从一阶线性模型到FFM
前言
说到CTR,CVR预估,最近几年无论是kaggle比赛,还是推荐算法、计算广告中,使用FFM模型可以是一种标准通用的解决方案,因为传统的模型在遇到离散的类别特征时,一般都是想方设法将其连续化,如做Id Embedding等,而FFM模型原生支持处理稀疏的类别特征,而且擅长挖掘出特征间的交叉性质,不仅效果好而且时间复杂度也不高,因此具有较高的应用价值,在很多企业中有实际的应用。
本文以一阶模型作为引入,分析了为什么二阶模型是必要的,然后给出了具有实用性的二阶模型FM以及改良版的FFM,最后简要说明了一下FFM的实现思路。
1.从一阶Linear Model开始
假设我们有下图这样的推荐数据,对于第一行样本,我们用语言翻译:用户1在语境3下对物体2有一个点击行为(click=1);这里,用户(user),语境(context)和物体(item)都是特征,点击行为是label,我们要用一个模型去拟合这个label,使这个模型能够预测一个用户在某语境下对某物体的的点击率。最简单的模型为线性模型,即:
y = ∑ i ∈ C w i x i y= \sum_{i \in C} w_ix_i y=i∈C∑wixi
其中, C C C为各特征中的非零项索引的集合, x i x_i xi为非零项对应的值,由于这里都是类别特征(Category Feature),所以非零项 x i x_i xi等于1, w i w_i wi 为非零项对应的权值,是模型要学习的参数。我们把第一行数据带入式子得到图中的等式如下:

让我们分析一下线性模型的参数空间大小,假设我们一共只有10个用户,10种物体,10种语境,那么参数 W W W由三个向量组成: W u s e r W_{user} Wuser, W i t e m W_{item} Witem和 W c o n t e x t W_{context} Wcontext,每个向量的长度为10,向量中第 i i i个元素的取值代表对应权值 x i x_i xi,那么我们的参数空间一共是30。
这里只是一个最简单的例子,其实每个参数 x i x_i xi也可以用一个长度为 k k k的向量表示,那么 W u s e r W_{user} Wuser, W i t e m W_{item} Witem和 W c o n t e x t W_{context} Wcontext则分别为三个 10 × k 10 \times k 10×k的矩阵。
2. 二阶模型(Degree-2 Polynomial Model)
前面一阶线性模型的缺点是无法挖掘特征之间的相关性,各个特征参数都是独立学习,而往往特征之间是有关联的,例如用户在中秋节的时候更容易对月饼发生点击或者购买行为,此时语境是中秋节,物体是月饼,当这两个条件同时满足时,点击更有可能发生。为了考虑特征之间的相关性,我们有了二阶模型,简单的二阶模型是一阶模型的直接扩展:参数只有在任意两个特征同时取值时才确定。二阶模型的表达为:
y = ∑ j 1 , j 2 ∈ C w j 1 , j 2 x j 1 x j 2 y = \sum_{j_1,j_2 \in C} w_{j_1,j_2} x_{j_1}x_{j_2} y=j1,j2∈C∑wj1,j2xj1xj2
其中, C C C为任意两个特征中的非零项索引组合的集合,而 w j 1 . j 2 w_{j_1.j_2} wj1.j2是某两个特征的非零项索引同时为 j 1 j_1 j1和 j 2 j_2 j2时的参数。同样,我们把第一行数据带入二阶模型如下图:
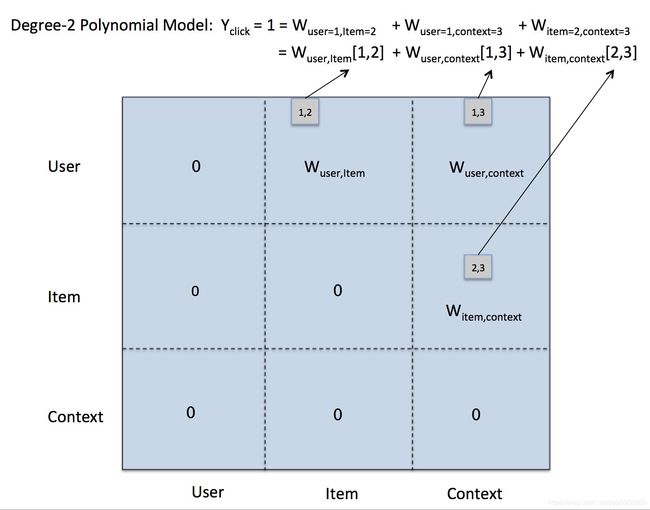
此时,二阶模型的参数扩展到了一个 N × N N \times N N×N的矩阵 W W W, N N N为所有特征取值空间的和,假设user,item,context都只有10个不同值,那么 N = 30 N=30 N=30,参数空间 N 2 = 900 N^2=900 N2=900。需要注意的是矩阵 W W W为一个对称矩阵,这是因为我们并不区分两个特征的取值顺序,如 W u s e r = 1 , i t e m = 2 = W i t e m = 2 , u s e = 1 W_{user=1,item=2}=W_{item=2,use=1} Wuser=1,item=2=Witem=2,use=1,这两个参数在矩阵中处于对称位置;而且同一特征的不同取值参数是没有意义的,如 W u s e r = 1 , u s e r = i , i ∈ N W_{user=1,user=i},i \in N Wuser=1,user=i,i∈N是不存在的,一个用户不可能存在着两种取值,因此 W W W矩阵中有一大半参数是无效的,如上图所示,我们把这些参数在矩阵中可以置为0,但是其参数空间复杂度仍然为 O ( N 2 ) O(N^2) O(N2)。
3. Factorization Machines (FM)
简单二阶模型的缺点是:
- 一个参数只有在两个特征同时取某数才会参与计算和更新,而对于不同的样本,要使两个特征的取值重复概率很小,导致 W W W中大部分的位置由于样本中从未出现过而得不到计算和更新。
- 在实际应用中,由于特征的取值有可能有几百万种,如用户的数量,导致 N N N非常大,使矩阵 W W W特别稀疏,去维护这样一个大矩阵储存开销太大。
为了解决这些问题,我们可以用类似矩阵分解的思路去解决:把矩阵 W W W分解成两个小矩阵,用这两个小矩阵的相乘结果 W ^ \hat W W^来近似 W W W。具体来说,每个矩阵的元素 w j 1 , j 2 w_{j_1,j_2} wj1,j2由两个向量 v j 1 v_{j_1} vj1和 v j 2 v_{j_2} vj2相乘表示,同样,我们用 C C C代表任意两个特征中的非零项组合的集合,因此,FM模型能被表示为:
y = ∑ j 1 , j 2 ∈ C ( v j 1 ⋅ v j 2 ) x j 1 x j 2 y = \sum_{j_1,j_2 \in C} (v_{j_1} \cdot v_{j_2}) x_{j_1} x_{j_2} y=j1,j2∈C∑(vj1⋅vj2)xj1xj2
3.1 为什么FM能够避免简单二阶模型中的第一个问题呢?
我们用同样的例子给出了一个FM的计算如下图,我们可以发现:向量 v u s e r = 1 v_{user=1} vuser=1在参数 W u s e r = 1 , i t e m = 2 W_{user=1,item=2} Wuser=1,item=2和 W u s e r = 1 , c o n t e x t = 3 W_{user=1,context=3} Wuser=1,context=3中都参与了计算,导致 v u s e r = 1 v_{user=1} vuser=1的更新条件变得宽松,只要是满足出现 W u s e r = 1 , i t e m / c o n t e x t W_{user=1,item/context} Wuser=1,item/context的, v u s e r = 1 v_{user=1} vuser=1都能随之参与计算和更新,这个向量其实就代表了关于用户1的特征表达(feature representation)或者画像(profile)。

3.2 为什么FM能够解决简单二阶模型中的空间复杂度问题呢
FM中,矩阵 W W W被拆分为了两个 N × k N \times k N×k矩阵相乘,因此参数空间为 2 × N × k 2 \times N \times k 2×N×k,但于 k k k通常很小,远小于N,而且是一个常数,因此其空间复杂度降为了 O ( N ) O(N) O(N)。这里的 k k k是一个超参数,控制着信息压缩后的保留的程度:较小的 k k k保留的信息少,但是计算快;较大的 k k k保留的信息多,虽然计算慢,但模型效果和精度较好。
3.3 为什么矩阵 W W W能够被拆解为两个小矩阵相乘呢?
为了回答这个问题,我们需要知道FM模型和矩阵分解之间的关系。我们知道,一个 N × N N \times N N×N的方阵可以被分解为它的特征向量与特征值矩阵: W = V Σ V T W=V\Sigma V^T W=VΣVT,其中 V V V是标准化的特征向量 v 1 , … , v N v_1,\dots, v_N v1,…,vN组成的 N × N N\times N N×N维矩阵,而 Σ \Sigma Σ是主对角线为特征值 λ 1 , … , λ N \lambda_1,\dots,\lambda_N λ1,…,λN的 N × N N \times N N×N维矩阵。FM在这里并没有采用所有的特征向量而是用了前 k k k个特征向量(按照特征值大小排列),通常情况下,前10%甚至前1%的特征值就能占据全部特征值之和的99%,因此FM分解出的 V V V矩阵( N × k N \times k N×k)计算出来的是真实 W W W的一种近似: W ≈ W ^ = V V T W \approx \hat W = V V^T W≈W^=VVT。
还有一个问题是 Σ \Sigma Σ去哪了呢?严格来说,FM的分解应该这么写 W ^ = V Σ ^ V T \hat W = V \hat \Sigma V^T W^=VΣ^VT,此时 Σ ^ \hat \Sigma Σ^是主对角线为前 k k k个特征值的 k × k k\times k k×k维矩阵,也是模型要学习的参数,其实乘以 Σ ^ \hat \Sigma Σ^可以看做是对特征向量的伸缩变换,并不会改变其向量方向(因为它是一个主对角线才有非零值的矩阵),因此每个特征向量经过了同样的伸缩变换后,其向量的相对位置并没有发生变化,相当于乘以了一个常数,所以最后计算出来的得分 y y y的相对大小不会发生变化。个人猜测:正是因为,有时候我们并不关心预测出来的点击率最大是多少(绝对值),而只关心哪个物体点击率最大(相对值),因此这个 Σ ^ \hat \Sigma Σ^经常被忽略
4. Field-aware Factorization Machines (FFM)
FM模型虽然有着不错的效果,但是在某种程度上来说它还是比较“粗糙”的。为什么呢?因为各向量的更新条件过于宽松,比如参数 W u s e r = 1 , i t e m = 2 W_{user=1,item=2} Wuser=1,item=2和 W u s e r = 1 , c o n t e x t = 3 W_{user=1,context=3} Wuser=1,context=3都会让 v u s e r = 1 v_{user=1} vuser=1参与计算和更新,这样有可能导致一个问题:若 W u s e r = 1 , c o n t e x t = 3 W_{user=1,context=3} Wuser=1,context=3出现的次数远大于 W u s e r = 1 , i t e m = 2 W_{user=1,item=2} Wuser=1,item=2,那么用户向量的更新基本上被 W u s e r = 1 , c o n t e x t = 3 W_{user=1,context=3} Wuser=1,context=3主导,而覆盖掉 W u s e r = 1 , i t e m = 2 W_{user=1,item=2} Wuser=1,item=2的更新。
出现这种情况的根本原因是由于各特征的取值分布不相同,这是我们无法避免的,那么一种改进版的FM可以解决这个问题:我们让向量的更新在特征间保持独立,具体来说,我们把 v u s e r = 1 v_{user=1} vuser=1拆分成 v u s e r = 1 , i t e m v_{user=1,item} vuser=1,item和 v u s e r = 1 , c o n t e x t v_{user=1,context} vuser=1,context两部分,当出现 W u s e r = 1 , i t e m = i , i ∈ N W_{user=1,item=i},i \in N Wuser=1,item=i,i∈N时,我们让 v u s e r = 1 , i t e m v_{user=1,item} vuser=1,item参与计算和更新;当出现 W u s e r = 1 , c o n t e x t = i , i ∈ N W_{user=1,context=i} ,i \in N Wuser=1,context=i,i∈N时,我们让 v u s e r = 1 , c o n t e x t v_{user=1,context} vuser=1,context这部分参与计算和更新,这样,关于这个用户向量的更新就在各个特征间独立开了,因此这个向量能够区分不同的特征,我们说它是Field-aware,这里的Filed就是指的特征,所以这个改进版方法就是Field-aware FM (FFM)。FFM的表达式为:
y = ∑ j 1 , j 2 ∈ C ( v j 1 , f 2 ⋅ v j 2 , f 1 ) x j 1 x j 2 y = \sum_{j_1,j_2 \in C} (v_{j_1,f_2}\cdot v_{j_2,f_1}) x_{j_1}x_{j_2} y=j1,j2∈C∑(vj1,f2⋅vj2,f1)xj1xj2
其中, v j 1 , f 2 v_{j_1,f_2} vj1,f2是 v j 1 v_{j_1} vj1向量中与特征 v j 2 v_{j_2} vj2向量交叉的那部分,下图给出了FFM模型计算的例子:

假设数据集中一共有M个特征,FFM把FM的参数空间扩展了 M − 1 M-1 M−1倍,因为此时的 V V V矩阵为 N × ( M − 1 ) k N \times (M-1)k N×(M−1)k维。在上图中,由于我们一共只有3域特征(用户,语境,物体),每个向量只需要拆分成两块分别于与其他两域特征交叉即可,若每块向量长度为k,那么 V V V矩阵的维度为 N × 2 k N \times 2k N×2k,参数空间是FM的两倍。
5.FFM 实现思路
无论是一阶、二阶、FM和FFM模型,其模型更新都可以使用梯度下降法,它的结构更像一个二维的一层神经网络,每次正向传播只有少部分非零的交叉特征所在的神经元是激活状态,反向传播的时候也只有这些激活的神经元参数得到更新。与标准的神经网络更新一样,对于回归任务,损失函数选用平方差误差;对于分类任务,选用交叉熵损失函数。
有了前面的介绍,我们已经知道了FFM的基本原理,那么如何进行高效地实现呢?其实非常简单,我们只需要维护一张非常大的哈希表,hash_key = feature_id + feature_value,对应的hash_value= weight_vector,其中,feature_id为特征所在的id,feature_value为此特征的值,举个例子,对于 v u s e r = 12 , i t e m v_{user=12,item} vuser=12,item,假设user特征id=12,此时的key为hash后的112(前面的1表示的是user特征,后面的12表示的是用户的id值),我们通过这个key在表中查到对应的权值向量,然后在这个向量中取出与item特征交叉的那部分向量即为 v u s e r = 1 , i t e m v_{user=1,item} vuser=1,item。
Reference
https://www.csie.ntu.edu.tw/~r01922136/slides/ffm.pdf
https://zhuanlan.zhihu.com/p/31386807
https://tech.meituan.com/2016/03/03/deep-understanding-of-ffm-principles-and-practices.html