疯狂Java系列之Set集合
可以把set看成一个罐子,里面的元素就是多个对象无序的组合。
如果这个罐子是一个装有不同颜色的球,而罐子并不能做到给球编号或排顺序,你要想拿到红色的球,但是里面有很多红色的球,是根本确定不了,你到底要拿哪一个红色的球

Set的实现类有:hashSet类、LinkedhashSet类、Treeset类、EnumSet类,不全部说明,只拿出两个比较常用的类来介绍一下。
hashSet类
HashSet是Set接口典型实现,大部分使用set集合就是用的这个类。HashSet按Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
特点:
1、不能保证元素的排序;
2、hashset不是同步的,如果多个线程同时访问HashSet,必须通过代码来保证其同步;
3、集合元素值可以为null;
当向hashSet集合存入一个元素时,HashSet会调用Hashcode()方法,返回这个元素的hashcode值,然后根据code值决定其在hashSet中的位置。
代码:
package Set;
import java.util.HashSet;
public class hashSetTest {
public static void main(String[] args) {
HashSet person = new HashSet();
person.add(new A());
person.add(new A());
person.add(new B());
person.add(new B());
person.add(new C());
person.add(new C());
System.out.println(person);
}
}
class A
{
public boolean equals(Object obj){
//类A的equals()方法总是返回true
return true;
}
}
class B
{
public int hashCode()
{
//类B的hashcode()方法总是返回1
return 1;
}
}
class C
{
//类C的hashcode()方法总是返回2,equals()方法返回true
public int hashCode()
{
return 2;
}
public boolean equals()
{
return true;
}
}结果:
![]()
总结:分别添加两个A对象,B对象,C对象,只有A类中,两个对象值相等,但是hashcode值不相等,这样造成的结果是会判断两个对象是不相等,可以存储在两个位置上,和Set集合规则冲突。所以如果重写对象对应类的equals方法时,也应该重写hashCode()方法。
HashSet判断两个元素相等的标准是通过两个对象equals()方法比较对象相同,然后hashcode值也相等,满足这两个条件。两个元素就是相同的。因为如果hashcode值不同,两个元素是会被放到两个不同的位置的。不满足Set不允许相同对象。所以hashCode还有一个作用就是表示一个元素的唯一,根据hashcode值快速找到元素的存储位置。
TreeSet
TreeSet是SortedSet接口的实现类,TreeSet可以确保集合元素处于排序状态。看看它的方法:
Comparator comparator():采用定制排序,返回定制排序所使用的comparator;如果采用自然排序,则返回null;
Sorted subset(ObjectfromElement,Object toElement):返回Set子集合,范围从from到to;
Sorted headSet(ObjecttoElement):返回子集合,由小于toElement元素组成;
Sorted tailSet(ObjectfromElement):返回子集合,由大于fromElement元素组成。
代码:
package Set;
import java.util.TreeSet;
public class TreeSetTest {
public static void main(String[] args) {
TreeSet nums=new TreeSet();
//添加元素
nums.add(3);
nums.add(10);
nums.add(1);
nums.add(-2);
//输出集合元素,从运行结果看,已经进行了排序
System.out.println(nums);
System.out.println(nums.first());//第一个元素
System.out.println(nums.last());//最后一个元素
System.out.println(nums.headSet(3));//返回小于3的子集,不包含3
System.out.println(nums.tailSet(3));//返回大于3的子集,包含3
System.out.println(nums.subSet(-5, 11));//返回大于-5,小于11的子集
}
}
结果:
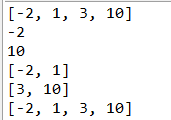
总结:treeSet并不跟插入顺序进行排序,而是根据实际的元素值进行排序。
Set实现类的性能分析
HashSet和treeSet是Set的典型实现类,那么到底选择哪个用好呢?
hashSet的性能比TreeSet的好,因为TreeSet需要使用红黑树算法来维护集合元素的次序,只有需要保持排序的Set时,才应该用TreeSet,否则都用HashSet;
HashSet还有一个子类,LinkedHashSet,对于普通的插入、删除操作,L比H略慢,因为它需要维护额外的链表,但是因为有链表,LinkedhashSet会更快。
EnumSet是所有Set实现类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
保证线程安全
必须指出,HashSet、TreeSet、EnumSet都是线程不安全的。如果多个集合访问Set集合,并且有超过一个线程修改了该Set集合,必须手动保证该Set集合的同步性。
可以通过Collections工具类的synchronizeSortedSet方法来包装该Set集合。
例如
SortedSet s =Collections.synchronizeSortedSet(new TreeSet());
蜕变的路并不好走,也走的不快,但是只要不放弃,就在一点点前进,并且现在所有学到的东西,都会在未来某一天找到它的使命,加油!