【JavaSE】JDBC(二):数据库连接池(C3P0、Druid)
上一篇: JDBC(一)基础.
JDBC系列二,前面知道了JDBC(一)基础部分,一些常规操作后,这部分来总结下数据库连接池技术。
本文目录
- 1.为什么使用数据库连接池
- 它解决了什么问题
- 2.什么是数据库连接池
- 3.如何使用数据库连接池
- DataSource接口
- C3P0
- Druid
- 一个新的JDBC工具类
- 4.总结
1.为什么使用数据库连接池
写一个JDBC的程序,我们总是要(注册驱动后)获取Connetion对象conn,即获取数据库连接,当我们完成了数据库操作后,又要去释放掉这个连接,conn.close();
public class JDBCDemo1 {
public static void main(String[] args) throws Exception {//异常都先抛出
//1. 导入驱动jar包
//2.注册驱动
Class.forName("com.mysql.jdbc.Driver");
//3.获取数据库连接对象
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/db1?useSSL=false", "root", "201703457");
//4.定义sql语句
String sql = "update user set password = 666666 where id = 1";
//5.获取执行sql的对象 Statement
Statement stmt = conn.createStatement();
//6.执行sql
int count = stmt.executeUpdate(sql);
//7.处理结果
System.out.println(count);
//8.释放资源
stmt.close();
conn.close();
}
}
一个程序来了后就创建一个新的连接对象,又一个程序就又创建一个新的,然后用完就释放掉关闭连接。如果你是将这个获取连接的步骤封装到了一个工具类。你看不见,但其实在工具类中也还是一样的,来一个就创建一个新的连接对象,再释放掉。这是不合适的,java程序想要访问数据库,需要Connection连接对象,是向我们系统底层申请一个Connection对象。申请到了资源,程序就拿着这个对象,连接和操作数据库。程序访问完了之后,就把连接释放掉了,相当于把资源归还给系统底层。每一个程序都这样,就会非常消耗我们的系统资源,资源浪费比较大。以访问MySQL为例,程序申请一个连接资源,系统主机会向服务器MySQL实例发出TCP/IP连接请求,连接成功后返回给程序一个连接对象,执行一条SQL,就有很多网络交互。
那我们可不可以使用完一个连接对象后,不去释放掉,而在下一次访问数据库的时候可以继续使用这个连接对象,就能避免反复申请连接,关闭连接。在这期望下,数据库连接池技术应运而生。
它解决了什么问题
程序还是要访问数据库,但是在程序访问之前,系统初始化好之后,我们人为的创建了一个"容器",然后在这个容器里面已经申请了很多个连接对象。程序访问数据库时,就不用向系统底层去申请连接了,而是从"容器"里面拿出一个连接对象,访问数据库。访问结束之后,程序会将连接对象归还给"容器",而不是释放掉。
这样做的好处是程序运行效率就会好很多,我们知道向系统底层申请资源是一个非常耗时的操作,每次申请资源释放资源会导致我们程序运行比较慢。直接从"容器"里获取连接对象,提高了系统性能。
并且"容器"里的连接对象被复用了,一个程序用完后归还,另一个继续使用再归还,尽可能多地复用了资源,利用率更高。
这种容器技术也被称为池子技术,高大上一点是一个设计模式:资源池(resource pool)。因为池子里放的是数据库连接,就称为数据库连接池。
2.什么是数据库连接池
概念:其实就是一个容器(在Java中就是一个集合),存放数据库连接的容器。
当系统初始化好后,容器被创建,容器中会申请一些连接对象,当用户来访问数据库时,从容器中获取连接对象,用户访问完之后,会将连接对象归还给容器。
基本原理是在内部对象池中维护一定数量的数据库连接,并对外暴露数据库连接获取和返回方法。用户可通过getConnection()方法获取连接,使用完毕后再通过Connection.close()方法将连接返回,注意此时连接并没有关闭,而是由连接池管理器回收,并为下一次使用做好准备。
数据库连接池的好处:
1. 节约资源
2. 用户访问高效
3.如何使用数据库连接池
DataSource接口是SUN公司已经定义好了,意思是数据源,也就是连接池。实现这个接口就可以获得数据库Connection对象,SUN公司程序员并没有实现这个接口,而是由提供数据库驱动程序厂商来实现。这里可以知道我们还是需要导入相应的数据库驱动程序的。
下面是数据库连接池的基本实现:生成标准的 Connection对象。
DataSource接口
DataSource接口:该工厂用于提供到此 DataSource 对象所表示的物理数据源的连接。在javax.sql包下的,简单讲可以创造Connection对象。我们只需要知道:
- 接口里面获取连接的方法:
Connection getConnection();方法返回的是一个Connection对象。 - 归还连接:
Connection.close()。如果连接对象Connection是从连接池中获取的,那么调用Connection.close()方法,则不会再关闭连接了,而是归还连接。 - 一般我们不去实现这个接口,由数据库厂商来实现。一般使用的都是开源的连接池技术,像:C3P0、Druid、DBCP等。
来说下两种不同的数据库连接池技术实现:连接MySQL数据库
C3P0
C3P0:数据库连接池技术
使用步骤:
1.导入jar包 (两个)
c3p0-0.9.5.2.jar和mchange-commons-java-0.2.12.jar ,不要忘记还要导入数据库驱动jar包。
Jar包资源: https://pan.baidu.com/s/1FzHVWJV5D6ljkv-gNHJ66A. 提取码:ou9t
2. 定义配置文件
- 名称:
c3p0.properties或者c3p0-config.xml。特别的名称要求,程序会自动去找寻这个配置文件 - 路径:直接将文件放在
src目录下即可。
配置文件c3p0-config.xml(资源里也提供了配置文件):
<c3p0-config>
<!-- 使用默认的配置读取连接池对象 -->
<default-config>
<!-- 连接参数 -->
<!--需要修改自己数据库路径、用户账号、密码-->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/db1?useSSL=false</property>
<property name="user">root</property>
<property name="password">201703457</property>
<!-- 连接池参数 -->
<!--初始化申请的连接数量-->
<property name="initialPoolSize">5</property>
<!--最大的连接数量-->
<property name="maxPoolSize">10</property>
<!--超时时间(单位毫秒)-->
<property name="checkoutTimeout">3000</property>
</default-config>
<!--自定义一个参数配置(可以有多个),配置名称为otherc3p0-->
<!--在创建c3p0连接池对象时,如果指定了配置名称,那么就会调用相应的配置,不指定就会调用默认配置-->
<named-config name="otherc3p0">
<!-- 连接参数 -->
<property name="driverClass">com.mysql.jdbc.Driver</property>
<property name="jdbcUrl">jdbc:mysql://localhost:3306/db1?useSSL=false</property>
<property name="user">root</property>
<property name="password">201703457</property>
<!-- 连接池参数 -->
<property name="initialPoolSize">5</property>
<property name="maxPoolSize">8</property>
<property name="checkoutTimeout">1000</property>
</named-config>
</c3p0-config>
3.创建核心对象:数据库连接池对象 ComboPooledDataSource
4.获取连接:调用getConnection()方法
//1.创建数据库连接池对象
DataSource ds=new ComboPooledDataSource();
//2.获取连接对象
Connection conn=ds.getConnection();
数据库连接池使用起来非常简单,相比一般的JDBC的程序只是换了一种获取连接对象的方式。这里不做使用例子,而是验证一下C3P0的配置参数,使用可以参照下面druid的例子程序。
C3P0配置参数验证
情景:验证连接池中最大连接数量和归还连接的Connection.close()方法。
/**
* C3P0演示
* 配置参数验证
*/
public class C3P0Demo2 {
public static void main(String[] args) throws SQLException {
//1.获取DataSource,使用默认配置
DataSource ds=new ComboPooledDataSource();
//使用指定名称配置的情况
//DataSource ds1=new ComboPooledDataSource("otherc3p0");
//验证连接池中最大连接数量
//for (int i = 1; i <=11 ; i++) {
//2.获取连接对象
//Connection conn=ds.getConnection();
//System.out.println(i+":"+conn);
//}
//验证归还连接的Connection.close()方法
for (int i = 1; i <=11 ; i++) {
//2.获取连接对象
Connection conn=ds.getConnection();
System.out.println(i+":"+conn);
if (i==5){
conn.close();//归还连接对象到连接池中
}
}
}
}
输出结果:
1.验证连接池中最大连接数量和超时时间
配置中最大连接数量设置是10,超时时间是3秒。当我们想要获取第11个连接对象时,程序经过3秒后报错。
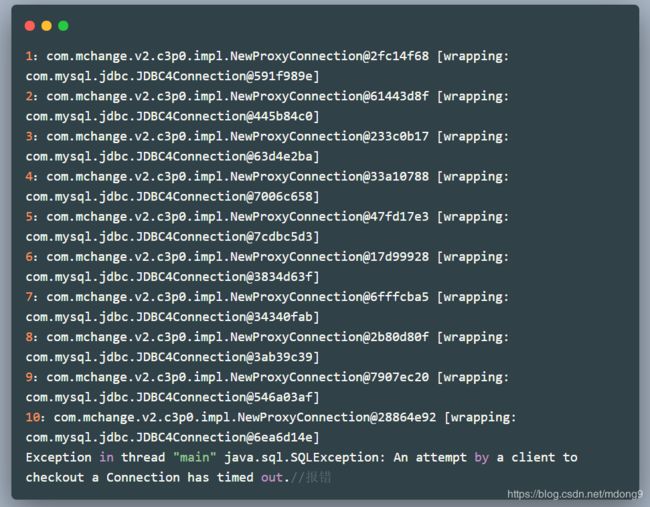
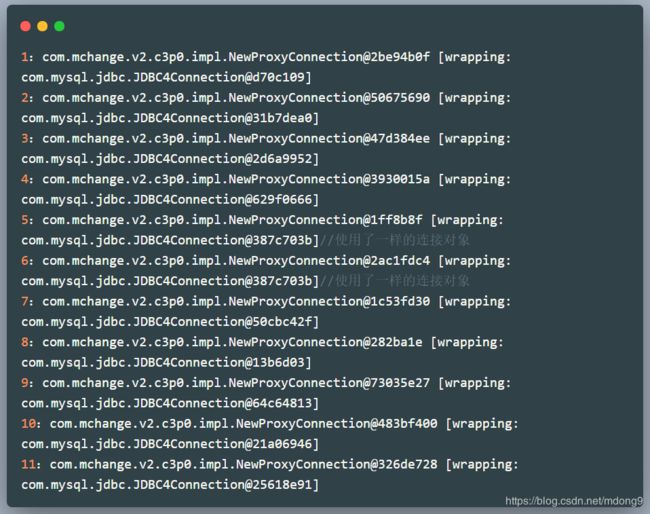
2.验证归还连接的Connection.close()方法
当获取到第5个连接对象时,我们使用close()方法归还连接,而获取第6个连接时,可以看到是和第5个的引用是一样的,所有可以证明,该方法是归还连接而不是关闭连接。
Druid
Druid:数据库连接池实现技术,由阿里巴巴提供的。
使用步骤:
1.导入jar包 druid-1.0.9.jar,和数据库驱动程序。
Jar包资源: https://pan.baidu.com/s/1xSQJnWlfsi_HMnlkJPREgg.提取码:tini
2.定义配置文件
- 是
properties形式的 - 可以叫任意名称,可以放在任意目录下。程序不会自动寻找,因此在使用时需要手动加载相应的配置文件。
配置文件(资源中提供了):druid.properties
# 加载数据库驱动
driverClassName=com.mysql.jdbc.Driver
# 连接数据库的url,db1表示数据库名,useSSL=false表示不使用SSL规范
url=jdbc:mysql://127.0.0.1:3306/db1?useSSL=false
# 用户登录数据库的账号和密码
username=root
password=201703457
# 初始化连接数量
initialSize=5
# 最大连接数量
maxActive=10
# 最大等待时间
maxWait=3000
3.加载配置文件。使用Properties集合
4.获取数据库连接池对象:通过工厂来获取 DruidDataSourceFactory
5.获取连接:getConnection()
/**
* Druid演示
*/
public class DruidDemo {
public static void main(String[] args) throws Exception {
//1.导入jar包
//2.定义配置文件
//3.加载配置文件
Properties pro=new Properties();
InputStream inputStream = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(inputStream);
//4.获取连接池对象
DataSource ds= DruidDataSourceFactory.createDataSource(pro);
//5.获取连接
Connection conn=ds.getConnection();
System.out.println(conn);
}
}
使用Druid的简单例子:
/**
* Druid演示
*/
public class DruidDemo1 {
public static void main(String[] args) {
/**
* 完成添加操作,向account表中插入一条记录
*/
Connection conn=null;
PreparedStatement pstmt=null;
try {
Properties pro=new Properties();
InputStream inputStream = DruidDemo.class.getClassLoader().getResourceAsStream("druid.properties");
pro.load(inputStream);
//获取连接池对象
DataSource ds= DruidDataSourceFactory.createDataSource(pro);
//1.获取连接
Connection conn=ds.getConnection();
//2.定义sql
String sql="insert into account(NAME,balance) values (?,?)";
//3.获取执行sql的对象
pstmt=conn.prepareStatement(sql);
//4.给?赋值
pstmt.setString(1,"DongDong");
pstmt.setInt(2,520);
//5.执行sql语句
int count = pstmt.executeUpdate();
System.out.println(count);
} catch (SQLException e) {
e.printStackTrace();
}finally {
//6.释放资源
try {
pstmt.close;
conn.close;
}catch (SQLException e) {
e.printStackTrace();
}
}
}
感觉比一般JDBC程序更复杂了,我们一般会封装使用连接池那部分代码,使用数据库连接池会让程序效率更高,提高系统的性能。我们重写一个JDBC工具类,还世界一片宁静。
一个新的JDBC工具类
1.定义一个类 JDBCUtils
2.提供静态代码块加载配置文件,初始化连接池对象
3.提供方法
获取连接方法:通过数据库连接池获取连接对象
释放资源方法
获取连接池的方法
JDBCUtils.java
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* Druid连接池的工具类
*/
public class JDBCUtils {
//1.定义成员变量DataSource
private static DataSource ds;
static {
try {
//1.加载配置文件
Properties pro=new Properties();
pro.load(JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"));
//2.获取DataSource
ds= DruidDataSourceFactory.createDataSource(pro);
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 获取连接对象
* @return
*/
public static Connection getConnection() throws SQLException {
return ds.getConnection();
}
/**
* 释放资源
* @param stmt
* @param conn
*/
public static void close(Statement stmt,Connection conn){
close(null,stmt,conn);
}
/**
* 释放资源
* @param rs
* @param stmt
* @param connection
*/
public static void close(ResultSet rs,Statement stmt, Connection connection){
if (rs!=null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (stmt!=null){
try {
stmt.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection!=null){
try {
connection.close();//归还连接
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 获取数据库连接池
* @return
*/
public static DataSource getDataSource(){
return ds;
}
}
然后我们再以上面向account表中插入一条记录为例,重写程序:
/**
* 使用新的JDBC工具类
*/
public class DruidDemo2 {
public static void main(String[] args) {
/**
* 完成添加操作,向account表中插入一条记录
*/
Connection conn=null;
PreparedStatement pstmt=null;
try {
//1.获取连接对象
conn= JDBCUtils.getConnection();
//2.定义sql
String sql="insert into account(NAME,balance) values (?,?)";
//3.获取执行sql的对象
pstmt=conn.prepareStatement(sql);
//4.给?赋值
pstmt.setString(1,"DongDong");
pstmt.setInt(2,520);
//5.执行sql语句
int count = pstmt.executeUpdate();
System.out.println(count);
} catch (SQLException e) {
e.printStackTrace();
}finally {
//6.释放资源
JDBCUtils.close(pstmt,conn);
}
}
}
运行一下,查看日志:

这就舒服多了,使用演示就到这。其他JDBC的操作,就换汤不换药了,相信很多小伙伴已经懂了。
4.总结
推荐使用Druid连接池技术,Druid是目前最好的数据库连接池之一,在功能、性能、扩展性方面,都超过其他数据库连接池,包括DBCP、C3P0、BoneCP、Proxool、JBoss DataSource。Druid已经在阿里巴巴部署了超过600个应用,经过一年多生产环境大规模部署的严苛考验。
本文对数据库连接池做了简单的总结,会持续扩展知识!!
欢迎点赞评论,指出不足,笔者由衷感谢o!