同程旅游缓存系统(凤凰)打造Redis时代的完美平台实践
声明:本文来自《程序员》2017年2月期,未经授权禁止转载。
作者:王晓波,同程旅游首席架构师。专注于高并发互联网架构设计、分布式电子商务交易平台设计、大数据分析平台设计、高可用性系统设计,基础云相关技术研究,对 Docker 等容器有深入的实践。另对系统运维和信息安全领域也大量的技术实践。曾设计过多个并发百万以上、每分钟 20 万以上订单量的电商交易平台,熟悉 B2C、B2B、B2B2C、O2O 等多种电商形态系统的技术设计。 熟悉电子商务平台技术发展特点,拥有十多年丰富的技术架构、技术咨询经验,深刻理解电商系统对技术选择的重要性。
责编:钱曙光,关注架构和算法领域,寻求报道或者投稿请发邮件[email protected],另有「CSDN 高级架构师群」,内有诸多知名互联网公司的大牛架构师,欢迎架构师加微信qianshuguangarch申请入群,备注姓名+公司+职位。
缓存大家比较熟悉,在各种场景下也用的很多,在同程旅游也一样,缓存是一个无处不在的精灵,也是抗并发压力的核心系统之一。今天我们来讲一下同程旅游在缓存方面的一些经验,包括整个缓存架构如何设计。先来看一下缓存我们走过了哪些历程。最早我们在应用中使用内存对象来存放变化比较小数据,慢慢的发现在应用本地的内存量是不足以这样折腾的是精贵的,所以开始使用从 memcache 来将缓存从应用中分离出来。之后缓存的场景变的更多了,memcache的一些不足之处开始显现,如支持的数据结构有单一等。于是又开始使用Redis,对于Redis的使用也从单机开始转向分片/集群的方式。Redis虽然是一个非常优秀的缓存中间件系统但当应用的使用量越来越多时发现新的问题也来了,首先是对于在应用代码在一起的Redis客户端不是太满意了,于是我们重写了客户端。接着在数千个Redis实例(目前我们线上有4千多个部署实例)在线上工作起来如何底成本的高效的运维起是一个大挑战。于是我们做了针对他的智能化运维平台。但是这些多不是重大的难题,最大难题是因为Redis太好用了于致于在应用项目中大量的使用,但是往往这些是没有好好的思考和设计过的,这样情况使的缓存的使用是混乱的不合理的,也使的原本健壮的缓存变的脆弱的病秧子。所以我们开始做了开发 Redis 调度治理系统来治理缓存。到现在我们开始更加关注整个缓存平台的高效和低成本所以在平台的Redis 部署全面 Docker 化,并开始让比内存廉价的ssd硬盘在缓存中使用起来。
现在让我们来看一看这个名叫“凤凰”的缓存平台是怎么从火中重生的。
一、Redis 遍地开花的现状及问题
1. Redis 集群的管理
所有互联网的应用里面,可能访问最多的就是 cache。一开始时候一些团队认为 cache 就像西游记里仙丹一样,当一个系统访问过大扛不住时,用一下 Redis,系统压力就解决了。在这种背景下,我们的系统里面 Redis 不断增多,逐渐增加到几百台服务器,每台上面还有多个实例,因此当存在几千个 Redis 实例后,使用者也很难说清楚哪个 Redis在哪个业务的什么场景下影响什么功能。
2. 故障
这种背景下会存在什么样痛苦的场景?正常情况下 cache 是为了增加系统的性能,是画龙点睛的一笔,但是当时我们 cache 会是什么样?它挂了就可能让我们整个系统崩溃。比如说 系统压力才不到高峰时的 10%,也许就由于缓存问题系统就挂了,又比如系统的访问量不大,但某个缓存被调用到爆了,因为缓存的乱用后调用量被放大了。
3. 高可用与主从同步问题
因为 cache 有单点,我们一开始想放两份不就好了吗,所以就做了主从。这时候坑又来了,为什么呢?比如有些 Redis 实例中的某个键值非常大(在乱的场景下我见到过有人一个键值放到10G的)。在当偶尔网络质量不太好时候,就会带来主从同步基本就别想了,更坑的是当两边主和从都死或者出问题的时,重启的时间非常长。
4. 监控
为了高可用,我们需要全面的监控。当时我们做了哪些监控呢?其实是能做的监控我们多做了,但问题没有解决,细想来问题到底在哪?
下面是一个接近真实场景运维与开发的对话场景。
- 开发:Redis 为啥不能访问了?
- 运维:刚刚服务器内存坏了,服务器自动重启了
- 开发:为什么 Redis 延迟这么大?
- 运维:不要在 Zset 里放几万条数据,插入排序会死人啊
- 开发:写进去的 key 为什么不见了?
- 运维:Redis 超过最大大小了啊,不常用 key 都丢了啊
- 开发:刚刚为啥读取全失败了
- 运维:网络临时中断了一下,从机全同步了,在全同步完成之前,从机的读取全部失败
- 开发:我需要 800G 的 Redis,什么时候能准备好?
- 运维:线上的服务器最大就 256G,不支持这么大
- 开发:Redis 慢得像驴,服务器有问题了?
- 运维:千万级的 KEY,用 keys*,慢是一定了。
看到这样的一个场景很吃惊,我们怎么在这样用缓存,因此我们一个架构师最后做了以下总结
“从来没想过,一个小小的 Redis 还有这么多新奇的功能。就像在手上有锤子的时候,看什么都是钉子。渐渐的,开发规范倒是淡忘了,新奇的功能却接连不断的出现了,基于 Redis 的分布式锁、日志系统、消息队列、数据清洗等,各种各样的功能不断上线,从而引发各种各样的问题。运维天天疲于奔命,到处处理着 Redis 堵塞、网卡打爆、连接数爆表……”
总结了一下,我们之前的缓存存在哪些问题?
- 使用的者的乱用、烂用、懒用。
- 运维一个几百台毫无规则的服务器
- 运维不懂开发,开发不懂运维
- 缓存在无设计无控制中被使用
- 开发人员能力各不相同
- 使用太多的服务器
- 懒人心理(应对变化不够快)
二、我们需要一个什么样的完美缓存系统?
我相信上面这些情况在很多大量使用 Redis 的团队中都存在,如果发展到这样一个阶段后,我们到底需要一个什么样的缓存?
我们给自己提出几个要点:
- 服务规模:支持大量的缓存访问,应用对缓存大少需求就像贪吃蛇一般
- 集群可管理性:一堆孤岛般的单机服务器缓存服务运维是个迷宫
- 冷热区分:现在缓存中的数据许多并不是永远的热数据
- 访问的规范及可控:还有许多的开发人员对缓存技术了解有限,胡乱用的情况很多
- 在线扩缩容:起初估算的不足到用时发现瓶颈了
这个情况下,我们考虑这样的方案是不是最好。本来我们是想直接使用某个开源方案就解决了,但是我们发现每个开源方案针对性的解决 Redis 上述痛点的某一些问题,每一个方案在评估阶段跟我们需求都没有 100% 匹配。每个开源方案本身都很优秀,也许只是说我们的场景的特殊性,没有任何否定的意思。
下面我们当时评估的几个开源方案,看一下为什么当时没有引入。
- CacheCloud:跟我们需要的很像,它也做了很多的东西,但是它对我们不满足是部署方案不够灵活,对运维的策略少了点。
- Codis:这个其实很好,当年我们已经搭好了准备去用了,后来又下了,因为之前有一个业务需要 800G 内存,后来我们发现这个大集群有一个问题,因为用得不是很规范,如果在这种情况下给他一个更大的集群,那我们可能死的机率更大,所以我们也放弃了。另外像这个800G 也很浪费,并不完全都是热数据,我们想把它存到硬盘上一部分,很多业务使用方的心理是觉得在磁盘上可能会有性能问题,还是放在 Redis 放心一点,其实这种情况基本不会出现,因此我们需要一定的冷热区分支持。
- Pika: Pika 可以解决上面的大量数据保存在磁盘的问题,但是它的部署方案少了点,而且 Pika 的设计说明上也表示主要针对大的数据存储。
- Twemproxy:最后我们想既然直接方案不能解决,那可以考虑代理治理的方式,但是问题是它只是个代理,Redis 被滥用的问题还是没有真正的治理好,所以后面我们准备自己做一个。
三、全新设计的缓存系统——凤凰
我们新系统起了一个比较高大上的名字,叫凤凰,愿景是凤凰涅磐,从此缓存不会再死掉了。那么,凤凰是怎么设计的?(如:图1)
主要是做好了下面的几件事:
- 在应用中能根据场景拆分(应用透明)
- 能从客户端调用开始全面监控
- 能防止缓存的崩塌
- 动态扩容缩容

1. 自定义客户端方式与场景配置能力
在支持 Redis 本身的特性的基础上,我们需要通过自定义的客户端来实现一些额外的功能。
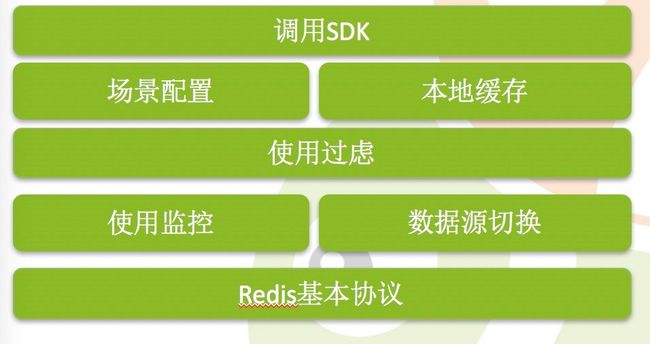
支持场景配置,我们考虑根据场景来管控它的场景,客户端每次用 Redis 的时候,必须把场景上报给我,你是在哪里,用这件事儿是干什么的,虽然这个对于开发人员来说是比较累的,他往往嵌在它的任务逻辑里面直接跟进去。曾江场景配置之后,在缓存服务的中心节点,就可以把它分开,同一个应用里面两个比较重要的场景就会不用同一个 Redis,避免挂的时候两个一起挂。
同时也需要一个调度系统,分开之后,不同的 Redis 集群所属的服务器也需要分开。分开以后我的数据怎么复制,出问题的时候我们怎么把它迁移?因此也需要一个复制和迁移的平台去做。
另外这么一套复杂的东西出来之后,需要一个监控系统;客户端里也可以增加本地 cache 的支持。在业务上也可能需要对敏感的东西进行过滤。在底层,可以自动实现对访问数据源的切换,对应用是透明的,应用不需要关心真正的数据源是什么,这就是我们自己做的客户端。(如:图2)
2. 代理层方式
客户端做了之后还发生一个问题,很多情况下很难升级客户端。再好的程序员写出来的东西还是有 bug,如果 Redis 组件客户端发现了一个 bug 需要升级,但我们线上有几千个应用分布在多个业务开发团队,这样导致很难驱动这么多开发团队去升级。另外一个我们独有的困难,就是我们还有一些很老的应用开发时用的 .net,这些虽然现在基本是边缘应用了但还在线上,当然我们也把客户端实现了 .net 版本,但是由于各种原因,要推动这么多历史业务进行改造切换非常麻烦,甚至有些特别老的业务最后没法升级。另外我们也推进其(如:go等)其它语言的应用想让技术的生态做的更丰富。这样一来我们做维护更多语言的客户端了,这样的方式明显不合适。
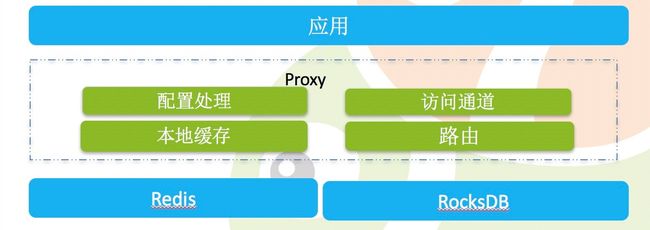
因此我们考虑了 proxy 方案,这些业务模块不需要修改代码,我们的想法就是让每一个项目的每一个开发者自己开发的代码是干净的,不要在他的代码里面嵌任何的东西,业务访问的就是一个 Redis。那么我们就做了,首先它是 Redis 的协议,接下来刚才我们在客户端里面支持的各种场景配置录在 proxy 里面,实现访问通道控制。然后再把 Redis 本身沉在我们 proxy 之后,让它仅仅变成一个储存的节点,proxy 再做一些自己的事情,比如本地缓存及路由。冷热区分方面,在一些压力不大的情况下,调用方看到的还是个 Redis ,但是其实可能数据是存在 RocksDB 里面了。(如:图3)
3. 缓存服务的架构设计
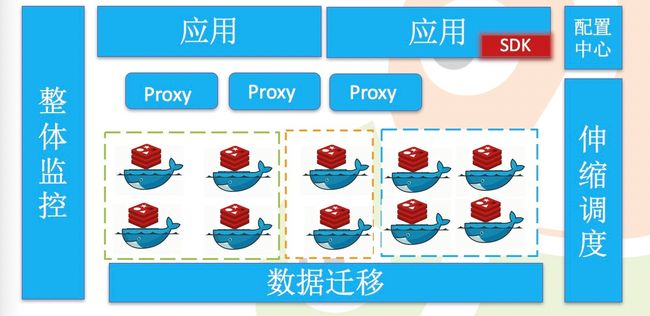
- 多个小集群 + 单节点,我们要小集群的部署和快速的部署,到当时一个集群有问题的时候,快速移到另一个集群。
- 以场景划分集群
- 实时平衡调度数据
- 动态扩容缩容
4. 可扩容能力
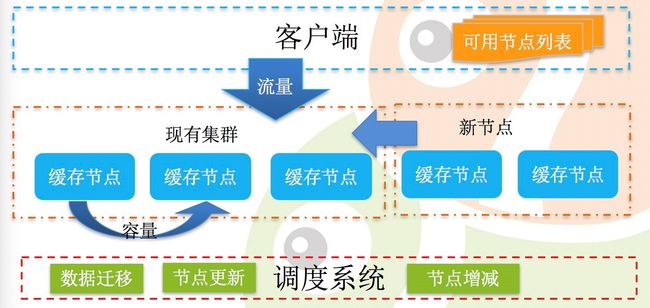
- 流量的快速增加必然带扩容的需求与压力
- 容量与流量的双扩容
- 如何做到平滑的扩容?容量动态的数据迁移(集群内部平衡,新节点增加);流量超出时的根据再平衡集群。
5. 多协议支持
还有一块老项目是最大的麻烦,同程有很多之前是用 memcache 的应用,后来是转到 Redis 去的,但是转出一个问题来了,有不少业务由于本身事情较多,没有时间转换成 Redis,这些钉子户怎么办?同时维护这两个平台是非常麻烦的,刚才 proxy 就派到用场了。因为 memcache 本身它的数据支持类型是比较少的,因此转换比较简单,如果是一个更复杂的类型,那可能就转不过来了。所以我们 proxy 就把这些钉子户给拆掉了,他觉得自己还是在用 memcache,其实已经被转成了 Redis。

6. 管理与可监控能力
最后一块,我们这样一个平台怎么去监控它,和怎么去运维它?
在这块我们更多的是在做一个智能化的运维平台。主要的几点方向:
- 整体的管制平台,
- 运维操作平台,让它可以去操作,动态的在页面上操作做一件事情,
- 整体监控平台。我们从客户端开始,到服务器的数据,全部把它监控起来。
- 自扩容自收缩。动态的自扩容,自收缩。
7. 一些业务应用场景
也是用了一些场景,比如说同程前两年冲的比较狠的就是一元门票,大家肯定说抢购,这个最大的压力是什么,早上的九点半,这是我们系统最大的压力,为什么呢,一块钱的门票的从你买完票到景区里面去,这件事情是在九点半集中爆发的,你要说这个是系统挂了入不了园了,那十几万人不把这个景区打砸了才怪。那个时候系统绝对不能死。抢购没有关系,入园是我们最大的压力,
我们是靠新的系统提供了访问能力及可用性的支持,把类似这种场景支撑下来,其实缓存本身是可以支撑住的,但是如果滥用管理失控,可能碰到这种高可用的需求就废了。
还有一个是火车票系统,火车票查询量非常大,我们这主要是用了新系统的收缩容,到了晚上的时候查的人不多了,到了早上的时候特别多,他查询量是在一个高低跌荡的,所以我们可以根据访问的情况来弹性调度。
编辑推荐:架构技术实践系列文章(部分):
- 章耿:服务化框架技术选型实践
- 赵琨:视频直播早期创业团队的技术架构与选型
- 卢誉声:分布式实时处理系统架构设计与机器学习实践
- 陈斌:架构师的必备素质和成长途径
- 林伟:高可用的大数据计算平台如何持续发布和演进
- 柳宗扬:蘑菇街直播实战技巧带你解决直播开发难题
- 胡骏:详解自动化运维平台的构建过程
- 黄日成:从UDP的连接性说起——告知你不为人知的UDP
- 林昊:阿里超大规模Docker化之路
- 罗金鹏:双11媒体大屏背后的数据技术与产品
- 袁岳峰:手机端创新体验——手把手教你搭建VR&AR架构
- 张铭:双11背后的网络自动化技术
- 王鹤:Vue.js 2.0源码解析之前端渲染篇
- 黄日成:从TCP三次握手说起–浅析TCP协议中的疑难杂症
- 厉心刚:JavaScript引擎分析
- 蓝邦珏:来看看机智的前端童鞋怎么防盗
- 陈志兴:让页面滑动流畅得飞起的新特性:Passive Event Listeners
- 唐聪:大规模排行榜系统实践及挑战
- 左明:半小时深刻理解React
- 王照辉:魅族自动化测试架构之路
- 翁宁龙:美团数据库运维自动化系统构建之路
- 何轼:美团外卖订单中心的演进
- 申政:唯品会多线程Redis设计与实现
- 阿刘:千万级用户的Android客户端是如何养成的
- 卜赫:大道至简——React Native在直播应用中的实践
- 陈爱珍:从运维的角度看微服务和容器
- 孙其瑞:VR应用在直播领域上的实践与探索
- 刘丁:bilibili高并发实时弹幕系统的实战之路
- 秦鹏:从应用到平台,云服务架构的演进过程
- 郭炜:从0到N建立高性价比的大数据平台
- 李智慧:宅米网技术变迁——初创互联网公司的技术发展之路
- 陶文质:分布式系统设计的求生之路
- 魏晓军:React Native实践之携程Moles框架
- 学霸君姜波:耳目一新的在线答疑服务背后的核心技术
- 爱乐奇麦凯臻:在线教育的内容研发和技术的迭代创新
- 长虹李玮:老牌消费电子企业如何拥抱Docker
- 徐汉彬:日请求过亿的Web系统PHP7升级实践
- 窦威:AcFun的视频架构演化实践
- 傅鸿城:QQ亿级日活跃业务后台核心技术揭秘
- 宁峰峰:尖峰日96万订单,59校园狂欢节技术架构剖析
- 梁阳鹤:每秒处理10万订单乐视集团支付架构
- 沈辉煌:亿级日PV的魅族云同步的核心协议与架构实践
- 李任:携程Docker最佳实践
- 王海军:游戏研发与运营环境Docker化
- 史海峰:当当网高可用架构之道
- 黄哲铿:应对电商大促峰值的九个方法
- 1号店交易系统架构如何向「高并发高可用」演进
- 京东闫国旗:从C10K到C10M高性能网络的探索与实践
- 李林锋:服务化架构的演进与实践
- 1号店架构师王富平:一号店用户画像系统实践
- 唯品会官华:实现电商平台从业务到架构的治理体系
- 沈剑:58同城数据库架构最佳实践
- 荔枝FM架构师刘耀华:异地多活IDC机房架构
- UPYUN的云CDN技术架构演进之路
- 初页CTO丁乐:分布式以后还能敏捷吗?
- 陈科:河狸家运维系统监控系统的实现方案
- 途牛谭俊青:多数据中心状态同步&两地三中心的理论
- 云运维的启示与架构设计
- 魅族多机房部署方案
- 艺龙十万级服务器监控系统开发的架构和心得
- 京东商品详情页应对“双11”大流量的技术实践
- 架构师于小波:魅族实时消息推送架构