【我的架构师之路】- golang源码分析之interface的底层实现
【转载请标明出处】:https://blog.csdn.net/qq_25870633/article/details/83448222
今天我们来说一说 golang中的interface的讲解。golang的interface 类似java的Object,也类似 scala中的Any,类似于C++中的void*,但是又不一样。
interface 是否包含有 method,底层实现上用两种 struct 来表示:iface 和 eface。
eface:表示不含 method 的 interface 结构,或者叫 empty interface。对于 Golang 中的大部分数据类型都可以抽象出来 _type 结构,同时针对不同的类型还会有一些其他信息。
iface: 表示 non-empty interface 的底层实现。相比于 empty interface,non-empty 要包含一些 method。method 的具体实现存放在 itab.fun 变量里。
废话不多说,我们直接上代码先:(被定义在 src/runtime/runtime2.go 中)
type iface struct {
tab *itab
data unsafe.Pointer
}
type eface struct {
_type *_type
data unsafe.Pointer
}上述就是两种 interface 的定义。然后我们再看 iface中的 itab 结构:(被定义在 src/runtime/runtime2.go 中)
我这里有三个版本的 itab 定义,分别是:
【1.8.1】:
// 1.8.1 版本定义
type itab struct {
inter *interfacetype // 接口的类型
_type *_type // 实际对象类型
hash uint32 // 赋值 类型的Hash 用于做类型转换用
_ [4]byte
fun [1]uintptr // 可变大小。 fun [0] == 0表示_type不实现inter.
}【1.9.7】:
// 1.9.7 版本
type itab struct {
inter *interfacetype // 接口的类型
_type *_type // 实际对象类型
link *itab
hash uint32 // 赋值 类型的Hash 用于做类型转换用
bad bool // type是否实现接口,标识位
inhash bool // 添加自身Hash
unused [2]byte // 并没有找到地方用 ...
fun [1]uintptr // 实际对象的func 队列的首地址
}【1.10.4】:
// 1.10.4 版本
// 在非 gc 内存中分配的编译器已知的Itab 存储布局并需要与(../cmd/compile/internal/gc/reflect.go:/^func.dumptypestructs)同步
// 这里官方的注释错了,应该是 ../cmd/compile/internal/gc/reflect.go:/^func.dumptabs
type itab struct {
inter *interfacetype // 接口的类型
_type *_type // 实际对象类型
hash uint32 // 赋值 类型的Hash 用于做类型转换用
_ [4]byte
fun [1]uintptr // 可变大小。 fun [0] == 0表示_type不实现inter.
}我们可以看到 三个版本中都有主要的三个部分,【一】代表接口自身类型的 interfacetype;【二】表示 实际对象类型 的 _type;【三】实际对象的func 队列的首地址 fun [1]uintptr;紧接着我们看下 interfacetype:
// 1.10.4 版本 // 1.9.7版本 // 1.8.1
type interfacetype struct {
typ _type
pkgpath name
mhdr []imethod
}
我们可以看出来 interfacetype 里头其实是存放了 _type 的。而在itab中存放了 _type的指针。那么,下面我们先来看一看 _type 的定义:
// 需要和这些东东同步 ../cmd/link/internal/ld/decodesym.go:/^func.commonsize,
// ../cmd/compile/internal/gc/reflect.go:/^func.dcommontype and
// ../reflect/type.go:/^type.rtype.
type _type struct {
size uintptr // 表示类型的宽度/长度
ptrdata uintptr // 包含所有指针的内存前缀的大小
hash uint32 // Hash类型; 避免在哈希表中计算
tflag tflag // 额外类型信息标志
align uint8 // 该类型的变量对齐方式
fieldalign uint8 // 该类型的结构字段对齐方式
kind uint8 // C的枚举 (干嘛用的?)
alg *typeAlg // 算法表
// gcdata存储垃圾收集器的GC类型数据
// 如果 KindGCProg 位(用不同的bit来标识动作含义)被设置在kind字段中,则gcdata是GC程序。
// 否则它是一个ptrmask 位图。 有关详细信息,请参阅 mbitmap.go。
gcdata *byte // gc 的数据
str nameOff // 字符串形式
ptrToThis typeOff // 指向此类型的指针的类型可以为零
}
// typeAlg is 总是 在 reflect/type.go 中 copy或使用.
// 并保持他们同步.
type typeAlg struct {
// 算出该类型的Hash
// (ptr to object, seed) -> hash
hash func(unsafe.Pointer, uintptr) uintptr
// 比较该类型对象
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
}
type nameOff int32
type typeOff int32好了,以上就是 iface 类型的定义,下面我们再来看看 eface类型的定义:
type eface struct {
_type *_type
data unsafe.Pointer
}可以看出在 eface 中就更加简单了,完全就是 定义了一个 _type 的指针,指向数据的指针 data,然后就没了。
那么,下面我们可能会着重讲一讲 iface 了。
我们先来看一看,可能分别具备两种接口的对象,分别赋值给两种接口:
我们可以看到,变化分别在 第7 行的 var ei interface{} = a ;和第11行的 fmt.Println(ei, ii) 处,分别可以为变量赋值给了两种不同的接口。看上面的函数原型,可以看出中间过程编译器将根据我们的转换目标类型的 empty interface 还是 non-empty interface,来对原数据类型进行转换(转换成 <*_type, unsafe.Pointer> 或者 <*itab, unsafe.Pointer>)。这里对于 struct 满不满足 interface 的类型要求(也就是 struct 是否实现了 interface 的所有 method),是由编译器来检测的。
现在我们回到 interfacetype 类型定义中,在 interfacetype 中包含了一些关于 interface 本身的信息,比如 package path,包含的 method。我们再来深入看看 method 切片的类型 imethod:
//这里的 method 只是一种函数声明的抽象,比如 func Print() error
type imethod struct {
name nameOff
ityp typeOff
}
type nameOff int32
type typeOff int32【注意】method 存的是func 的声明抽象,而 itab 中的 func 字段才是存储 func 的真实切片。
_type :表示 concrete type (具体类型)。fun 表示的 interface 里面的 method 的具体实现。比如 interface type 包含了 method A, B,则通过 fun 就可以找到这两个 method 的具体实现。
【注意】以下是copy了 http://legendtkl.com/2017/07/01/golang-interface-implement/ 的:
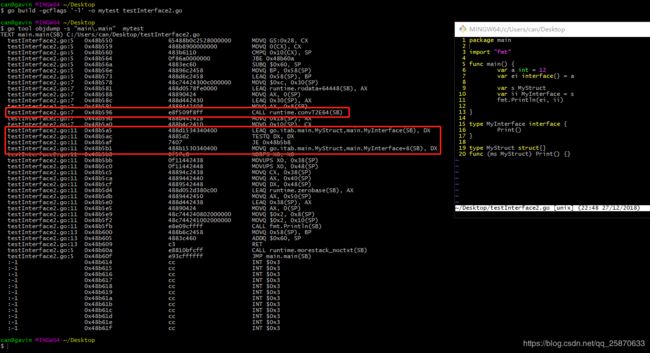
这里有个问题 fun 是长度为 1 的 uintptr 数组,那么怎么表示多个 method 呢?看一下测试程序:
|
|
看一下函数调用对应的汇编代码:
以下是该博客原文的图:

其中 0x18(SP) 对应的 itab 的值。fun 在 x86-64 机器上对应 itab 内的地址偏移为 8+8+8+4+4 = 32 = 0x20,也就是 0x20(AX) 对应的 fun 的值,此时存放的 AWK 函数地址。然后 0x28(AX) = &Hello,0x30(AX) = &Print,0x38(AX) = &World。对的,每次函数是按字典序排序存放的。
以下是我自己操作的图:

我们再来看一下函数地址究竟是怎么写入的?首先 Golang 中的 uintptr 一般用来存放指针的值,这里对应的就是函数指针的值(也就是函数的调用地址)。但是这里的 fun 是一个长度为 1 的 uintptr 数组。我们看一下 (在 src/runtime/ifce.go 文件中) runtime 包的 itabAdd 函数(注意了我这里用 1.10.4来讲解的,1.9.x及之前的版本叫做 additab )。
// itabAdd adds the given itab to the itab hash table.
// itabLock must be held.
func itabAdd(m *itab) {
// Bugs can lead to calling this while mallocing is set,
// typically because this is called while panicing.
// Crash reliably, rather than only when we need to grow
// the hash table.
if getg().m.mallocing != 0 {
throw("malloc deadlock")
}
t := itabTable
if t.count >= 3*(t.size/4) { // 75% load factor
// Grow hash table.
// t2 = new(itabTableType) + some additional entries
// We lie and tell malloc we want pointer-free memory because
// all the pointed-to values are not in the heap.
t2 := (*itabTableType)(mallocgc((2+2*t.size)*sys.PtrSize, nil, true))
t2.size = t.size * 2
// Copy over entries.
// Note: while copying, other threads may look for an itab and
// fail to find it. That's ok, they will then try to get the itab lock
// and as a consequence wait until this copying is complete.
iterate_itabs(t2.add)
if t2.count != t.count {
throw("mismatched count during itab table copy")
}
// Publish new hash table. Use an atomic write: see comment in getitab.
atomicstorep(unsafe.Pointer(&itabTable), unsafe.Pointer(t2))
// Adopt the new table as our own.
t = itabTable
// Note: the old table can be GC'ed here.
}
t.add(m)
}
// add adds the given itab to itab table t.
// itabLock must be held.
func (t *itabTableType) add(m *itab) {
// See comment in find about the probe sequence.
// Insert new itab in the first empty spot in the probe sequence.
mask := t.size - 1
h := itabHashFunc(m.inter, m._type) & mask
for i := uintptr(1); ; i++ {
p := (**itab)(add(unsafe.Pointer(&t.entries), h*sys.PtrSize))
m2 := *p
if m2 == m {
// A given itab may be used in more than one module
// and thanks to the way global symbol resolution works, the
// pointed-to itab may already have been inserted into the
// global 'hash'.
return
}
if m2 == nil {
// Use atomic write here so if a reader sees m, it also
// sees the correctly initialized fields of m.
// NoWB is ok because m is not in heap memory.
// *p = m
atomic.StorepNoWB(unsafe.Pointer(p), unsafe.Pointer(m))
t.count++
return
}
h += i
h &= mask
}
}
func itabHashFunc(inter *interfacetype, typ *_type) uintptr {
// compiler has provided some good hash codes for us.
return uintptr(inter.typ.hash ^ typ.hash)
}
然后在看 init 函数:
// init fills in the m.fun array with all the code pointers for
// the m.inter/m._type pair. If the type does not implement the interface,
// it sets m.fun[0] to 0 and returns the name of an interface function that is missing.
// It is ok to call this multiple times on the same m, even concurrently.
func (m *itab) init() string {
inter := m.inter
typ := m._type
x := typ.uncommon()
// both inter and typ have method sorted by name,
// and interface names are unique,
// so can iterate over both in lock step;
// the loop is O(ni+nt) not O(ni*nt).
ni := len(inter.mhdr)
nt := int(x.mcount)
xmhdr := (*[1 << 16]method)(add(unsafe.Pointer(x), uintptr(x.moff)))[:nt:nt]
j := 0
imethods:
for k := 0; k < ni; k++ {
i := &inter.mhdr[k]
itype := inter.typ.typeOff(i.ityp)
name := inter.typ.nameOff(i.name)
iname := name.name()
ipkg := name.pkgPath()
if ipkg == "" {
ipkg = inter.pkgpath.name()
}
for ; j < nt; j++ {
t := &xmhdr[j]
tname := typ.nameOff(t.name)
if typ.typeOff(t.mtyp) == itype && tname.name() == iname {
pkgPath := tname.pkgPath()
if pkgPath == "" {
pkgPath = typ.nameOff(x.pkgpath).name()
}
if tname.isExported() || pkgPath == ipkg {
if m != nil {
ifn := typ.textOff(t.ifn)
*(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn
}
continue imethods
}
}
}
// didn't find method
m.fun[0] = 0
return iname
}
m.hash = typ.hash
return ""
}
在 init 函数中的for中有一句: *(*unsafe.Pointer)(add(unsafe.Pointer(&m.fun[0]), uintptr(k)*sys.PtrSize)) = ifn ;意思是在 fun[0] 的地址后面依次写入其他 method 对应的函数指针。而上面的 itabHashFunc 函数 则是:通过 runtime 包里面有一个 hash 表,hash[hashitab(interface_type, concrete_type)] 可以取得 itab。
【interface的类型断言】:
大家都知道在使用interface 强转会实际的类型时,一般都会用到的额类型断言:
n, ok := v.(int)那么,interface 的类型断言,底层是如何实现的呢?
主要是下面几个 func 来实现的:
func assertI2I(inter *interfacetype, i iface) (r iface) {
tab := i.tab
if tab == nil {
// explicit conversions require non-nil interface value.
panic(&TypeAssertionError{"", "", inter.typ.string(), ""})
}
if tab.inter == inter {
r.tab = tab
r.data = i.data
return
}
r.tab = getitab(inter, tab._type, false)
r.data = i.data
return
}
func assertI2I2(inter *interfacetype, i iface) (r iface, b bool) {
tab := i.tab
if tab == nil {
return
}
if tab.inter != inter {
tab = getitab(inter, tab._type, true)
if tab == nil {
return
}
}
r.tab = tab
r.data = i.data
b = true
return
}
func assertE2I(inter *interfacetype, e eface) (r iface) {
t := e._type
if t == nil {
// explicit conversions require non-nil interface value.
panic(&TypeAssertionError{"", "", inter.typ.string(), ""})
}
r.tab = getitab(inter, t, false)
r.data = e.data
return
}
func assertE2I2(inter *interfacetype, e eface) (r iface, b bool) {
t := e._type
if t == nil {
return
}
tab := getitab(inter, t, true)
if tab == nil {
return
}
r.tab = tab
r.data = e.data
b = true
return
}
//go:linkname reflect_ifaceE2I reflect.ifaceE2I
func reflect_ifaceE2I(inter *interfacetype, e eface, dst *iface) {
*dst = assertE2I(inter, e)
}好了,今天是元旦放假的第一天我也偷下懒,不想写这么多了,(本文有待完善,待续 ......)