python案例实战之一
分析思路:
1、明确分析目标;
2、导入库、导入数据;
3、简单查看下数据行列、整体情况;
4、数据清洗;
5、确定维度和指标;
6、分析并作图
1、查看整体数据情况
1.1引入使用的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
1.2加载数据文件
df = pd.read_csv('./FIFA_2018_player.csv')
1.3简单查看数据整体情况
df.head()

数据表头说明:
ID:编号
name:球员姓名
full_name:球员全名
nationality:国籍
league:联赛
club:所属俱乐部
age:年龄
birth_date:出生日期
height_cm:身高
weight_kg:体重
eur_value:身价
eur_wage:周薪
df.describe()
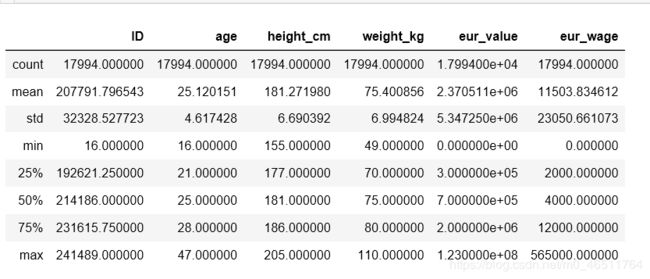
2、开始清理数据
数据清理-所有需要分析的数据都需要看下。
对于数值型,可以看下describe方法输出的信息,重点关注最大值,最小值,平均值,行数等。
2.1、查看整体数据量
f.count()

2.2、对null值处理
通过查看各列数据量情况(非null值)发现,league字段和club字段与其他字段存在差异。存在253行的null值,对于一万条数据来说影响还好,可以删掉。
#删除数据一般放在后面进行,这里因为其他数据也是异常,所以可以先删掉
df.drop(df[df.league.isnull()].index,inplace=True)
再次查看数据情况
df.count()

每列数据量一致,不存在null值。
2.3、查看整体统计量情况,查看是否存在异常
df.describe()

此处的身价最小的为0,但工资为1000,因此存在数据失真情况。
df[df['eur_value']<100]

我们对身价小于100的数据进行查看,存在6行数据异常。
对此种情况可有三种处理方式:
1、由于异常数据量较少,可依次查询真实数据并重新赋值;
2、取整体平均值,对异常数据进行覆盖;
3、由于总体数据量大,可直接删除异常数据。
本案例中采取第二种方式处理
df['eur_value'].replace(0,df['eur_value'].mean(),inplace=True)
df[df['eur_value']<100]
用整体平均值对异常数据进行覆盖后,查看身价是否还存在小于100的

2.4、查看是否有重复数据
df[df['full_name'].duplicated()]
 姓名重复的数据为102行,可随便抽取一条查看
姓名重复的数据为102行,可随便抽取一条查看
df[df['full_name']=='Moussa Dembélé']

可以看到,虽姓名一致,但其他字段均不同,为重名但不同人的情况。
3、开始分析数据
3.1、整体数据量描述
df.count()

3.2、对常用统计量做简单描述
df.describe()
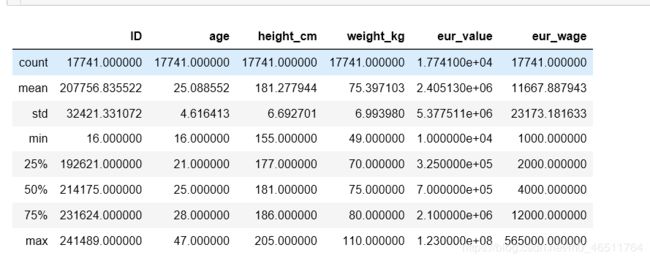
明确维度和指标:每一列、每几列可以作为一个维度;各种统计值为指标。
对于离散型的维度,一般使用groupby分组使用;对于连续型的维度,一般分区间。
3.3、离散型维度-国家维度的运动员数量
国家维度的运动员数,为离散型,使用groupby分组,并计算总和
df.groupby('nationality',as_index=False).count()
为方便后续数据使用,因此不需要用nationality设置索引,因此使用as_index=False

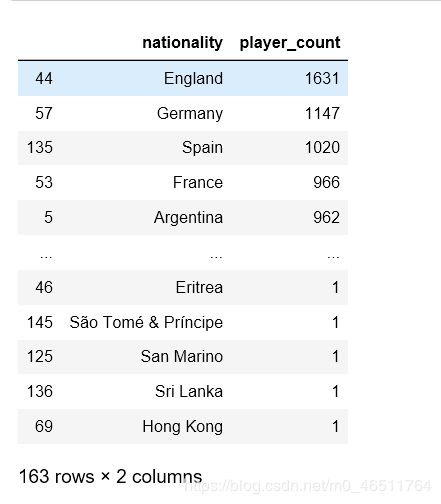
为方便查看,仅取国籍和数量两列,并根据球员数量进行排序
nationality_data = df.groupby('nationality',as_index=False).count()[['nationality','name']]
nationality_data.rename(columns={'name':'player_count'},inplace=True)
#按照player_count进行排序
nationality_data.sort_values('player_count',ascending=False)
3.4、连续型维度-选取年龄为例,以年龄为维度,以不同年龄段人数为指标
bins = np.arange(15,50,5)
bins_data = pd.cut(df['age'],bins)
bin_counts = df['age'].groupby(bins_data).count()
bin_counts

4、对分析结果进行可视化
bin_counts.plot(kind='pie')
