Python网络爬虫(四):selenium+chrome爬取美女图片
说明:
Python版本:Python
IDE:PyCharm
chrome版本:我的版本63
chromedriver.exe:因为是模拟浏览器访问,chrome需要再下载一个驱动,具体方式在我的上一篇博客,内容很详细。传送门:Python网络爬虫(三)chromedriver.exe与chrome版本映射及下载链接:
一、selenium
(1)selenium简介:
为什么用selenium?
前面我们学习了如何爬取一个静态网页,但是,面对有javascript渲染的页面再用前面的方式就不能得心应手。
所以我们选择selenium
什么是selenium?
一句话,自动化测试工具。它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器,如果你在这些浏览器里面安装一个 Selenium 的插件,那么便可以方便地实现Web界面的测试。换句话说叫 Selenium 支持这些浏览器驱动。Selenium支持多种语言开发,比如 Java,C,Ruby等等,而对于Python,当然也是支持的!
(2)安装selenium:
pip install selenium二、小试牛刀:
这里,我们以打开百度页面,并控制台输出百度页面源代码,为例。
代码:
from selenium import webdriver
if __name__ =='__main__':
list_urls=[]
url="http://www.baidu.com"
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19",--headless')
#options.add_argument('--headless')
#options.add_argument('--disable-gpu')
driver=webdriver.Chrome(chrome_options=options)
driver.get(url)
html = driver.page_source
print(html)如图,chrome浏览器自动打开了百度页面,控制台输出了页面源代码。
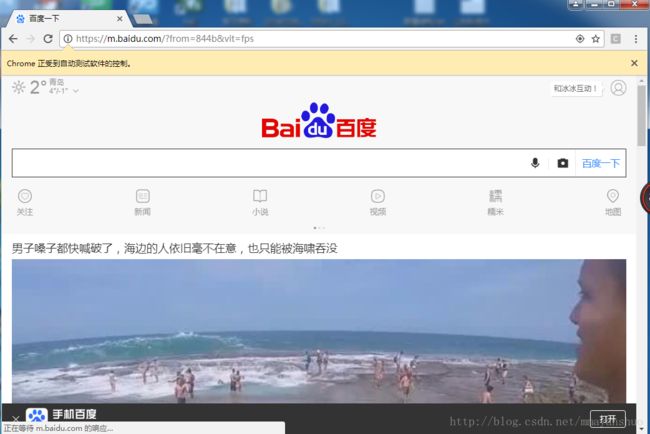
注意:
(1)注释的两行为使用chrome的headless模式,即不用每次都打开浏览器的窗口,否则,我们做爬虫时,爬取每个网页还跳出窗口,体验太差。自从chrome浏览器提供了headless chrome,相比PhantomJS(更早的一个无头浏览器),获得的数据更优质。但速度可能慢些。
(2) driver.get 方法会打开请求的URL,WebDriver 会等待页面完全加载完成之后才会返回,即程序会等待页面的所有内容加载完成,JS渲染完毕之后才继续往下执行。
所以,我们可以得到JS渲染之后的页面源码。
有了以上的基础,结合BeautifulSoup,我们完全可以作出好玩的事情。
(三)动手实战:爬取妹子图片
1、说在前面:
1.1 URL:http://www.5442.com/tag/rosi.html
1.2 用户代理:
'user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"我们用到的代理是安卓,事实证明比较好用。但是和你用电脑打开网页,通过审查元素看到的代码是不一样的,所以你分析网页的时候,需要用前面的例子,换掉百度的网址,运行程序,分析页面源码。
2、分析页面:
2.1 我们打开网页发现,每个图片分别放在了class属性为libox的div标签里。

所以,我们会先用BeautifulSoup获取主页面所有,class属性libox的div标签。再将每个标签的href存入list。
list_urls=[]
url="http://www.5442.com/tag/rosi.html"
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver=webdriver.Chrome(chrome_options=options)
driver.get(url)
html=driver.page_source
driver.close()
# print(html)
bf=BeautifulSoup(html,'lxml')
target_urls=bf.find_all(name="div",class_='libox')
for each in target_urls:
print(each.a.get('href'))
list_urls.append(each.a.get('href'))
print(len(list_urls))2.2 选择一张美女图片,我们看到,每个页面中有两张,为了简单起见,我们这里就下载每个页面的两张图片。
通过审查元素,我们可以看到,这两张图片放在了,align属性为center的p标签里。所以我们将用BeautifulSoup获得p标签中所有的src。之后,下载保存图片。
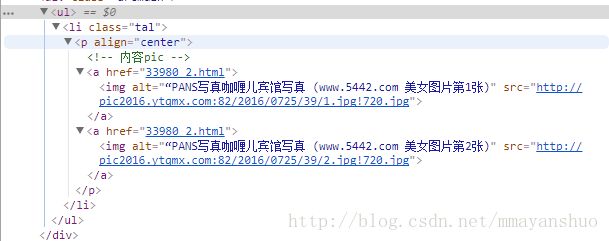
代码:
for each_img in list_urls:
target_url =each_img
options = webdriver.ChromeOptions()
options.add_argument(
'user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19",')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
pdriver = webdriver.Chrome(chrome_options=options)
pdriver.get(target_url)
img_html = pdriver.page_source
pdriver.close()
pbf=BeautifulSoup(img_html,'lxml')
piurls=pbf.find_all(name='p',align='center')
ppbf=BeautifulSoup(str(piurls),'lxml')
purls=ppbf.find_all(name='img')
if 'images' not in os.listdir():
os.makedirs('images')
for each in purls:
img_url=each.get('src')
img_filename='images/'+each.get('alt')+'.jpg'
print("正在下载",img_url)
urlretrieve(url=img_url,filename=img_filename)
urlretrieve()函数:
urllib 模块提供的 urlretrieve() 函数。urlretrieve() 方法直接将远程数据下载到本地。
urlretrieve(url, filename=None, reporthook=None, data=None)
· 参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
· 参数 reporthook 是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
· 参数 data 指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
3、运行程序:
代码我们已经写完了,运行一下,我们查看结果:
想了想,还是处理一下,别被和谐了。

(四)完整代码:
# -*- coding:UTF-8 -*-
'''
单进程
下载妹子图片
'''
from bs4 import BeautifulSoup
from urllib.request import urlretrieve
import os
from selenium import webdriver
if __name__ =='__main__':
list_urls=[]
url="http://www.5442.com/tag/rosi.html"
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19"')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
driver=webdriver.Chrome(chrome_options=options)
driver.get(url)
html=driver.page_source
driver.close()
# print(html)
bf=BeautifulSoup(html,'lxml')
target_urls=bf.find_all(name="div",class_='libox')
for each in target_urls:
print(each.a.get('href'))
list_urls.append(each.a.get('href'))
print(len(list_urls))
for each_img in list_urls:
target_url =each_img
options = webdriver.ChromeOptions()
options.add_argument(
'user-agent="Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19",')
options.add_argument('--headless')
options.add_argument('--disable-gpu')
pdriver = webdriver.Chrome(chrome_options=options)
pdriver.get(target_url)
img_html = pdriver.page_source
pdriver.close()
pbf=BeautifulSoup(img_html,'lxml')
piurls=pbf.find_all(name='p',align='center')
ppbf=BeautifulSoup(str(piurls),'lxml')
purls=ppbf.find_all(name='img')
if 'images' not in os.listdir():
os.makedirs('images')
for each in purls:
img_url=each.get('src')
img_filename='images/'+each.get('alt')+'.jpg'
print("正在下载",img_url)
urlretrieve(url=img_url,filename=img_filename)