从零上手变分自编码器(VAE)
阅读更多,欢迎关注公众号:论文收割机(paper_reader)
原文链接:从零上手变分自编码器(VAE)
- Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.
- Rezende D J, Mohamed S, Wierstra D. Stochastic backpropagation and approximate inference in deep generative models[J]. arXiv preprint arXiv:1401.4082, 2014.
关于VAE,网上的教程很多,但是通俗易懂又直击本质的中文教程几乎没有。VAE虽然是一个深度学习模型,但在设计过程中利用了很多概率统计知识。很多教程仅仅是长篇大论地推导公式,或是直接指出它作为深度模型的结构和约束,然而对于VAE的设计动机,却很少有教程提及。
这篇文章不仅同时介绍了VAE作为深度模型和概率模型的两方面特征,还对作者进行设计的动机进行了仔细的解释。笔者水平有限错误难以避免,但是希望借撰写这篇文章的机会,能和读者一起更好地了解这一模型。
1. VAE的适用情境和动机
VAE (Variational Autocoder, 变分自编码器) 同GAN一样,是近年来一种常用的深度生成模型。该模型最早分别由Kingma等人和Rezende等人在ICLR 14' 和ICML14' 上独立发表。
https://arxiv.org/abs/1312.6114
https://arxiv.org/abs/1401.4082
本文主要参照了Kingma的文章,对VAE的设计动机进行分析。
VAE作为一个生成模型,它的主要目的,就是为数据的隐变量加上先验。为了描述这一动机,我们可以参考如下的图模型:

其中,x是与训练数据对应的随机变量,而z对应的是影响数据分布的那些隐变量。
例如,对于手写数字识别这一问题,x对应的是数据集中的一张张图片,而z对应的是数据的标签,也就是这张图片所显示的数字是多少。显而易见,对于手写数字识别这个问题,每张图片中图案的形状,显然是由写字者想表达的数字来决定的。
或者说,每张写有数字“5” 的图片在形式上都大同小异,因为它们都想表达出 “数字5” 这一信息。而对于整个数据集来说,每张图片所表达的信息,也都是“数字0” ,“数字1” ,“数字2” …… “数字0”这10类其中之一。
因此,参数theta所对应的概率分布ptheta(z),代表的是数据集内图片所表示的各种数字的联合概率分布情况,随机变量z代表代表单张图片所代表的数字,而x则代表这张图片各个点的像素值。
同样地,在其他任务中,z与x也可以被赋予其他不同的含义,例如z与x分别对应“语义—文本”, “疾病—症状” ,或是单纯用z来代表数据的某个表达,也都是可以的。
而作为无监督的生成模型,VAE的应用条件也非常宽松,只要有无标注的训练数据,再为隐变量设定一个先验概率分布,就可以进行训练了。训练完成后,我们能得到的结果也是两个:
-
对训练数据的模拟,作为生成模型,VAE能生成与训练数据同分布的结果。
-
隐变量本身。VAE能为数据集中每个数据生成一个隐变量z,通过对隐变量分布情况的分析,可以得到一些关于数据分布情况的结论。
在下两章,我们将从深度学习和概率模型两个视角讨论VAE的设计逻辑。对于只关心VAE长什么样子,该怎么使用的读者,可以跳过这两章阅读。
2. 深度学习视角的自编码器
自编码器是一种无监督的深度学习模型,用来学习训练数据的某种压缩表达。最基本的自编码器结构非常简单。如下图所示,自编码器由编码器和解码器两部分组成,通过编码器可以学出对原数据的压缩表达,再通过解码器复原出原数据。

这里得到的z确实是原数据x的压缩表达,但z却很难被看成是x对应的隐变量,因为第一,z和x之间不存在明显的因果关系,第二,z也不服从我们对隐变量的先验分布ptheta(z)。因此,VAE做出了两个改进。
第一个改进是,传统自编码器中都是直接生成z的值,而VAE是先生成一个关于z的概率分布q(z|x),再用这个分布生成z。

第二个改进是,将隐变量z的分布情况也以KL散度的的形式加进模型的优化目标loss里。
这样当模型优化完成后,隐变量z的分布与先验分布之间的KL散度近似到0,我们就可以说隐变量z服从我们的先验了。
而这两个改进又带来了新的问题:从分布中采样这个操作是无法求偏导的,利用BP算法优化模型的时候,梯度传到这里就无法再计算下去了。作者在文章的后面利用Reparameterization trick解决了这一问题。
3. 概率模型视角的变分推断
VAE中实际上使用的概率图模型如下:
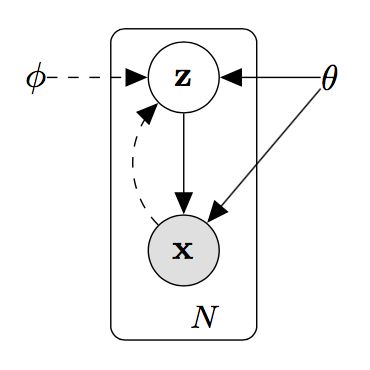
除了theta之外,图中引入了另外一个参数phi。这个模型的意义是这样的:数据x基于隐变量z生成,隐变量z服从参数为theta的分布ptheta(z),但由于p(x)和p(z|x)难以估计,使得theta的值难以优化。
比如说,通过患者的症状估计患者所患的疾病,虽然这两者之间存在因果关系,但实际上两者之间关系是十分复杂的。
因此,我们引入另外一个参数phi和对应的分布qphi(z|x),这是一个对复杂情况的简单估计。分布q往往是数学上容易计算的某些分布,phi是这个分布的参数。我们通过数据x来计算出phi,就能得到真实因果关系的一个近似。
在VAE中,通过x得到分布qphi(z|x)再得到z的这一过程被看做是编码器,而通过z还原x的这一过程,也就是从分布ptheta(x|z)中得出x的过程,被看做是解码器。
参数phi和theta就是深度网络模型中各个神经网络单元的参数,也就是我们要优化的参数。优化模型中参数phi和theta的过程如下,注意这里引入了变分下限:
![]()
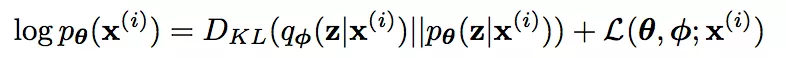
这里应用了变分推断的技巧,等式左侧是数据集内某一条数据出现的概率的对数,是一个无法被计算的常数,等式右侧第一项KL散度表示qphi(z|x)对ptheta(z|x)的逼近程度,是我们想要优化(最小化)的对象,第二项往往被称作evidencelower bound (ELBO,变分下限)。优化的目标是使变分下限最大,这样在等式左侧不变的情况下,KL散度就能取到最小。
而在论文中,作者给出了该情况下变分下限的两种形式:
![]()
![]()
![]()

分别记为(1)式和(2)式。原本来说,对于这样的公式,只要对参数求偏导就可以优化了。然而对于这个两个式子,直接求偏导进行优化会导致结果的极大波动,被认为是不可行的。
论文中原文如下:The usual (naïve) MonteCarlo gradient estimator for this type of problem exhibits exhibits very highvariance and is impractical for our purposes.
对于这一问题的具体分析,有兴趣的读者可以根据原文中提供的参考文献进一步了解。
笔者认为,这一问题的原因和深度学习视角中模型无法利用BP算法的原因是对应的。在深度模型中出现无法求偏导的采样操作,在图模型推导中,也对应出现了一个难以优化的概率期望E。为了解决这个问题,作者想出了一个叫做Reparameterization trick的技巧,使得对于某些常见的先验q(z|x)和p(z)(例如高斯分布),模型可以高效简洁地进行推断。
4. Reparameterization trick和两个视角的统一
以高斯分布为例,Reparameterization trick简单来说是这样的。
考虑从一个分布中抽样的过程:
![]()
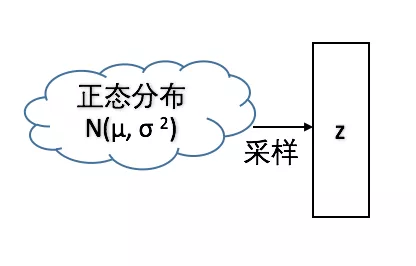
这个过程显然是不可导的,但如果是从一个正态分布中抽样,该分布的均值和方差分别为μ和σ的话,上面的抽样过程就可以变换成下面的形式:

显然这两种抽样方法得到的z是同分布的。但是第二种方法显然可以针对参数μ和σ求偏导数。同样,将z=μ + σε带入变分下限的表达式中,也可以最优化变分下限。
论文中给出了应用Reparameterization trick后,对于变分下限的(1)形式,变分下限的近似值LA:

其中,函数g是应用Reparameterization trick后,通过x与ε计算z的关系式(在正态分布下就是z=μ+ σε),l是对于一条数据而言采样ε(其实也就是z)的次数。
在实际应用中数据量够大时,对每条数据采样1次就可以了。
之后可以进一步估计整个数据集中的边际似然下界:
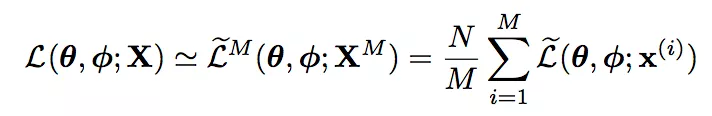
其中N是数据集中数据个数,M是minibatch的大小。
论文中还给出了训练算法的minibatch形式:

然而,无论是在论文的示例中还是其他什么地方,上述的这些复杂的训练方法都很少被用到,换句话说,上面那些都没什么卵用:)。
真正被使用的是变分下限的(2)形式,也就是这个:
![]()
带入Reparameterization trick之后形式是这样的:

这个式子中的KL散度一项,在应用Reparameterization trick之后,往往能直接计算(论文后文只给出了当p和q都是高斯分布时的推导,其他分布时的推导还是要靠自己啊),而后面的期望一项,不正是训练自编码器时候的重建误差吗?
论文中还说,这个方法因为需要采样估计的地方更少,所以和上一个方法比起来还更容易收敛。
所以绕了一大圈,我们又回到了原点。VAE的主要结构如下(以高斯分布为例):
![]()

其中μ和σ是在先验分布q为高斯分布时的参数,ε是从标准高斯分布中采样的结果。这个模型的loss也分为两部分组成,每部分形式和意义如下:
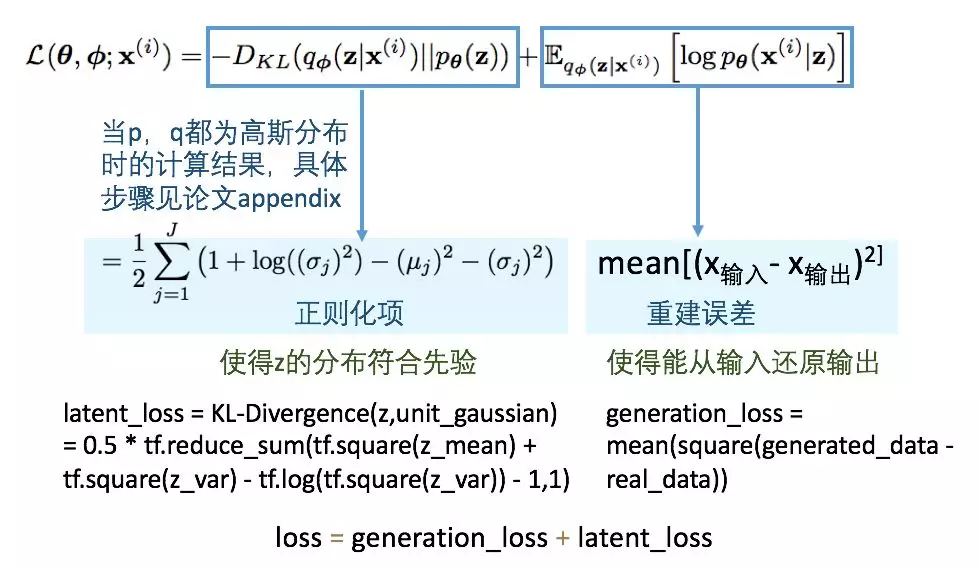
![]()
训练完成后,可以将隐变量z的分布做可视化,也可以利用解码器来生成更多数据。
5. 实例:手写数字识别
在这个例子?里,先验ptheta(z)是无参数的多元高斯分布 N(z, 0, I)。我们永远无法知道ptheta(z|x)是什么,但是qphi(z|x)的设置就自由得多。文中设置
![]()
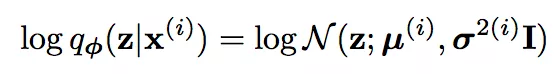
其中μ(i)和σ(i)是在输入为x(i)的时候,编码器的输出。在这个实验里,编码器和解码器都是MLP。
训练完成后,将解码器单独搬出来,就可以用它生成数据了。还可以把生成的z进行可视化,看看训练的效果如何。
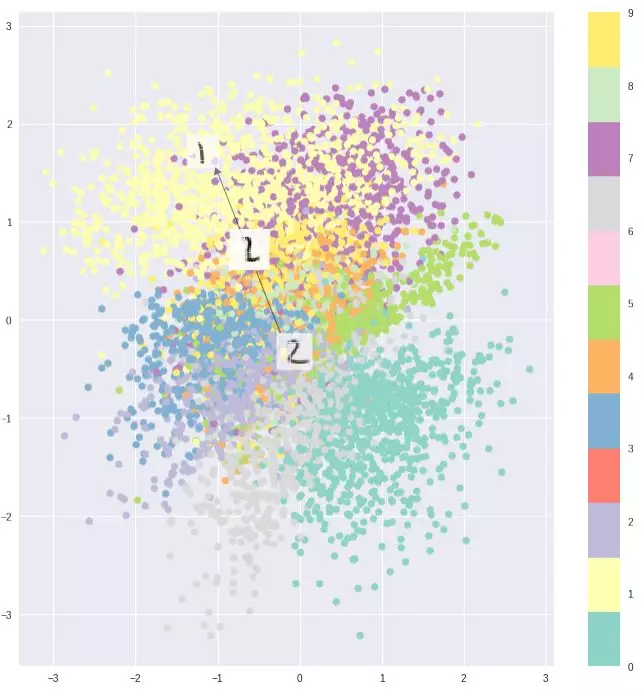
隐层可视化的常见效果如图,可以看到不同颜色的点在隐层被分为不同的几类。
6. 总结
这篇文章到此便结束了,算是对最经典的VAE进行了比较基础的解释。有很多具体细节限于篇幅没有讲清,因而读者如果有不懂的地方,还是要去看Kingma的原文。
但是希望读者们读了这篇文章之后,能够弄懂为什么模型要这样设计,以及VAE和原始的自编码器有什么本质上的不同。
在写这篇文章的过程中,我参考了很多大神们的英文教程
http://kvfrans.com/variational-autoencoders-explained/
https://jaan.io/what-is-variational-autoencoder-vae-tutorial/),
也感谢实验室师兄的讲解。
阅读更多,欢迎关注公众号:论文收割机(paper_reader)