《利用python进行数据分析》学习笔记(一)
处理usa.gov数据
导入数据
import json
path = 'usagov_bitly_data2012-03-16-1331923249.txt'
records = [json.loads(line) for line in open(path)]
对时区进行计数
因为不是所有记录都有时区字段,所以必须加入if判断,否则报错。
# time_zones = [rec['tz'] for rec in records]
time_zones = [rec['tz'] for rec in records if 'tz' in rec]
- 计数函数
# 方法1
def get_counts(sequence):
counts = {}
for x in sequence:
if x in counts:
counts[x] += 1
else:
counts[x] = 1
return counts
# 得到前10位的时区及其计数值
def top_counts(count_dict, n=10):
value_key_pairs = [(count, tz) for tz, count in count_dict.items()]
value_key_pairs.sort()
return value_key_pairs[-n:]
counts = get_counts(time_zones)
print (counts['America/New_York'])
print(len(time_zones))
# 方法2
from collections import defaultdict
def get_counts2(sequence):
counts = defaultdict(int) # values will initialize to 0
for x in sequence:
counts[x] += 1
return counts
# 方法3
from collections import Counter
counts = Counter(time_zones)
# 得到前10位的时区及其计数值
counts.most_common(10)
用pandas对时区进行计数
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
frame = DataFrame(records)
tz_counts = frame['tz'].value_counts()
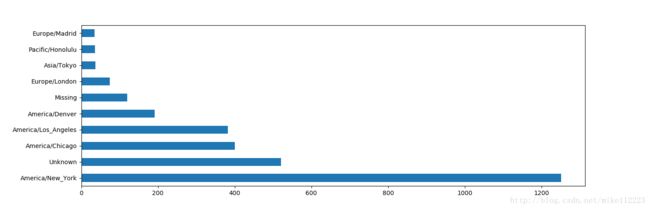
上述所有计数程序所要得到的就是如下图的时区与计数的键值对,换言之,所有的counts,tz_counts的结果形式如下图:

- 替换缺省值
clean_tz = frame['tz'].fillna('Missing')
clean_tz[clean_tz == ''] = 'Unknown'
tz_counts = clean_tz.value_counts()
print(tz_counts[:10])
运行上述程序后,上图中的计数521对应的空白键将会替换成‘Unknown’。
- usa.gov示例数据中最常出现的时区画图
import matplotlib.pyplot as plt
plt.figure(1)
tz_counts[:10].plot(kind='barh',rot=0)
plt.show()
利用pandas处理usa.gov中的a字段
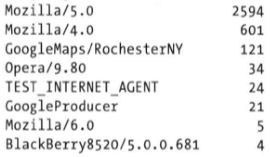
- 提取a段字符串的第一节(与浏览器大致对应),进行计数
print(frame.a[0].split())
results = Series([x.split()[0] for x in frame.a.dropna()])
print(results[:5])
print(results.value_counts()[:8])

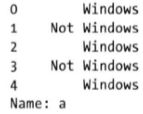
- 按windows和非windows用户进行计数
import numpy as np
cframe = frame[frame.a.notnull()]
operating_system = np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')
print(operating_system[:5])
- 根据时区和新得到的操作系统列表对数据进行分组
by_tz_os = cframe.groupby(['tz',operating_system])
print(by_tz_os.mean())
agg_counts = by_tz_os.size().unstack().fillna(0)
print(agg_counts[:10])

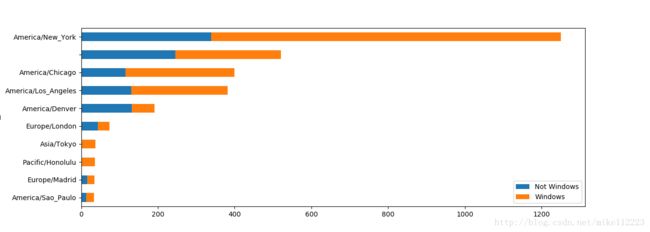
- 选取最常出现的时区然后画图
# 根据agg_counts中的行数构造一个间接索引数组
indexer = agg_counts.sum(1).argsort()
print(indexer)
count_subset = agg_counts.take(indexer)[-10:]
print(count_subset)
# 按windows和非windows用户统计的最常出现的时区
count_subset.plot(kind='barh',stacked=True)
plt.show()
# 按windows和非windows用户比例统计的最常出现的时区
normed_subset = count_subset.div(count_subset.sum(1),axis=0)
normed_subset.plot(kind='barh',stacked=True)
plt.show()

查漏补缺
记录处理usa.gov中遇到的不是很熟练的函数
1. collections.defaultdict()
defaultdict(function_factory)构建的是一个类似字典的对象,其中keys的值需要自行确定赋值,而values的初始值是默认值,并且values的类是由function_factory来决定的。由方法二中的defaultdict(int)为例:
from collections import defaultdict
counts = defaultdict(int)
print(counts)
print(counts['ad'])
print(counts)
输出结果如下
defaultdict(, {})
0
defaultdict(, {'ad': 0})
现在明了了,初始化的时候,counts里什么都没有,一旦赋予了键,那么counts里就有该键值对了(值是默认值,int型的默认值是0)。
http://www.pythontab.com/html/2013/pythonjichu_1023/594.html
2. collection.Counter()
Counter类是用来跟踪值出现的次数的,它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数值作为value。代码中用到的Counter.most_common([n])是用来返回一个topN列表的,谁出现的次数多,谁排在前面。
http://www.pythoner.com/205.html
3. pandas.Series.value_counts
Series.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
返回一个对唯一值计数的一个object,实际上就是一个map-reduce的过程。
parameters:
normalize : 布尔量,默认为False
- 如果是True,将会返回特定值出现的相对频率。sort: 布尔量,默认为True
- 根据计数值来排序ascending : 布尔量,默认为False
- 按升序排列,默认为False的话,就是降序bins : int型, optional
- 并不是计数,而是把它们归到一个个半开闭的区间,是一个对于pd.cut的便捷操作,只对数值数据有效。dropna : 布尔量,默认为True
- 不包括对于NaN的计数
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.value_counts.html
4. 处理缺失数据
- pandas.DataFrame.fillna
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
运用特定的方法填充 NA/NaN
# 是将缺失值变为空值(' ')
clean_tz = frame['tz'].fillna('Missing')
http://pandas.pydata.org/pandas-docs/version/0.17.0/generated/pandas.DataFrame.fillna.html
- pandas.DataFrame.dropna
DataFrame.dropna(axis=0, how=’any’, thresh=None, subset=None, inplace=False)
根据给定的轴和特定的方式进行数据剔除,返回剔除后的带有labels的object
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.dropna.html
- pandas.Series.isnull
Series.isnull()
返回一个布尔型的,同样大小的object,每个布尔变量指示的是值是否为null
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.isnull.html
- pandas.Series.notnull
Series.notnull()
返回一个布尔型的,同样大小的object,每个布尔变量指示的是值是否为not null
http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.notnull.html
5. numpy.where()
numpy.where(condition,[x,y])
根据condition来判断返回x还是y,如果condition没给,默认为nonzero().
# 判断a字段中是否含有'Windows',如果含有,返回'Windows',否则返回'Not Windows'
operating_system = np.where(cframe['a'].str.contains('Windows'),'Windows','Not Windows')
https://docs.scipy.org/doc/numpy/reference/generated/numpy.where.html
6. str.split()
str.split(str="",num=string.count(str))[n]
parameters:
str : str
- 表示为分隔符,默认为空格,但是不能为空(’’)。若字符串中没有分隔符,则把整个字符串作为列表的一个元素num: int
- 表示分割次数。如果存在参数num,则仅分隔成 num+1 个子字符串,并且每一个子字符串可以赋给新的变量[n] : int
- 表示选取第n个分片
http://www.jb51.net/article/63592.htm、