NLP-3:从Transformer 到 BERT
目录
- 1. Review ELMo and Transformer
- 2. Bert
- 2.1 Bert Structure
- 2.2 Training Tips
- 2.3 Applications
- 3. Anti-Bert
- 4. Recap
以下内容来自贪心学院NLP直播课。
简介:在18年年底的时候,有一件事情轰动了整个NLP界,它就是大家所熟悉的BERT模型,它刷新了整个文本领域的排行榜,受到了全球的瞩目。之后,很多公司慢慢开始采用BERT作为各种应用场景的预训练模型来提高准确率。在本次讲座里,我们重点来讲解BERT模型以及它的内部机制。(其实核心是Transformer)
1. Review ELMo and Transformer
首先,我们看一下一词多意的问题

Elmo 提供了一个很好的方法 去 解释这种一词多意的问题。
之前的Word2Vec 等都是静态的词向量,而不会根据上下文来更新词向量。
Elmo 的词向量含有上下文的信息,所以同一个词在不同的上下文中 Elmo学习后得到的词向量也是不一样的。

Elmo 采用的是 character CNN 去建立整个单词的表达。
如果这边把LSTM 换成 Transformer 那么跟Bert比较相似了。


Transformer Vs LSTM:
LSTM 是RNN based model, 是一个个迭代的,只有前一个训练完了 才能训练下一个词。
Transformer 可以并行计算,结合positional encoding ,和self attention 机制。

Transformer 最重要的 多头注意力机制。 根据word embedding 获取 Key Query Value 通过attention 公式 得到 attention score.

Transformer 可以分解成5部分:
- positional encoding 来提供 位置信息
- Multi-head attention:
- Add and Norm(skip connection): skip connection 的好处是防止梯度消失的问题
- FNN
- Layer Norm
2. Bert

2019年的BERT + DAE + AoA 在SQuAD2.0中已经超过 human
最新的榜单 Albert 已经超过BERT。ALBERT 虽然是BERT 瘦身版本,但是模型里面添加的其他参数使得模型效果也很好。

Bert是什么?
Bbidirecitonal: 双向, Encoder: 只用到了Encoder. Re
Bert 2 个部分: Pre-Training是大量数据做训练。fine-tuning是基于预训练的词向量 在具体问题上做微调得到 具体问题的 模型。
Bert :
- 预训练词向量
- 采用Transformer 作为核心,(GPT是第一个用Transformer作为encoder的 但是GPT是单向的)
- 双向

2.1 Bert Structure
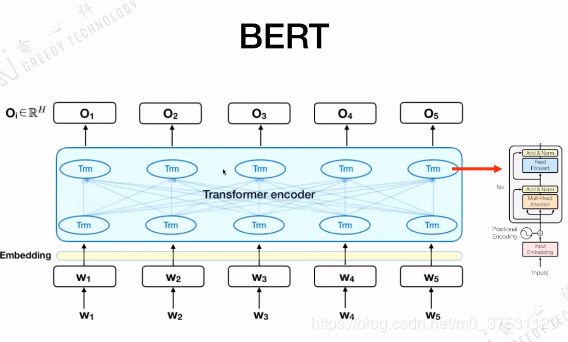
Bert 核心是Transformer的 Encoder,从上图中可以看出 输入词 embedding后都是丢进去Transformer的Encoder里面,通过多层Transformer (base 12层、large 24层)输出O(output 词向量的表达)。在每一个Transformer Encoder中 都有 Multi-head attention 结合上下文+positional encoding 等。 多层+多头注意力。

我们来看一下 输入:3个部分。
- Token embedding(sub-word embedding, word piece BPE):实际的输入词的word embedding
- Segment Embedding :代表sentence A 还是B
- Position Embedding :标识每个token的位置
(BERT 输入是上面3个加起来)
CLS: 是用来做分类的任务。(BERT 里面放到第一个 应该是没有特别的意义,放到中间或最后也行)
SEP:作为句子结束的标记

Bert 是如何做Pre-Training?
答:基于2个task(MLM, NSP),同时训练这2个task,所以损失函数 是多任务的损失。

Mask Language Model: 灵感来自于完形填空。
15%被mask Bert 代码中mask实现方法
- 80% 用 Mask
- 10%用其他词
- 10%不动
在这个任务中,我们只关注 被mask的token. 其他的不管。

NSP 主要关注2个句子之间的关系。
实际训练时,采用的训练集合:50% 50%
只用到了CLS 来分辨是否是 正确的 next sentence
(可以参考:BertForSequenceClassification)
2.2 Training Tips

BERT 训练技巧
- dupe_factor: 生成更多的 数据 用来做训练(可以mask不同的位置 )
- max_predictions_pre_eq
- do_whole_word_mask: mask整个单词 而不是 word pieces 因为
- 如果文档里面的长度超过了Bert的限制,那么建议随机从句子里面remove一些token 达到这个limit。(比如去除一些 stop words 等)

Bert 12个 head 分别学到什么?
比如图中head 1 连接很密,学到的 更广泛的内容。 head3-1主要是next token, head7-8 学到的是 SEP,head 11-14倾向于标点符号等,也就是每一个head学到的都不一样。

Bert 12个layer,上图中不同颜色表示不同的layer, 可以看出 同一个layer 的点离的比较近,说明在同一层 的都差不多
对于12 head 12 layer, 每层内容差不多,每层的每个head 学到的内容不同。

我们可以看看 BERT 到底学到了什么。 上图是几个NLP的任务,横坐标代表Transformer的 24层, 纵坐标表示该层发挥的作用大小。
比如第4个Coreferen resultion, 从图中可以看到BERT 发挥作用的是在18-19-20层。
对于SRL 的任务,BERT 主要在12-13-14层发挥比较大的作用。
Elmo 对每个词提供了3个embedding 然后把这3个加起来做词向量
Bert large 有24层,提供了24个embedding, 那么如何汇总这24层呢? 可以用weighted sum. 对于不同的任务 可以用权重来表示,上图就是每层占的权重。

Multilingual version 用104种语言来训练的。
2.3 Applications

有 pre-trained 的bert model, 能怎么用呢? 上图显示了可以应用的领域。

文中提到了4种 任务的微调
- 分类问题 只需要用CLS(两个句子是否相关,是否是next,是否是答案等)(一个句子的主题是什么? 意图是什么?)
- QA 的问题中, sent1是question, sent2是paragraph。就是在sent2中找到sent1 的答案。 在QA中 需要有一个Start和一个End token. 用Start vector去点乘 paragraph的每一个vector 通过softmax 得到概率最大的 index, 然后end再做同样的操作 获取end的index 从而 获取从 start到end的 answer,如果 end的index 小于start index 则认为 没有答案。

QA 系统中 如何应用BERT?
QA 中分2个阶段:(第一步检索,第二步QA)
- 检索:(BM2.5)搜索到排序 尽可能缩小范围,找出与question相关的文章。
- QA:有pre-trained bert + 数据集,再fine-tuning 模型得到的训练好的模型,可以上线用于QA 系统。
Bert的应用可以提高30%

命名实体识别(NER):也可以BERT 来完成。 Bert 本质是一个seq2seq的model,输出的结果是O,B,PRE等类别。。可以参考很多文章比如BERT+CRF等
(https://blog.csdn.net/m0_37531129/article/details/103321814)

Bert 用于 聊天机器人,意图识别。
上图是用bert解决单轮对话的问题。可以参考右下角的论文。
对于多轮对话,Bert 还没有很好处理 聊天tracking等

Bert 可以用 阅读理解(这个跟QA 相似 但是不一样),阅读理解参考的上下文更多,QA参考内容比较短。


Bert 太大了 所以我们希望可以压缩Bert 方便使用

我们主要讲 Knowledge Distilation
- DistilBert
- TinyBert
Teach-students 的模式 来做模型压缩。也就是training一个学生无限接近老师,但是模型比较小。
按照 老师传授给学生 ,使学生的结果无限接近老师最后做decision的过程。DistilBERT专注于最后decision的过程,前面不学习。TinyBert是从里到外都学习,而不是专注于最后decision。
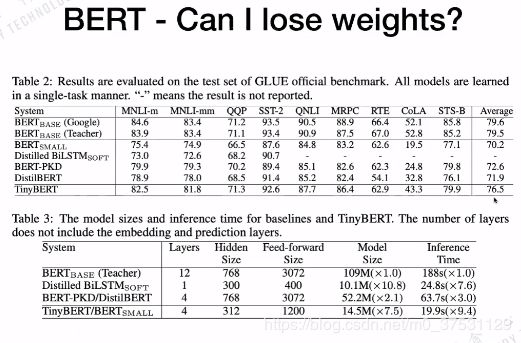
我们看出tinyBert 结果已经很接近Bert,但是模型确实比BERT 小很多。
3. Anti-Bert

ARCT 这个数据集,BERT 已经可达到0.77 基本接近于人的得分。

研究者发现 句子里面有NOT时 正确率61% ,当他们去除Not 或者2个答案更换 结果只有50% 相当于随便猜测。。


在文中随便添加一些片段,结果BERT 的结果显著下降。。
这个说明目前评价的方法 不足够 去 评估。。
4. Recap

(做语言生成任务 可以结合Transformer去考虑问题 )
其实可以把Transformer 作为一个元素 (就想一个RNN/LSTM一样)来考虑如何构建模型。 Bert只也是Transformer的encoder组成的。