python运用正则表达式进行数据处理
上一篇:爬虫篇
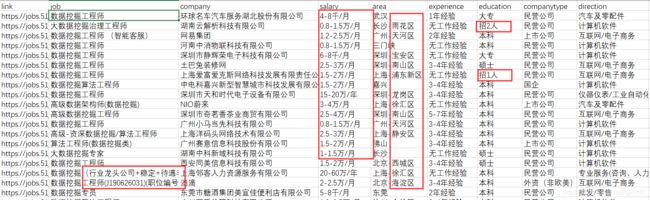
待处理数据集
处理后数据集
正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。——百度百科
现在我们处理一下之前所获得的招聘数据,想达到的目标如下:
1.去掉职位中的括号及集中内容
2.薪酬的格式不易统计,改成统一单位,并分割成最低薪酬与最高薪酬
3.将地区去掉区级单位,以便可视化统计
4.将学历要求中的招**人统一改为无学历要求
1.去掉职位中的括号及集中内容
def get_position(position):
#str1 = '数据挖掘工程师(J190626031) (职位编号:J190626031)'处理
#去掉制表符
temp1= re.sub('\t', '', position)
#去掉括号中的内容,英文的括号要加反斜杠
temp2 = re.sub('\(.*?\)','',temp1)
#去掉括号中的内容,中文括号
pos = re.sub('(.*?)', '', temp2)
return pos2.薪酬改成统一单位,并分割成最低薪酬与最高薪酬
#利用正则表达式提取月薪,把待遇规范成千/月的形式
def get_salary(salary):
if '-'in salary: #针对1-2万/月或者10-20万/年的情况,包含-
low_salary=re.findall(re.compile('(\d*\.?\d+)'),salary)[0]
high_salary=re.findall(re.compile('(\d?\.?\d+)'),salary)[1]
if u'万' in salary and u'年' in salary:#单位统一成千/月的形式
low_salary = float(low_salary) / 12 * 10
high_salary = float(high_salary) / 12 * 10
elif u'万' in salary and u'月' in salary:
low_salary = float(low_salary) * 10
high_salary = float(high_salary) * 10
else:#针对20万以上/年和100元/天这种情况,不包含-,取最低工资,没有最高工资
high_salary=""
if u'面议' in salary:
low_salary = ""
else:
low_salary = re.findall(re.compile('(\d*\.?\d+)'), salary)[0]
if u'万' in salary and u'年' in salary:#单位统一成千/月的形式
low_salary = float(low_salary) / 12 * 10
elif u'万' in salary and u'月' in salary:
low_salary = float(low_salary) * 10
elif u'元'in salary and u'天'in salary:
low_salary=float(low_salary)/1000*21#每月工作日21天
return low_salary,high_salary3.将地区去掉区级单位
def get_area(area):
b = pd.Series(area)
c = b.str.split('-')
return c[0][0]4.将学历要求中的招**人统一改为无学历要求
def get_edu(edu):
#招**人替换成无学位要求
edu = re.sub('招.*?人', '无学历要求',edu)
return edu5.主函数读取文档并写入
def main():
data = load_from_xlsx(r'Data_mining.xlsx')
table, nrows = data[0], data[1]
print('一共有{}行数据,开始清洗数据'.format(nrows))
for i in range(1,nrows):
position = table.row_values(i)[1]
company=table.row_values(i)[2]
area = table.row_values(i)[4]#地区取到城市,把区域去掉
salary=table.row_values(i)[3]
durl = table.row_values(i)[0]
companytype = table.row_values(i)[7]
companysize = table.row_values(i)[5]
edu = table.row_values(i)[6]
field = table.row_values(i)[8]
#responsibility = table.row_values(i)[8]
#com = table.row_values(i)[9]
if salary:#如果待遇这栏不为空,计算最低最高待遇
getsalary=get_salary(salary)
low_salary=getsalary[0]
high_salary=getsalary[1]
else:
low_salary=high_salary=""
area = get_area(area)
position = get_position(position)
edu = get_edu(edu)
print('正在写入第{}条'.format(i))
output = '{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\n'.format(durl,position, company, area, low_salary, high_salary, companytype,edu,companysize, field)
f=codecs.open('51job.xls','a')
f.write(output)
f.close()
if __name__=='__main__':
main()数据处理完整代码:
#coding:utf8
import xlrd
import codecs
import re
#加载Excel数据,获得工作表和行数,用Excel
def load_from_xlsx(file):
data = xlrd.open_workbook(file)
table0 = data.sheet_by_name('Data_mining')
nrows = table0.nrows
return table0, nrows
#利用正则表达式提取月薪,把待遇规范成千/月的形式
def get_salary(salary):
if '-'in salary: #针对1-2万/月或者10-20万/年的情况,包含-
low_salary=re.findall(re.compile('(\d*\.?\d+)'),salary)[0]
high_salary=re.findall(re.compile('(\d?\.?\d+)'),salary)[1]
if u'万' in salary and u'年' in salary:#单位统一成千/月的形式
low_salary = float(low_salary) / 12 * 10
high_salary = float(high_salary) / 12 * 10
elif u'万' in salary and u'月' in salary:
low_salary = float(low_salary) * 10
high_salary = float(high_salary) * 10
else:#针对20万以上/年和100元/天这种情况,不包含-,取最低工资,没有最高工资
high_salary=""
if u'面议' in salary:
low_salary = ""
else:
low_salary = re.findall(re.compile('(\d*\.?\d+)'), salary)[0]
if u'万' in salary and u'年' in salary:#单位统一成千/月的形式
low_salary = float(low_salary) / 12 * 10
elif u'万' in salary and u'月' in salary:
low_salary = float(low_salary) * 10
elif u'元'in salary and u'天'in salary:
low_salary=float(low_salary)/1000*21#每月工作日21天
return low_salary,high_salary
def get_area(area):
b = pd.Series(area)
c = b.str.split('-')
return c[0][0]
def get_position(position):
#str1 = '数据挖掘工程师(J190626031) (职位编号:J190626031)'处理
#去掉制表符
temp1= re.sub('\t', '', position)
#去掉括号中的内容,英文的括号要加反斜杠
temp2 = re.sub('\(.*?\)','',temp1)
#去掉括号中的内容,中文括号
pos = re.sub('(.*?)', '', temp2)
return pos
def get_edu(edu):
#招**人替换成无学位要求
edu = re.sub('招.*?人', '无学历要求',edu)
return edu
def main():
data = load_from_xlsx(r'Data_mining.xlsx')
table, nrows = data[0], data[1]
print('一共有{}行数据,开始清洗数据'.format(nrows))
for i in range(1,nrows):
position = table.row_values(i)[1]
company=table.row_values(i)[2]
area = table.row_values(i)[4]#地区取到城市,把区域去掉
salary=table.row_values(i)[3]
durl = table.row_values(i)[0]
companytype = table.row_values(i)[7]
companysize = table.row_values(i)[5]
edu = table.row_values(i)[6]
field = table.row_values(i)[8]
#responsibility = table.row_values(i)[8]
#com = table.row_values(i)[9]
if salary:#如果待遇这栏不为空,计算最低最高待遇
getsalary=get_salary(salary)
low_salary=getsalary[0]
high_salary=getsalary[1]
else:
low_salary=high_salary=""
area = get_area(area)
position = get_position(position)
edu = get_edu(edu)
print('正在写入第{}条'.format(i))
output = '{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\t{}\n'.format(durl,position, company, area, low_salary, high_salary, companytype,edu,companysize, field)
f=codecs.open('51job.xls','a')
f.write(output)
f.close()
if __name__=='__main__':
main()处理得到数据如下 ,需求基本实现
