哈希算法乱谈(摘自知乎)
最近初步了解了Hash算法的相关知识,一些人的见解让我能够迅速的了解相对不熟悉的知识,故想摘录下来,供以后温故而知新。
文章连接:https://www.zhihu.com/question/20820286
HASH算法是密码学的基础,比较常用的有MD5和SHA,最重要的两条性质,就是不可逆和无冲突。
所谓不可逆,就是当你知道x的HASH值,无法求出x;
所谓无冲突,就是当你知道x,无法求出一个y, 使x与y的HASH值相同。
这两条性质在数学上都是不成立的。因为一个函数必然可逆,且由于HASH函数的值域有限,理论上会有无穷多个不同的原始值,它们的hash值都相同。MD5和SHA做到的,是求逆和求冲突在计算上不可能,也就是正向计算很容易,而反向计算即使穷尽人类所有的计算资源都做不到。
我觉得密码学的几个算法(HASH、对称加密、公私钥)是计算机科学领域最伟大的发明之一,它授予了弱小的个人在强权面前信息的安全(而且是绝对的安全)。举个例子,只要你一直使用https与国外站点通讯,并注意对方的公钥没有被篡改,G**W可以断开你的连接,但它永远不可能知道你们的传输内容是什么。
顺便说一下,王小云教授曾经成功制造出MD5的碰撞,即md5(a) = md5(b)。这样的碰撞只能随机生成,并不能根据一个已知的a求出b(即并没有破坏MD5的无冲突特性)。但这已经让他声名大噪了。
就是空间映射函数,例如,全体的长整数的取值作为一个取值空间,映射到全部的字节整数的取值的空间,这个映射函数就是HASH函数。通常这种映射函数是从一个非常大的取值空间映射到一个非常小的取值空间,由于不是一对一的映射,HASH函数转换后不可逆,即不可能通过逆操作和HASH值还原出原始的值,受到计算能力限制(注意,不是逻辑上不可能,前面的不可能是逻辑上的)而且也无法还原出所有可能的全部原始值。HASH函数运用在字典表等需要快速查找的数据结构中,他的计算复杂度几乎是O(1),不会随着数据量增加而增加。另外一种用途就是文件签名,文件内容很多,将文件内容通过HASH函数处理后得到一个HASH值,验证这个文件是否被修改过,只需要把文件内容用同样的HASH函数处理后得到HASH值再比对和文件一起传送的HASH值即可,如不公开HASH算法,那么信道是无法篡改文件内容的时候篡改文件HASH值,一般应用的时候,HASH算法是公开的,这时候会用一个非对称加密算法加密一下这个HASH值,这样即便能够计算HASH值,但没有加密密钥依然无法篡改加密后HASH值。这种算法用途很广泛,用在电子签名中。HASH算法也可进行破解,这种破解不是传统意义上的解密,而是按照已有的HASH值构造出能够计算出相同HASH值的其他原文,从而妨碍原文的不可篡改性的验证,俗称找碰撞。这种碰撞对现有的电子签名危害并不严重,主要是要能够构造出有意义的原文才有价值,否则就是构造了一个完全不可识别的原文罢了,接收系统要么无法处理报错,要么人工处理的时候发现完全不可读。理论上我们终于找到了在可计算时间内发现碰撞的算法,推算了HASH算法的逆操作的时间复杂度大概的范围。
HASH算法的另外一个很广泛的用途,就是很多程序员都会使用的在数据库中保存用户密码的算法,通常不会直接保存用户密码(这样DBA就能看到用户密码啦,好危险啊),而是保存密码的HASH值,验证的时候,用相同的HASH函数计算用户输入的密码得到计算HASH值然后比对数据库中存储的HASH值是否一致,从而完成验证。由于用户的密码的一样的可能性是很高的,防止DBA猜测用户密码,我们还会用一种俗称“撒盐”的过程,就是计算密码的HASH值之前,把密码和另外一个会比较发散的数据拼接,通常我们会用用户创建时间的毫秒部分。这样计算的HASH值不大会都是一样的,会很发散。最后,作为一个老程序员,我会把用户的HASH值保存好,然后把我自己密码的HASH值保存到数据库里面,然后用我自己的密码和其他用户的用户名去登录,然后再改回来解决我看不到用户密码而又要“偷窥”用户的需要。最大的好处是,数据库泄露后,得到用户数据库的黑客看着一大堆HASH值会翻白眼。
哈希算法又称为摘要算法,它可以将任意数据通过一个函数转换成长度固定的数据串(通常用16进制的字符串表示),函数与数据串之间形成一一映射的关系。
举个粒子,我写了一篇小说,摘要是一个string:'关于甲状腺精灵的奇妙冒险',并附上这篇文章的摘要是'2d73d4f15c0db7f5ecb321b6a65e5d6d'。如果有人篡改了我的文章,并发表为'关于JOJO的奇妙冒险',我可以立即发现我的文章被篡改过,因为根据'关于JOJO的奇妙冒险'计算出的摘要不同于原始文章的摘要。
可见,摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
那~~有没有可能两个不同的数据通过某个摘要算法得到了相同的摘要呢?完全有可能!因为任何摘要算法都是把无限多的数据集合映射到一个有限的集合中。这种情况称为碰撞。
一个好的哈希算法中,应该存在大量不同的数据串,因此碰撞这种情况极其罕见。
哈希音译自“Hash”,又名为“散列”。本质上是一种计算机程序,可接收任意长度的信息输入,然后通过哈希算法,创建小的数字“指纹”的方式。例如数字与字母的结合,输出的就为“哈希值”。从数学术语上说,就是这个哈希函数,是将任意长度的数据,映射在有限长度的域上。总体而言,哈希函数用于,将消息或数据压缩,生成数据摘要,最终使数据量变小,并拥有固定格式。
那么哈希算法的作用又是什么呢?
(1) 在庞大的数据库中,由于哈希值更为短小,被找到更为容易,因此,哈希使数据的存储与查询速度更快;
(2) 哈希能对信息进行加密处理,使得数据传播更为安全。
哈希算法解决了什么生活问题?
看似深奥的数学函数,又或是计算机程序的哈希算法,其实跟我们的生活息息相关。就拿每年双十一的快递来说,实际上,哈希算法原理提高了快递入库出库的速度。为什么呢?
双十一一过,大家剁手后,一定收快递收到手软,手机短信抖个不停。这个时间段,双十一快递员可能没时间挨家挨户送上门,而是选择往驿站一扔。当驿站将快递入库后,你的手机会收到这样一条信息——

大家重点看看这个取货码:A10-8-9856。这可不是一堆乱码,这串数值,就是驿站员能快速找到你快递的关键。
A10指的是货架编码,8指的是第8层,9856指的是订单后四位。因此每个驿站小哥只需要瞄一眼,就能瞬间知道快递所在位置了。

因此,哈希算法最核心的用处,就是高速存取。在区块链技术中,它才能真正大展身手。以下是哈希算法在区块中的具体作用:
(1) 快速验证。只需要验证摘要,就能比较两个数据是否相等;
(2) 防止篡改。只需要传递数据的摘要即可传递该数据,并防止在传递过程中被篡改;
(3) 用于POW共识算法工作量证明。目前比特币和以太坊都使用POW共识机制。
哈希算法有千千万万种,其中,“安全哈希算法”(SHA 256)是保护数字信息最安全的方式之一。它是由美国国安局设计、美国国家标准与技术研究院发布的一套哈希算法。其摘要长度是256bits,因此被称为“SHA256”。它们都在网络数据和区块链技术应用中有着重大作用,也是理解区块链的重要一环。
用动画的形式写了一篇科普性的介绍哈希表的文章。
散列表
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
散列函数
散列函数,顾名思义,它是一个函数。如果把它定义成 hash(key) ,其中 key 表示元素的键值,则 hash(key) 的值表示经过散列函数计算得到的散列值。
散列函数的特点:
1.确定性
如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
2.散列碰撞(collision)
散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的,但也可能不同。
3.不可逆性
一个哈希值对应无数个明文,理论上你并不知道哪个是。
“船长,如果一样东西你知道在哪里,还算不算丢了。”
“不算。”
“好的,那您的酒壶没有丢。”
4.混淆特性
输入一些数据计算出散列值,然后部分改变输入值,一个具有强混淆特性的散列函数会产生一个完全不同的散列值。
常见的散列函数
1. MD5
MD5 即 Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致。是计算机广泛使用的杂凑算法之一,主流编程语言普遍已有 MD5 实现。
将数据(如汉字)运算为另一固定长度值,是杂凑算法的基础原理,MD5 的前身有 MD2 、MD3 和 MD4 。
MD5 是输入不定长度信息,输出固定长度 128-bits 的算法。经过程序流程,生成四个32位数据,最后联合起来成为一个 128-bits 散列。
基本方式为,求余、取余、调整长度、与链接变量进行循环运算,得出结果。
MD5 计算广泛应用于错误检查。在一些 BitTorrent 下载中,软件通过计算 MD5 来检验下载到的碎片的完整性。

2. SHA-1
SHA-1(英语:Secure Hash Algorithm 1,中文名:安全散列算法1)是一种密码散列函数,SHA-1可以生成一个被称为消息摘要的160位(20字节)散列值,散列值通常的呈现形式为40个十六进制数。
SHA-1 曾经在许多安全协议中广为使用,包括TLS和SSL、PGP、SSH、S/MIME和IPsec,曾被视为是MD5的后继者。
散列冲突
理想中的一个散列函数,希望达到
如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
这种效果,然而在真实的情况下,要想找到一个不同的 key 对应的散列值都不一样的散列函数,几乎是不可能的,即使是 MD5 或者 由美国国家安全局设计的 SHA-1 算法也无法实现。
事实上,再好的散列函数都无法避免散列冲突。
为什么呢?
这涉及到数学中比较好理解的一个原理:抽屉原理。
抽屉原理:桌上有十个苹果,要把这十个苹果放到九个抽屉里,无论怎样放,我们会发现至少会有一个抽屉里面至少放两个苹果。这一现象就是我们所说的“抽屉原理”。

对于散列表而言,无论设置的存储区域(n)有多大,当需要存储的数据大于 n 时,那么必然会存在哈希值相同的情况。这就是所谓的散列冲突。

那应该如何解决散列冲突问题呢?
常用的散列冲突解决方法有两类,开放寻址法(open addressing)和链表法(chaining)。
开放寻址法
定义:将散列函数扩展定义成探查序列,即每个关键字有一个探查序列h(k,0)、h(k,1)、…、h(k,m-1),这个探查序列一定是0….m-1的一个排列(一定要包含散列表全部的下标,不然可能会发生虽然散列表没满,但是元素不能插入的情况),如果给定一个关键字k,首先会看h(k,0)是否为空,如果为空,则插入;如果不为空,则看h(k,1)是否为空,以此类推。
开放寻址法是一种解决碰撞的方法,对于开放寻址冲突解决方法,比较经典的有线性探测方法(Linear Probing)、二次探测(Quadratic probing)和 双重散列(Double hashing)等方法。
线性探测方法
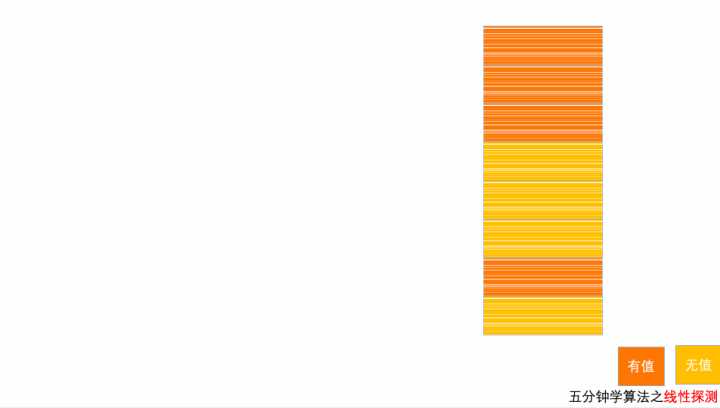
当我们往散列表中插入数据时,如果某个数据经过散列函数散列之后,存储位置已经被占用了,我们就从当前位置开始,依次往后查找,看是否有空闲位置,直到找到为止。
以上图为例,散列表的大小为 8 ,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了 4 个元素。此时元素 7777777 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。
于是按顺序地往后一个一个找,看有没有空闲的位置,此时,运气很好正巧在下一个位置就有空闲位置,将其插入,完成了数据存储。
线性探测法一个很大的弊端就是当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。极端情况下,需要从头到尾探测整个散列表,所以最坏情况下的时间复杂度为 O(n)。

二次探测方法
二次探测是二次方探测法的简称。顾名思义,使用二次探测进行探测的步长变成了原来的“二次方”,也就是说,它探测的下标序列为 hash(key)+0,hash(key)+1^2或[hash(key)-1^2],hash(key)+2^2或[hash(key)-2^2]。
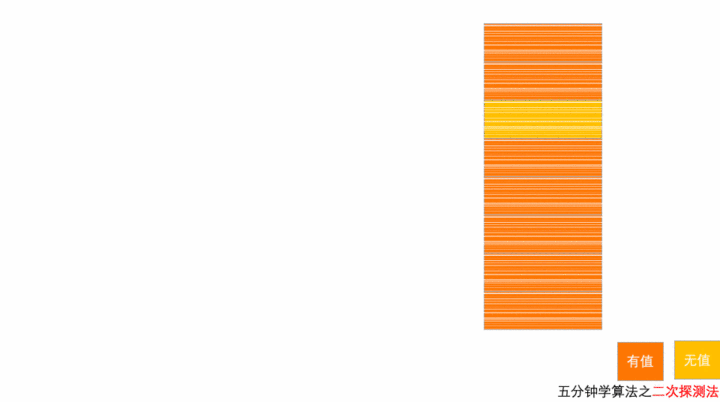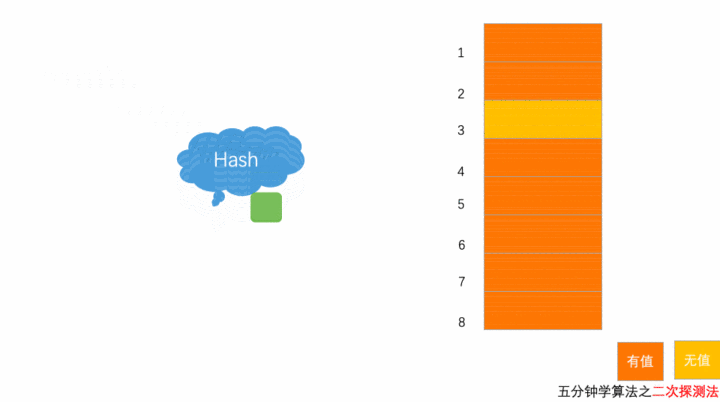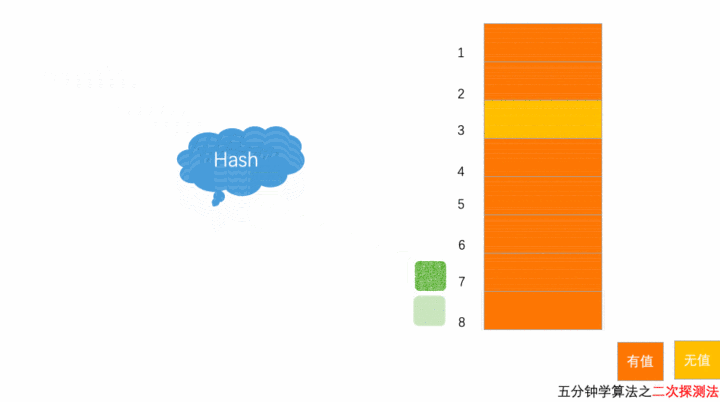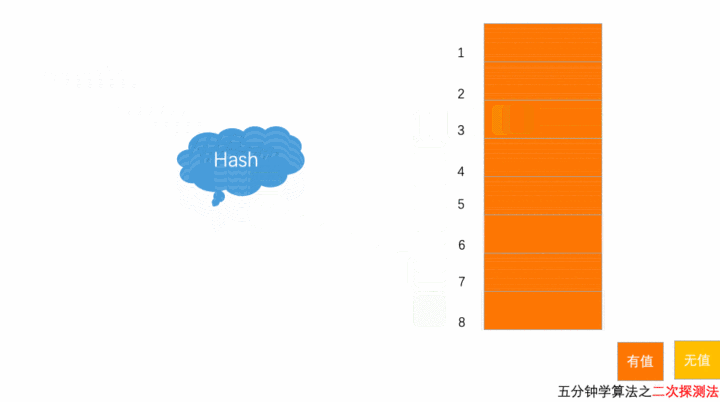
以上图为例,散列表的大小为 8 ,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了 7 个元素。此时元素 7777777 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。
按照二次探测方法的操作,有冲突就先 + 1^2,8 这个位置有值,冲突;变为 - 1^2,6 这个位置有值,还是有冲突;于是 - 2^2, 3 这个位置是空闲的,插入。
双重散列方法
所谓双重散列,意思就是不仅要使用一个散列函数,而是使用一组散列函数 hash1(key),hash2(key),hash3(key)。。。。。。先用第一个散列函数,如果计算得到的存储位置已经被占用,再用第二个散列函数,依次类推,直到找到空闲的存储位置。

以上图为例,散列表的大小为 8 ,黄色区域表示空闲位置,橙色区域表示已经存储了数据。目前散列表中已经存储了 7 个元素。此时元素 7777777 经过 Hash 算法之后,被散列到位置下标为 7 的位置,但是这个位置已经有数据了,所以就产生了冲突。
此时,再将数据进行一次哈希算法处理,经过另外的 Hash 算法之后,被散列到位置下标为 3 的位置,完成操作。
事实上,不管采用哪种探测方法,只要当散列表中空闲位置不多的时候,散列冲突的概率就会大大提高。为了尽可能保证散列表的操作效率,一般情况下,需要尽可能保证散列表中有一定比例的空闲槽位。
一般使用加载因子(load factor)来表示空位的多少。
加载因子是表示 Hsah 表中元素的填满的程度,若加载因子越大,则填满的元素越多,这样的好处是:空间利用率高了,但冲突的机会加大了。反之,加载因子越小,填满的元素越少,好处是冲突的机会减小了,但空间浪费多了。
链表法
链表法是一种更加常用的散列冲突解决办法,相比开放寻址法,它要简单很多。如下动图所示,在散列表中,每个位置对应一条链表,所有散列值相同的元素都放到相同位置对应的链表中。

小结:只是摘录我自己人为比较好的评论,哈希算法最核心的用处,就是高速存取。可以类比字典、快递方面的事情。