Redis原理分析(二)
我们知道,整个Redis的数据结构是key-value形式组成的一个全局字典,还有带过期时间key集合也是一个字典。
struct RedisDb{
dict* dict; //所有key-value
dict* expires //所有key的过期时间
...
}
struct zset{
dict* dict //所有的value-score
zskiplist *zsl //跳表
}一、字典内部结构
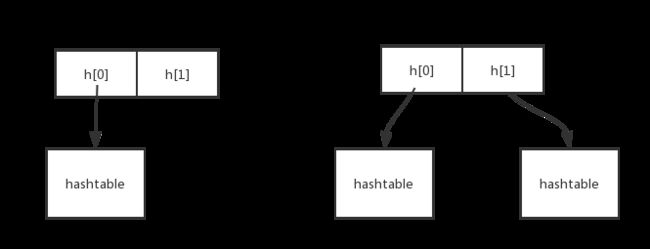
在字典的内部结构中包含两个hashtable,但是只有一个hashtable是存储数据的(我们假设为h[0],另一个hashtable(我们假设h[1])的作用是:当字典需要进行扩容或者缩容的时候,需要分配出新的hashtable,然后进行渐进式的搬迁,这个h[0]存储的是旧的数据,h[1]存储的是新的数据,当数据完全迁移到h[1]的时候,h[0]里面的hashtable将会被删除,而被被h[1]取代。
Redis里面hashtable的结构和Java中HashMap的结构以及原理几乎是一样的,都是通过粪桶的方式解决了hash冲突。在结构中一共有两个维度,第一个是数组,在每一个数组元素中又存了一个链表结构。
当插入一个元素的时候,先获取元素的散列值,根据散列值找到结构数组中对应的位置。如果该位置中没有元素,则把插入的新值填充到相应的数组位置。若有元素(元素为一个链表节点),则以哈希值和内容来比较两个元素是否相等,如果不相等取元素的下一个节点,直到取到最后一个节点加入到元素的尾部中。
二、渐进式rehash详解
大字典扩容redis一般采用渐进式rehash操作。
首先我们要先知道两个问题。第一个就是什么叫渐进式,第二个就是为什么需要渐进式。
在我的理解下,渐进式rehash就是把一次rehash操作分成很多步进行操作,这样可以把一次性的耗时分散到其他操作的耗时上,这属于一个分治的思想。如果不采用渐进式rehash,那么一次大字典的扩容操作是需要花费很多时间的,这对于单线程的redis是很难承受这样的过程。所以干脆把一次性的耗时分散到多次、渐进式的完成。虽然这样扩容会慢一些,但是总可以完成扩容操作。
渐进式rehash大致分为四个步骤:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在字典中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
渐进式的过程如下图所示:
dictht0:head [label = "ht[0]"]; dict:ht -> dictht1:head [label = "ht[1]"]; dictht0:table -> table0:head; dictht1:table -> table1:head; table0:0 -> kv2:head -> null0; table0:1 -> kv0:head -> null1; table0:2 -> kv3:head -> null2; table0:3 -> kv1:head -> null3; table1:0 -> null10; table1:1 -> null11; table1:2 -> null12; table1:7 -> null17; }" class="has" src="http://img.e-com-net.com/image/info8/65c6a2e068d545749bdd6d5353d61f2b.jpg" width="0" height="0">
dictht0:head [label = "ht[0]"]; dict:ht -> dictht1:head [label = "ht[1]"]; dictht0:table -> table0:head; dictht1:table -> table1:head; table0:0 -> null0; table0:1 -> kv0:head -> null1; table0:2 -> kv3:head -> null2; table0:3 -> kv1:head -> null3; table1:4 -> kv2:head -> null14 }" class="has" src="http://img.e-com-net.com/image/info8/3f9d6e65caf44c95959b217b5587aaff.jpg" width="0" height="0">
dictht0:head [label = "ht[0]"]; dict:ht -> dictht1:head [label = "ht[1]"]; dictht0:table -> table0:head; dictht1:table -> table1:head; table0:0 -> null0; table0:1 -> null1; table0:2 -> kv3:head -> null2; table0:3 -> kv1:head -> null3; table1:4 -> kv2:head -> null14 table1:5 -> kv0:head -> null15; }" class="has" src="http://img.e-com-net.com/image/info8/2bf31e323ad34fbd8111a4386e35f590.jpg" width="0" height="0">
dictht0:head [label = "ht[0]"]; dict:ht -> dictht1:head [label = "ht[1]"]; dictht0:table -> table0:head; dictht1:table -> table1:head; table0:0 -> null0; table0:1 -> null1; table0:2 -> null2; table0:3 -> kv1:head -> null3; table1:1 -> kv3:head -> null11; table1:4 -> kv2:head -> null14 table1:5 -> kv0:head -> null15; }" class="has" src="http://img.e-com-net.com/image/info8/35097ec231cc466ab6a9b713652e9cc3.jpg" width="0" height="0">
dictht0:head [label = "ht[0]"]; dict:ht -> dictht1:head [label = "ht[1]"]; dictht0:table -> table0:head; dictht1:table -> table1:head; table0:0 -> null0; table0:1 -> null1; table0:2 -> null2; table0:3 -> null3; table1:1 -> kv3:head -> null11; table1:4 -> kv2:head -> null14 table1:5 -> kv0:head -> null15; table1:7 -> kv1:head -> null17; }" class="has" src="http://img.e-com-net.com/image/info8/329ba5b0f63347fd91252a0d1bef7cf0.jpg" width="0" height="0">
dictht0:head [label = "ht[0]"]; dict:ht -> dictht1:head [label = "ht[1]"]; dictht0:table -> table0:head; dictht1:table -> table1; table0:1 -> kv3:head -> null11; table0:4 -> kv2:head -> null14; table0:5 -> kv0:head -> null15; table0:7 -> kv1:head -> null17; }" class="has" src="http://img.e-com-net.com/image/info8/de107f39f8904feb94b0a20c6f3aaefa.jpg" width="0" height="0">
渐进是把hash操作分散到对字典的增加、删除、修改等操作上的。那么如果对于一个正在发生rehash操作的字典,我需要查找到该字典的某一个元素该怎么办?首先我会在h[0]进行查找,如果在h[0]找不到的话则再去h[1]上进行查找。
在增加操作中的增加的元素都一律保存在新表h[1]当中,这将意味着一旦发生扩容操作h[0]的值是不会改变的。
如果在搬迁的过程中并没有对字典进行操作那怎么办?是否就意味着不会进行rehash操作了?当然不是。如果字典后面没有进行操作的话,redis还有一个定时器任务,redis将会在定时器任务中对字典进行搬迁操作
三、hash攻击
hashtable中key的分布的均匀程度影响到redis的性能,但是如果一个hash函数存在偏向性,那么黑客可以利用这个偏向性对服务器进行攻击,使得key的分布堆积在某一个数组当中,这样会使得链表非常的长,导致查找的效率下降,可能查询的时间复杂度退化到O(n)级别,这样服务器很容易崩溃,这就是hash攻击。
四、扩容条件
当hash表中元素的个数等于数组长度的时候将会进行扩容操作,扩容的大小为原来数组的2倍。不过如果redis正在做bgsave操作为了加少过多的内存页分离(COW操作),redis此时尽量不会去扩容。如果hash表中的元素长度为数组长度的5倍以上,将会进行强制扩容。
五、缩容条件
当hash表进行删除操作,元素个数低于数组长度的10%,将会进行缩容操作。缩容操作不会考虑redis是否在进行bgsava操作。
参考:http://redisbook.com/preview/dict/incremental_rehashing.html