{(2)} &\in \mathbb{R}^{2 \times 1} \\ \boldsymbol{W}^{(1)} &\in \mathbb{R}^{2 \times 4} \\ \boldsymbol{W}^{(2)} = \boldsymbol{U} &\in \mathbb{R}^{1 \times 2} \end{aligned} sxizi(k)hi(k)Wij(k)x,z(1),z(2),h(1)h(2)W(1)W(2)=U∈R∈R4×1∈R2×1∈R2×4∈R1×2
注意一点,图中第 k k k层的权重 W i j ( k ) \boldsymbol{W}_{ij}^{(k)} Wij(k) 在第 k + 1 k+1 k+1层中只对 z i ( k + 1 ) \boldsymbol{z}_{i}^{(k+1)} zi(k+1) 有贡献,从而得到 h i ( k + 1 ) \boldsymbol{h}_{i}^{(k+1)} hi(k+1),这对接下来的推导很重要。
1、目标函数对权重的梯度计算
我们计算目标函数对权重 W i j ( 1 ) \boldsymbol{W}_{ij}^{(1)} Wij(1) 的梯度:
∂ s ∂ W i j ( 1 ) = ∂ W ( 2 ) h ( 2 ) ∂ W i j ( 1 ) ← s = W ( 2 ) h ( 2 ) = ∂ W i ( 2 ) h i ( 2 ) ∂ W i j ( 1 ) ← W i ( 2 ) , h i ( 2 ) 都是向量,只有第 i 个元素起作用 = W i ( 2 ) ⋅ ∂ h i ( 2 ) ∂ W i j ( 1 ) = W i ( 2 ) ⋅ ∂ h i ( 2 ) ∂ z i ( 2 ) ⋅ ∂ z i ( 2 ) W i j ( 1 ) = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) ⋅ ∂ z i ( 2 ) W i j ( 1 ) ← h i ( 2 ) 是 z i ( 2 ) 的 函 数 = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) ⋅ ∂ W i j ( 1 ) ( b i ( 1 ) + ∑ k = 1 4 W i k ( 1 ) h k ( 1 ) ) = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) ⋅ ∂ W i j ( 1 ) ( ∑ k = 1 4 W i k ( 1 ) h k ( 1 ) ) = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) ⋅ h j ( 1 ) ← i = j 时 才 有 非 零 值 = δ i ( 2 ) ⋅ h j ( 1 ) ← 令 δ i ( 2 ) = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) \begin{aligned} \frac{\partial s}{\partial \boldsymbol{W}_{ij}^{(1)}} &=\frac{\partial \boldsymbol{W}^{(2)} \boldsymbol{h}^{(2)}}{\partial \boldsymbol{W}_{ij}^{(1)}} \quad \leftarrow \quad s = \boldsymbol{W}^{(2)}\boldsymbol{h}^{(2)} \\ &= \frac{\partial \boldsymbol{W}_i^{(2)} \boldsymbol{h}_i^{(2)}}{\partial \boldsymbol{W}_{ij}^{(1)}} \quad \leftarrow \boldsymbol{W}_i^{(2)}, \boldsymbol{h}_i^{(2)}\text{都是向量,只有第 $i$ 个元素起作用}\\ &= \boldsymbol{W}_i^{(2)} \cdot \frac{\partial \boldsymbol{h}_i^{(2)}}{\partial \boldsymbol{W}_{ij}^{(1)}}\\ &= \boldsymbol{W}_i^{(2)} \cdot \frac{\partial \boldsymbol{h}_i^{(2)}}{\partial \boldsymbol{z}_i^{(2)}} \cdot \frac{\partial \boldsymbol{z}_i^{(2)}}{\boldsymbol{W}_{ij}^{(1)}}\\ &= \boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) \cdot \frac{\partial \boldsymbol{z}_i^{(2)}}{\boldsymbol{W}_{ij}^{(1)}} \quad \leftarrow \quad \boldsymbol{h}_i^{(2)}是\boldsymbol{z}_i^{(2)}的函数\\ &= \boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) \cdot \frac{\partial }{\boldsymbol{W}_{ij}^{(1)}} \left( \boldsymbol{b}_i^{(1)} + \sum_{k=1}^{4} \boldsymbol{W}_{ik}^{(1)} \boldsymbol{h}_k^{(1)} \right) \\ &= \boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) \cdot \frac{\partial }{\boldsymbol{W}_{ij}^{(1)}} \left( \sum_{k=1}^{4} \boldsymbol{W}_{ik}^{(1)} \boldsymbol{h}_k^{(1)} \right)\\ &= \boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) \cdot \boldsymbol{h}_j^{(1)} \quad \leftarrow \quad i=j时才有非零值 \\ &= \delta_i^{(2)} \cdot \boldsymbol{h}_j^{(1)} \quad \leftarrow \quad 令\delta_i^{(2)}=\boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) \end{aligned} ∂Wij(1)∂s=∂Wij(1)∂W(2)h(2)←s=W(2)h(2)=∂Wij(1)∂Wi(2)hi(2)←Wi(2),hi(2)都是向量,只有第 i 个元素起作用=Wi(2)⋅∂Wij(1)∂hi(2)=Wi(2)⋅∂zi(2)∂hi(2)⋅Wij(1)∂zi(2)=Wi(2)⋅f′(zi(2))⋅Wij(1)∂zi(2)←hi(2)是zi(2)的函数=Wi(2)⋅f′(zi(2))⋅Wij(1)∂(bi(1)+k=1∑4Wik(1)hk(1))=Wi(2)⋅f′(zi(2))⋅Wij(1)∂(k=1∑4Wik(1)hk(1))=Wi(2)⋅f′(zi(2))⋅hj(1)←i=j时才有非零值=δi(2)⋅hj(1)←令δi(2)=Wi(2)⋅f′(zi(2))
最终发现,目标函数对权重 W i j ( 1 ) \boldsymbol{W}_{ij}^{(1)} Wij(1) 的梯度就是 δ i ( 2 ) h j ( 1 ) \delta_i^{(2)} \boldsymbol{h}_j^{(1)} δi(2)hj(1)。而 δ i ( 2 ) \delta_i^{(2)} δi(2)则是来自第 2 2 2 层第 i i i 个神经元的反向传播误差。
代入具体数字看看,如果 i = 1 , j = 4 i=1,j=4 i=1,j=4,则 W 14 ( 1 ) = δ 1 ( 2 ) h 4 ( 1 ) \boldsymbol{W}_{14}^{(1)} = \delta_1^{(2)} \boldsymbol{h}_4^{(1)} W14(1)=δ1(2)h4(1),目标函数对权重 W 14 ( 1 ) \boldsymbol{W}_{14}^{(1)} W14(1) 的梯度是来自同层同神经元的输出 h 4 ( 1 ) \boldsymbol{h}_4^{(1)} h4(1)与来自更深一层神经元(该神经元正是图中权重所指向的那个神经元)的反向传播误差 δ 1 ( 2 ) \delta_1^{(2)} δ1(2)的乘积。

花了这么大的功夫来计算目标函数对权重的梯度,是有原因的。为了达到最大化间隔的目标,用的方法就是梯度下降,通过多次迭代找到间隔最大的那个函数的点。那么,为什么要计算梯度呢?因为目标函数的梯度所指的方向就是这个函数值下降最快的方向。所以我们让权重按这这个方向步进,迭代更新自己的值。
又有问题来了,问什么是对权重的梯度?而不是对输入 x \boldsymbol{x} x的梯度呢?因为我们要训练的网络是根据输入得到一个输出,这个输出可以告诉我们哪个词是命名实体(是Pairs,还是museums)。训练网络的本质,就是训练网络中各层的权重,权重确定了,网络也就确定了。
2、 δ ( k ) \boldsymbol{\delta}^{(k)} δ(k) 的解释
这里需要注意:官方note3文档中并没有解释什么是 δ ( k ) \boldsymbol{\delta}^{(k)} δ(k),连公式推导中都只是一带而过,没有很清晰的解释。当然,网上随处都是 δ ( k ) \boldsymbol{\delta}^{(k)} δ(k)的解释,为了方便阅读,这里顺带提一下。首先计算目标函数对权重和偏置的梯度:
∂ s ∂ W i j ( k ) = ∂ s ∂ z i ( k ) ⋅ ∂ z i ( k ) ∂ W i j ( k ) = δ i ( k ) ⋅ ∂ z i ( k ) ∂ W i j ( k ) ∂ s ∂ b i ( k ) = ∂ s ∂ z i ( k ) ⋅ ∂ z i ( k ) ∂ b i ( k ) = δ i ( k ) ⋅ ∂ z i ( k ) ∂ b i ( k ) \begin{aligned} \frac{\partial s}{\partial \boldsymbol{W}_{ij}^{(k)}} &= \frac{\partial s}{\partial \boldsymbol{z}_i^{(k)}} \cdot \frac{\partial \boldsymbol{z}_i^{(k)}}{\partial \boldsymbol{W}_{ij}^{(k)}} = \delta_i^{(k)} \cdot \frac{\partial \boldsymbol{z}_i^{(k)}}{\partial \boldsymbol{W}_{ij}^{(k)}}\\ \frac{\partial s}{\partial \boldsymbol{b}_{i}^{(k)}} &= \frac{\partial s}{\partial \boldsymbol{z}_i^{(k)}} \cdot \frac{\partial \boldsymbol{z}_i^{(k)}}{\partial \boldsymbol{b}_{i}^{(k)}} = \delta_i^{(k)} \cdot \frac{\partial \boldsymbol{z}_i^{(k)}}{\partial \boldsymbol{b}_{i}^{(k)}} \end{aligned} ∂Wij(k)∂s∂bi(k)∂s=∂zi(k)∂s⋅∂Wij(k)∂zi(k)=δi(k)⋅∂Wij(k)∂zi(k)=∂zi(k)∂s⋅∂bi(k)∂zi(k)=δi(k)⋅∂bi(k)∂zi(k)
由于 ∂ s ∂ z i ( k ) \frac{\partial s}{\partial \boldsymbol{z}_i^{(k)}} ∂zi(k)∂s 是两者都需要计算的相同部分,因此就把它叫做 δ i ( k ) \delta_i^{(k)} δi(k)。
再来看,上面推导的一长串公式对 δ i ( k ) \delta_i^{(k)} δi(k) 的描述: δ i ( 2 ) = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) \delta_i^{(2)}=\boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) δi(2)=Wi(2)⋅f′(zi(2)),这两者一样吗?
当然一样,不信请看: δ i ( 2 ) = ∂ s ∂ z i ( 2 ) = ∂ s ∂ h j ( 2 ) ⋅ ∂ h j ( 2 ) ∂ z i ( 2 ) = ∂ ( W i ( 2 ) h i ( 2 ) ) ∂ h j ( 2 ) ⋅ ∂ h j ( 2 ) ∂ z i ( 2 ) = W i ( 2 ) ⋅ ∂ h j ( 2 ) ∂ z i ( 2 ) = W i ( 2 ) ⋅ f ′ ( z i ( 2 ) ) \begin{aligned} \delta_i^{(2)} &= \frac{\partial s}{\partial \boldsymbol{z}_i^{(2)}} \\ &= \frac{\partial s}{\partial \boldsymbol{h}_j^{(2)}} \cdot \frac{\partial \boldsymbol{h}_j^{(2)}}{\partial \boldsymbol{z}_i^{(2)}} \\ &= \frac{\partial \left( \boldsymbol{W}_i^{(2)} \boldsymbol{h}_i^{(2)} \right)}{\partial \boldsymbol{h}_j^{(2)}} \cdot \frac{\partial \boldsymbol{h}_j^{(2)}}{\partial \boldsymbol{z}_i^{(2)}} \\ &= \boldsymbol{W}_i^{(2)} \cdot \frac{\partial \boldsymbol{h}_j^{(2)}}{\partial \boldsymbol{z}_i^{(2)}} \\ &= \boldsymbol{W}_i^{(2)} \cdot f^{\prime}\left( \boldsymbol{z}_i^{(2)} \right) \end{aligned} δi(2)=∂zi(2)∂s=∂hj(2)∂s⋅∂zi(2)∂hj(2)=∂hj(2)∂(Wi(2)hi(2))⋅∂zi(2)∂hj(2)=Wi(2)⋅∂zi(2)∂hj(2)=Wi(2)⋅f′(zi(2))
这就对上号了。
3、权重梯度的反向传播
刚刚解释的是目标函数对权重的梯度长什么样,由哪些部分组成。那么,知道其组成之后,权重的梯度又是如何反向传播的呢?
这里单单把第2层的第1个神经元(用 n e u r a l 1 ( 2 ) neural_1^{(2)} neural1(2) 表示)拎出来,举例说明,如下图。
- 首先假设我们有个误差信号(error signal)从 h 1 ( 3 ) \boldsymbol{h}_1^{(3)} h1(3) 处开始反向传播,这个误差信号值为 ∂ s ∂ h 1 ( 3 ) = 1 \frac{\partial s}{\partial \boldsymbol{h}_1^{(3)}} = 1 ∂h1(3)∂s=1
- 要穿过网络第3层神经元,需乘以该神经元的局部梯度(Local Gradient),即输出对输入的梯度: ∂ h 1 ( 3 ) ∂ z 1 ( 3 ) = 1 \frac{\partial \boldsymbol{h}_1^{(3)}}{\partial \boldsymbol{z}_1^{(3)}} = 1 ∂z1(3)∂h1(3)=1所以来自第3层的误差信号值为 δ 1 ( 3 ) = 1 \delta_1^{(3)} = 1 δ1(3)=1
- 误差信号继续往回传播。此时有两个回去的方向,一是 W 1 ( 2 ) \boldsymbol{W}_1^{(2)} W1(2) ,二是 W 2 ( 2 ) \boldsymbol{W}_2^{(2)} W2(2),我们考虑 n e u r a l 1 ( 2 ) neural_1^{(2)} neural1(2),因此选择 W 1 ( 2 ) \boldsymbol{W}_1^{(2)} W1(2) 方向的路线,误差信号传播到 h 1 ( 3 ) \boldsymbol{h}_1^{(3)} h1(3) 处需乘以该路线上的权重 W 1 ( 2 ) \boldsymbol{W}_1^{(2)} W1(2) ,因此在 h 1 ( 3 ) \boldsymbol{h}_1^{(3)} h1(3) 处的误差信号为 W 1 ( 2 ) δ 1 ( 3 ) = W 1 ( 2 ) \boldsymbol{W}_1^{(2)} \delta_1^{(3)} = \boldsymbol{W}_1^{(2)} W1(2)δ1(3)=W1(2)
- 与第2步相同,在误差信号穿过 n e u r a l 1 ( 2 ) neural_1^{(2)} neural1(2) 时,需乘以该神经元的局部梯度 ∂ h 1 ( 2 ) ∂ z 1 ( 2 ) = f ′ ( z 1 ( 2 ) ) \frac{\partial \boldsymbol{h}_1^{(2)}}{\partial \boldsymbol{z}_1^{(2)}} = f^{\prime} \left( \boldsymbol{z}_1^{(2)} \right) ∂z1(2)∂h1(2)=f′(z1(2))因此第二层的误差信号为 δ 1 ( 2 ) = f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) \delta_1^{(2)} = f^{\prime} \left( \boldsymbol{z}_1^{(2)} \right) \boldsymbol{W}_1^{(2)} δ1(2)=f′(z1(2))W1(2)
- 误差信号再往回传播,若选择 W 14 ( 1 ) \boldsymbol{W}_{14}^{(1)} W14(1) 方向,那么误差信号到达 h 4 ( 1 ) \boldsymbol{h}_{4}^{(1)} h4(1)时,其值为 δ 1 ( 1 ) = W 14 ( 1 ) f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) \delta_1^{(1)} = \boldsymbol{W}_{14}^{(1)} f^{\prime} \left( \boldsymbol{z}_1^{(2)} \right) \boldsymbol{W}_1^{(2)} δ1(1)=W14(1)f′(z1(2))W1(2)
综上,可归纳为:
δ 1 ( 3 ) = 1 δ 1 ( 2 ) = f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) δ 1 ( 3 ) = f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) δ 1 ( 1 ) = W 14 ( 1 ) δ 1 ( 2 ) = W 14 ( 1 ) f ′ ( z 1 ( 2 ) ) W 1 ( 2 ) \begin{aligned} \delta_1^{(3)} &= 1 \\ \delta_1^{(2)} &= f^{\prime} \left( \boldsymbol{z}_1^{(2)} \right) \boldsymbol{W}_1^{(2)} \delta_1^{(3)} = f^{\prime} \left( \boldsymbol{z}_1^{(2)} \right) \boldsymbol{W}_1^{(2)} \\ \delta_1^{(1)} &= \boldsymbol{W}_{14}^{(1)} \delta_1^{(2)} = \boldsymbol{W}_{14}^{(1)} f^{\prime} \left( \boldsymbol{z}_1^{(2)} \right) \boldsymbol{W}_1^{(2)} \end{aligned} δ1(3)δ1(2)δ1(1)=1=f′(z1(2))W1(2)δ1(3)=f′(z1(2))W1(2)=W14(1)δ1(2)=W14(1)f′(z1(2))W1(2)

4、 δ ( k + 1 ) \boldsymbol{\delta}^{(k+1)} δ(k+1) 到 δ ( k ) \boldsymbol{\delta}^{(k)} δ(k)的传播
网络中的参数除了权重之外,偏置也是极其重要的部分,偏置的反向传播与权重类似,如下图。

- 误差信号 δ i ( k ) \delta_i^{(k)} δi(k) 从 z i ( k ) \boldsymbol{z}_i^{(k)} zi(k) 开始反向传播,到达 h i ( k − 1 ) \boldsymbol{h}_i^{(k-1)} hi(k−1) 时,误差信号变为: δ i ( k ) W i j ( k − 1 ) \delta_i^{(k)} \boldsymbol{W}_{ij}^{(k-1)} δi(k)Wij(k−1)
- 此时,考虑 n e u r a l j ( k − 1 ) neural_j^{(k-1)} neuralj(k−1) 的输出流向多个下一层神经元,因此反向传播时就有多个误差信息同时流入该神经元,总的误差信号表示为 ∑ i δ i ( k ) W i j ( k − 1 ) \sum_i \delta_i^{(k)} \boldsymbol{W}_{ij}^{(k-1)} i∑δi(k)Wij(k−1)
- 在穿过 n e u r a l j ( k − 1 ) neural_j^{(k-1)} neuralj(k−1) 后,误差信号要乘以该神经元的局部梯度,即有: δ j ( k − 1 ) = f ′ ( z j k − 1 ) ∑ i δ i ( k ) W i j ( k − 1 ) (1) \delta_j^{(k-1)} = f^{\prime} \left( \boldsymbol{z}_j^{k-1} \right) \sum_i \delta_i^{(k)} \boldsymbol{W}_{ij}^{(k-1)} \tag{1} δj(k−1)=f′(zjk−1)i∑δi(k)Wij(k−1)(1)
根据公式(1),可得到如下矩阵形式:
∇ W ( k ) = [ δ 1 ( k + 1 ) h 1 ( k ) δ 1 ( k + 1 ) h 2 ( k ) ⋯ δ 2 ( k + 1 ) h 1 ( k ) δ 2 ( k + 1 ) h 2 ( k ) ⋯ ⋮ ⋮ ⋱ ] = δ ( k + 1 ) ( h ( k ) ) T δ ( k ) = f ′ ( z k ) ∘ ( ( W ( k ) ) T δ ( k + 1 ) ) \begin{aligned} \nabla_{\boldsymbol{W}^{(k)}} &= \left[ \begin{matrix} &\delta_1^{(k+1)}\boldsymbol{h}_1^{(k)} \quad &\delta_1^{(k+1)} \boldsymbol{h}_2^{(k)} \quad &\cdots\\ &\delta_2^{(k+1)}\boldsymbol{h}_1^{(k)} \quad &\delta_2^{(k+1)} \boldsymbol{h}_2^{(k)} \quad &\cdots\\ &\vdots \quad &\vdots \quad &\ddots \end{matrix} \right] = \boldsymbol{\delta}^{(k+1)} \left( \boldsymbol{h}^{(k)} \right)^T \\ \\ \boldsymbol{\delta}^{(k)} &= f^{\prime} \left( \boldsymbol{z}^{k} \right) \circ \left( \left( \boldsymbol{W}^{(k)} \right)^T \boldsymbol{\delta}^{(k+1)} \right) \end{aligned} ∇W(k)δ(k)=⎣⎢⎢⎡δ1(k+1)h1(k)δ2(k+1)h1(k)⋮δ1(k+1)h2(k)δ2(k+1)h2(k)⋮⋯⋯⋱⎦⎥⎥⎤=δ(k+1)(h(k))T=f′(zk)∘((W(k))Tδ(k+1))
5、偏置梯度
对于某个神经元来说,其输出对偏置的导数均为1,则可快速得到: ∂ s ∂ b i ( k ) = δ i ( k ) \frac{\partial s}{\partial \boldsymbol{b}_i^{(k)}} = \delta_i^{(k)} ∂bi(k)∂s=δi(k)
五、Some Tips
详见官方note,这里不赘述。
Reference
1、2019斯坦福CS224n深度学习自然语言处理笔记(3)——分类模型与神经网络