Spark数据分析基础
spark大数据分析基础
1、spark简介
1.1 Spark程序
(1)驱动器程序
从上层来看,每个Spark应用都由一个驱动器程序(driver program)来发起集群上的各种并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。在spark-shell中,实际的驱动器程序就是Spark shell本身,你只需要输入想要运行的操作就可以了。
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表对计算集群的一个连接。shell启动时已经自动创建了一个Sparkcontext对象,是一个叫作sc的变量。一旦有了SparkContext,你就可以用它来创建RDD。
下面调用了sc.textFile()来创建一个代表文件中各行文本的RDD。我们可以在这些行上进行各种操作,比如count()。
val lines = sc.textFile("README.md") //创建一个叫Lines的RDD(2)Spark 分布式计算
执行各种计算操作,驱动器程序一般要管理多个执行器(executor)节点。比如,如果我们在集群上运行count()操作,那么不同的节点会统计文件的不同部分的行数。如果在本地模式下运行Spark shell,所有的工作会在单个节点上执行,但你可以将这个shell连接到集群上来进行并行的数据分析。下图展示了Spark如何在一个集群上运行。
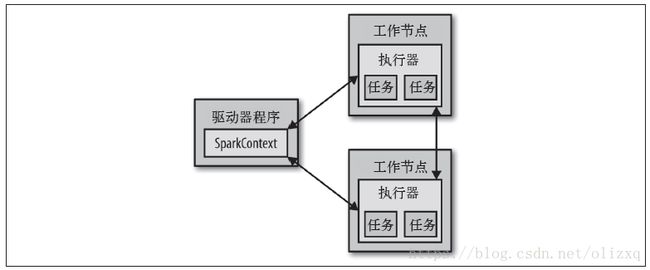
Spark 会自动将函数(比如line.contains(“Python”))发到各个执行器节点上,这样就可以在单一的驱动器程序中编程,并且让代码自动运行在多个节点上。
1.2 独立应用连接spark
Spark 可以在Java、Scala 或Python 的独立程序中被连接使用,这与在shell 中使用的主要区别在于需要自行初始化SparkContext,接下来就可以使用API。
- 在Java 和Scala 中,只需要给应用添加一个对于spark-core 工件的Maven 依赖;
- 在Python 中,把应用写成Python 脚本,但是需要使用Spark自带bin/spark-submit脚本来运行。spark-submit 脚本会帮我们引入Python 程序的Spark 依赖。
1.3 初始化SparkContext
一旦完成了应用与Spark 的连接,接下来就需要在你的程序中导入Spark 包并且创建SparkContext。通过先创建一个SparkConf 对象来配置你的应用,然后基于这个SparkConf 创建一个SparkContext 对象。
# 在Python 中初始化Spark
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc = SparkContext(conf = conf)// 在Scala 中初始化Spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
val conf = new SparkConf().setMaster("local").setAppName("My App")
val sc = new SparkContext(conf)2、RDD编程
2.1 RDD
RDD 是Spark 的核心概念。
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称RDD),RDD 其实就是分布式的元素集合。在Spark 中,对数据的所有操作不外乎创建RDD、转化已有RDD 以及调用RDD 操作进行求值。而在这一切背后,Spark 会自动将RDD 中的数据分发到集群上,并将操作并行化执行。
// 创建RDD
val lines = sc.parallelize(List("pandas", "i like pandas"))
val lines = sc.textFile("/path/to/README.md")2.2 RDD的操作
RDD支持两种操作:转化操作和执行操作。
- RDD 的转化操作是返回一个新的RDD 的操作,比如map() 和filter();
- 执行操作则是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算,比如count() 和first()。
- 转化出来的RDD 是惰性求值的,只有在执行操作中用到RDD时才会被计算。

// 统计单词个数
val wordcount = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).map(x => (x._2,x._1)).sortsByKey(false).
map(x => (x._2,x._1).saveAsTextFile("/data/resultsorted")3、pair RDD
3.1 创建pair RDD
在spark中有很多种创建pairRDD的方式,很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的pair RDD,此外需要把一个普通的RDD转化为pair RDD时,可以调用map函数来实现,传递的函数需要返回键值对。
scala> var lines = sc.parallelize(List("hello", "world"))
lines: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[8] at parallelize at :27
scala> val pairs = lines.map(x=>(x,1))
pairs: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[9] at map at :29
scala> pairs.foreach(println)
(hello,1)
(world,1) 3.2 pair RDD的转化操作
由于pair RDD中包含二元组,所以需要传递函数应当操作二元组而不是独立的元素。
假设键值对集合为{(1,2),(3,4),(3,6)}
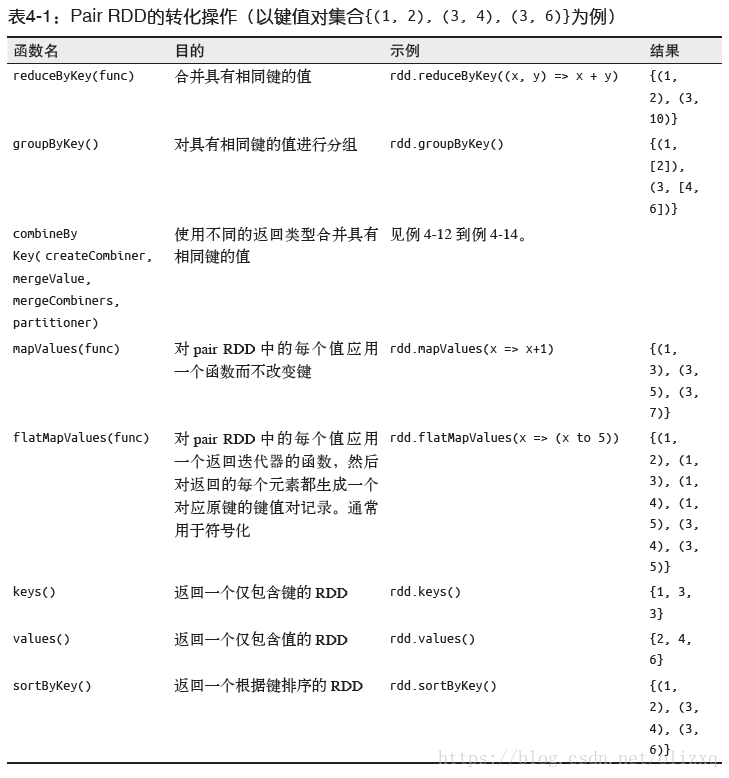
- rdd.reduceByKey(func):合并具有相同key的value值
scala> val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[12] at parallelize at :27
scala> val result = rdd.reduceByKey((x,y)=>x+y)
result: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[14] at reduceByKey at :29
scala> result.foreach(println)
(1,2)
(3,10) - rdd.groupByKey():对具有相同键的进行分组 [数据分组]
scala> val result = rdd.groupByKey()
result: org.apache.spark.rdd.RDD[(Int, Iterable[Int])] = ShuffledRDD[1] at groupByKey at :29
scala> result.foreach(println)
(3,CompactBuffer(4, 6))
(1,CompactBuffer(2)) - rdd.mapValues(func):对pairRDD中的每个值应用func 键不改变
scala> val result = rdd.mapValues(x=>x+1)
result: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[2] at mapValues at :29
scala> result.foreach(println)
(1,3)
(3,5)
(3,7) - rdd.flatMapValues(func):类似于mapValues,返回的是迭代器函数
scala> val result = rdd.flatMapValues(x=>(x to 5))
result: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[3] at flatMapValues at :29
scala> result.foreach(println)
(3,4)
(3,5)
(1,2)
(1,3)
(1,4)
(1,5) - rdd.keys:返回一个仅包含键的RDD
scala> val result = rdd.keys
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[4] at keys at :29
scala> result.foreach(println)
3
1
3 - rdd.values:返回一个仅包含value的RDD
scala> val result = rdd.values
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at values at :29
scala> result.foreach(println)
2
4
6 - 聚合操作:
使用reduceByKey()和mapValues()计算每个键对应的平均值
scala> val rdd = sc.parallelize(List(Tuple2("panda",0),Tuple2("pink",3),Tuple2("pirate",3),Tuple2("panda",1),Tuple2("pink",4)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[45] at parallelize at <console>:27
scala> val result = rdd.mapValues(x=>(x,1)).reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
result: org.apache.spark.rdd.RDD[(String, (Int, Int))] = ShuffledRDD[47] at reduceByKey at <console>:29
scala> result.foreach(println)
(pirate,(3,1))
(panda,(1,2))
(pink,(7,2))假设:rdd={(1,2),(3,4),(3,6)} other={(3,9)}

- rdd.subtractByKey( other ):删除掉RDD中与other RDD中键相同的元素
scala> val rdd = sc.parallelize(List((1,2),(3,4),(3,6)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[4] at parallelize at :27
scala> val other = sc.parallelize(List((3,9)))
other: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[5] at parallelize at :27
scala> val result = rdd.subtractByKey(other)
result: org.apache.spark.rdd.RDD[(Int, Int)] = SubtractedRDD[6] at subtractByKey at :31
scala> result.foreach(println)
(1,2) - rdd.join( other ):对两个RDD进行内连接
scala> val result = rdd.join(other)
result: org.apache.spark.rdd.RDD[(Int, (Int, Int))] = MapPartitionsRDD[12] at join at :31
scala> result.foreach(println)
(3,(4,9))
(3,(6,9)) - rdd.rightOuterJoin(other):对两个RDD进行连接操作,确保第二个RDD的键必须存在(右外连接)
scala> val result = rdd.rightOuterJoin(other)
result: org.apache.spark.rdd.RDD[(Int, (Option[Int], Int))] = MapPartitionsRDD[15] at rightOuterJoin at :31
scala> result.foreach(println)
(3,(Some(4),9))
(3,(Some(6),9)) - rdd.leftOuterJoin(other):对两个RDD进行连接操作,确保第一个RDD的键必须存在(左外连接)
scala> val result = rdd.leftOuterJoin(other)
result: org.apache.spark.rdd.RDD[(Int, (Int, Option[Int]))] = MapPartitionsRDD[18] at leftOuterJoin at :31
scala> result.foreach(println)
(3,(4,Some(9)))
(3,(6,Some(9)))
(1,(2,None)) - rdd.cogroup(other),将有两个rdd中拥有相同键的数据分组
scala> val result = rdd.cogroup(other)
result: org.apache.spark.rdd.RDD[(Int, (Iterable[Int], Iterable[Int]))] = MapPartitionsRDD[20] at cogroup at :31
scala> result.foreach(println)
(1,(CompactBuffer(2),CompactBuffer()))
(3,(CompactBuffer(4, 6),CompactBuffer(9))) 3.3 pair RDD的行动操作
和转化操作一样,所有基础RDD支持的传统行动操作也都在pair RDD上可用,pair RDD提供了一些额外的行动操作,可以让我们充分利用数据的键值对特性,如下
以键值对集合{(1,2),(3,4),(3,6)}为例

3.4 并行调优
每个RDD都有固定数目的分区,分区数决定了在RDD 上执行操作时的并行度,在执行聚合或分组函数时,可以要求Spark使用给定的分区,Spark始终尝试根据集群的大小,推断出一个有意义的默认值,但是有时候你可能要对并行度进行调优来获取更好的性能发展。
scala中自定义reduceByKey()的并行度
val data = Seq(("a",3),("b",4),("c",5))
sc.parallelize(data).reduceByKey((x,y)=>x+y) //默认并行度
sc.parallelize(data).reduceByKey((x,y)=>x+y,10) //自定义并行度3.5 获取RDD的分区方式
scala> val pairs = sc.parallelize(List((1,1),(2,2),(3,3)))
pairs: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[9] at parallelize at :27
scala> pairs.partitioner
res4: Option[org.apache.spark.Partitioner] = None
scala> val partitioned = pairs.partitionBy(new org.apache.spark.HashPartitioner(2))
partitioned: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[10] at partitionBy at :29
scala> partitioned.partitioner
res5: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@2) 4、数值RDD
Spark 的数值操作是通过流式算法实现的,允许以每次一个元素的方式构建出模型。这些统计数据都会在调用stats() 时通过一次遍历数据计算出来,并以StatsCounter 对象返回。

用Scala 移除异常值:
// 现在要移除一些异常值,因为有些地点可能是误报的
// 首先要获取字符串RDD并将它转换为双精度浮点型
val distanceDouble = distance.map(string => string.toDouble)
val stats = distanceDoubles.stats()
val stddev = stats.stdev
val mean = stats.mean
val reasonableDistances = distanceDoubles.filter(x => math.abs(x-mean) < 3 * stddev)
println(reasonableDistance.collect().toList)5、累加器和广播变量
5.1 累加器
累加器提供了将工作节点中的值聚合到驱动器程序中的简单语法。
累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
// 在Scala 中累加空行
val sc = new SparkContext(...)
val file = sc.textFile("file.txt")
val blankLines = sc.accumulator(0) // 创建Accumulator[Int]并初始化为0
val callSigns = file.flatMap(line => {
if (line == "") {
blankLines += 1 // 累加器加1
}
line.split(" ")
})
callSigns.saveAsTextFile("output.txt")
println("Blank lines: " + blankLines.value)• 通过在驱动器中调用SparkContext.accumulator(initialValue) 方法,创建出存有初
始值的累加器。返回值为org.apache.spark.Accumulator[T] 对象,其中T 是初始值
initialValue 的类型。
• Spark 闭包里的执行器代码可以使用累加器的+= 方法(在Java 中是add)增加累加器的值。
• 驱动器程序可以调用累加器的value 属性(在Java 中使用value() 或setValue())来访
问累加器的值。
5.2 广播变量
广播变量,它可以让程序高效地向所有工作节点发送一个较大的只读值,以供一个或多个Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,甚至是机器学习算法中的一个很大的特征向量,广播变量用起来都很顺手。
// 查询RDD contactCounts中的呼号的对应位置。将呼号前缀
// 读取为国家代码来进行查询
val signPrefixes = sc.broadcast(loadCallSignTable())
val countryContactCounts = contactCounts.map{case (sign, count) =>
val country = lookupInArray(sign, signPrefixes.value)
(country, count)
}.reduceByKey((x, y) => x + y)
countryContactCounts.saveAsTextFile(outputDir + "/countries.txt")(1) 通过对一个类型T 的对象调用SparkContext.broadcast 创建出一个Broadcast[T] 对象。
任何可序列化的类型都可以这么实现。
(2) 通过value 属性访问该对象的值(在Java 中为value() 方法)。
(3) 变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)。