Android中音频元数据的采集,及RTMP推流
在用手机做直播推流时,不管是录屏直播,还是摄像头直播,都要用到音频的元数据.
在Android中,可以借助AudioRecord来采集音频数据,然后通过faac编码库(加入用的音频编码器是faac),将编码后的数据交给RTMP去封包后发送给服务器.
这篇主要讨论从AudioRecord获取音频数据,然后通过faac编码,经过RTMP封包后发送到直播服务器的过程.
一,
如果要使用手机的录音功能,需要在AndroidManifest.xml中申请权限,
除了在AndroidManifest.xml中声明这个权限外,android6.0之后的版本还需要动态申请这个权限.
在Android6.0以后,也不是所有的权限,都需要动态申请,如果你不确定自己声明的权限是不是需要动态申请,可以用命令查询下,都有那些权限需要动态申请:
adb shell pm list permissions -g -d
执行这个命令,会列出需要动态申请的权限, 从这里也可以看出android对权限的管理以Group的形式来管理的.
group:android.permission-group.MICROPHONE
permission:android.permission.RECORD_AUDIO
你可能会有疑问,既然都去动态申请了,AndroidManifest.xml中的权限声明是不是多余的.答案肯定不是多余的,如果要说明白这个Runtime Permissions的问题还是有点复杂的,这不是这篇文档的主题,所以简单的说下:
Zygote在孵化出一个进程后,会根据这个进程的Mount Mode,把这个应用程序挂在不同的挂在点,这个Mount mode的取值是由PackageManagerService解析应用的AndroidManifest.xml中的权限申请来得出的.当应用程序获得Runtime permission后,PackageManagerService会通过mount service 向vold传递一个remount_uid的命令,这一命令会对进程的Mount point做出调整.
接着看怎么使用AudioRecord来获取音频元数据.
先要创建一个AudioRecord对象,然后开启录音,当然这个要在一个子线程来做,AudioRecord构造函数的参数:依次是声音的来源,采样率,声道数,采样位,保存采样数据的最小缓冲区大小.
AudioFormat.ENCODING_PCM_16BIT,每一次采集的数据用两个字节表示,就是每次采集的数据占多少位。
minBufferSize,存储采样数据的最小缓冲区的大小。
private final int mSampleRate;
private int channelConfig;
private int minBufferSize;
private AudioRecord mAudioRecord;
private byte[] buffer;
minBufferSize = AudioRecord.getMinBufferSize(sampleRate, channelConfig, AudioFormat.ENCODING_PCM_16BIT);
mAudioRecord = new AudioRecord(MediaRecorder.AudioSource.MIC,
mSampleRate, channelConfig, AudioFormat.ENCODING_PCM_16BIT, minBufferSize); //创建AudioRecord来录音,作为推流端,应该要实现码率自适应,在网络不佳时,降低推流码率来降低上行带宽压力。
//rtmp的使用,从协议层面讲,累积延迟是它的一个特征,因为RTMP基于TCP,所以不会丢包,
// 在网络状况不好时,有超时重传策略,缓冲策略,自然会带来累积延迟。
然后在一个子线程开启录音,就可以获取到声音数据了:
mAudioRecord.startRecording();
while (mAudioRecord.getRecordingState() == AudioRecord.RECORDSTATE_RECORDING) {
int len = mAudioRecord.read(buffer, 0, buffer.length);
if (len > 0) {
}
}如果len >0表示正常获取到声音数据了,并保存在了字节数组buffer中,返回值len表示此次获取的样本数(不是字节数)
接着就可以把buffer中的数据送给faac编码器编码:
二,
faac编码库的使用.
使用faac声音数据编码的步骤:
1,使用faacEncOpen打开编码器
2,使用faacEncSetConfiguration配置编码器参数
3,使用 faacEncEncode编码声音数据,
faacEncHandle codec = 0;
unsigned long maxOutputBytes;
unsigned long inputByteNum;
//使用faac对声音数据编码
void AudioChannel::openCodec(int sampleRate, int channels) {
unsigned long inputSamples;
//创建编码器,第三,四个参数,是两个指针,这种形式是要给实参赋值,
// inputSamples输入样本数,要送给编码器编码的样本数,编码器表示要输入这么多数据,才能编码出一帧数据,
codec = faacEncOpen(sampleRate, channels, &inputSamples, &maxOutputBytes);
//从样本数 ,*2,得到字节数,因为sample是16bit(AudioFormat.ENCODING_PCM_16BIT),所以要得到字节数就 *2.
//在录制声音时,mAudioRecord.read的buffer大小,可以设置为跟inputByteNum相同,所以java层可以get这个大小,
inputByteNum = inputSamples * 2;
//
outputBuffer = static_cast(malloc(maxOutputBytes));
//得到编码器当前默认的参数配置。
faacEncConfigurationPtr configurationPtr = faacEncGetCurrentConfiguration(codec);
//配置成自己需要的参数。
configurationPtr->mpegVersion = MPEG4;
configurationPtr->aacObjectType =LOW;
//值 0,表示编码出aac裸数据,
//值 1,表示每一帧编码出来的数据,都会携带ADTS头信息(包含了采样,声道等信息),如果编码后直接保存成aac文件,可以用这个。
configurationPtr->outputFormat = 0;
configurationPtr->inputFormat = FAAC_INPUT_16BIT;
faacEncSetConfiguration(codec, configurationPtr);
} 对从AudioRecord读取的音频裸数据,进行编码,
unsigned char *outputBuffer = 0;
void AudioChannel::encode(int32_t *data, int len) {
//第三个参数,是输入的样本数,而不是字节数
//第四个参数,输出编码后的结果,
//第五个参数,输出缓冲区(第4个参数)能接收的数据的字节数
int byteLen = faacEncEncode(codec, data, len, outputBuffer, maxOutputBytes);
if (byteLen > 0) {
RTMPPacket *packet = new RTMPPacket;
//因为还要拼接audio specific config(0XAF 0x00)来记录音频格式,或者普通数据 0XAF 0x01,所以多加2个字节。
RTMPPacket_Alloc(packet, byteLen +2);
//标记这段数据时音频。
packet->m_body[0] = 0xAF;
packet->m_body[1] = 0x01;
//装入裸数据
memcpy(&packet->m_body[2], outputBuffer, byteLen);
packet->m_hasAbsTimestamp = 0;
packet->m_nBodySize = byteLen + 2;
packet->m_packetType = RTMP_PACKET_TYPE_AUDIO;
//这个通道的值没有特别要求,但是不能跟rtmp.c中使用的相同,也不能跟发送Video的Packet中设置的相同。
packet->m_nChannel = 0x11;
packet->m_headerType = RTMP_PACKET_SIZE_LARGE;
//在使用完packet,要释放。
callback(packet);
}
}音频数据推流到服务端,要让播放器拉流后能正常播放,需要指定音频格式信息:audio specific config.
音频的这个信息只需要在发送声音数据包之前发送一个就可以了.
//如果不拼audio specific config(0XAF 0x01),播放器将不知道怎么解码,也就播放不出声音。
//所以这段audio specific config数据,需要在发送音频数据前,发送给服务器。
void AudioChannel::sendAudioConfig() {
u_char *buf;
u_long len;
faacEncGetDecoderSpecificInfo(codec, &buf, &len);
RTMPPacket *packet = new RTMPPacket;
RTMPPacket_Alloc(packet, len +2);
packet->m_body[0] = 0xAF;
packet->m_body[1] = 0x00;
memcpy(&packet->m_body[2], buf, len);
packet->m_hasAbsTimestamp = 0;
packet->m_nBodySize = len +2;
packet->m_packetType = RTMP_PACKET_TYPE_AUDIO;
packet->m_nChannel = 0x11;
packet->m_headerType = RTMP_PACKET_SIZE_LARGE;
callback(packet);
}三,使用RTMP推流的流程:
extern "C"
JNIEXPORT jboolean JNICALL
Java_com_test_livedemo_connect(JNIEnv *env, jobject thiz, jstring url_) {
int ret;
const char *url = env->GetStringUTFChars(url_, 0);
//rtmp的使用,从协议层面讲,累积延迟是它的一个特征,因为RTMP基于TCP,所以不会丢包,
// 在网络状况不好时,有超时重传策略,缓冲策略,自然会带来累积延迟。
do {
//申请内存,
rtmp = RTMP_Alloc();
//初始化,
RTMP_Init(rtmp);
//设置地址,如果地址不合法,会返回0,
if (!(ret = RTMP_SetupURL(rtmp, const_cast(url)))) {
break;
}
//开启输出模式,
RTMP_EnableWrite(rtmp);
//连接服务器,
if (!(ret = RTMP_Connect(rtmp, 0))) {
break;
}
//连接流,
if (!(ret = RTMP_ConnectStream(rtmp, 0))) {
break;
}
} while (0);
//第一个参数jstring变量,要释放的本地字符串的来源,第二个参数,要释放的本地字符串,
env->ReleaseStringUTFChars(url_, url);
return ret;
} //每编码一帧,就发送出去。如在不同线程,都会操作rtmp,需要加锁
连接服务器成功后,获取一个当前时间:
startTime = RTMP_GetTime();
void callback(RTMPPacket *packet) {
pthread_mutex_lock(&sendMutex);
if (rtmp) {
//指定这个packet要推向的stream_id;建立rtmp时,是要跟某个stream建立连接,数据就推到这个流中,
packet->m_nInfoField2 = rtmp->m_stream_id;
//时间是相对连接服务器成功后的时间,
packet->m_nTimeStamp = RTMP_GetTime() - startTime;
//第三个参数1,表示把数据先放入一个队列,按次序发送,这一中异步发送的情况。
RTMP_SendPacket(rtmp, packet, 1);
}
pthread_mutex_unlock(&sendMutex);
RTMPPacket_Free(packet);
delete packet;
}
四, 为什么RTMP封包要多加2个字节,0XAF 0x01, 或0XAF 0x00
RTMP 包中封装的音视频数据流,其实和FLV/tag封装音频和视频数据的方式是相同的,按照FLV格式封装音视频,在裸数据前需要添加的标记如下:
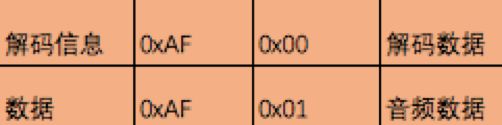
0xAF的来历,参考这个配置信息:

编码配置为,10:AAC,3:44100采样率,1:采样长度,1:声道,按照位数表示数据就为:0xAF.