每天一篇论文 SuperDepth: Self-Supervised, Super-Resolved Monocular Depth Estimation
原文
STN
STN网络
https://blog.csdn.net/qq_39422642/article/details/78870629
摘要
自监督单目深度估计的最新技术已接近于监督方法的性能,但仅在低分辨率下工作。研究表明,高分辨率是实现高保真自监督单目深度预测的关键。受近年来单图像超分辨率的深度学习方法的启发,我们提出了一种深度超分辨率的亚像素卷积层扩展方法,该方法可以从相应的低分辨率卷积特征中精确地合成高分辨率差异。此外,我们还引入了一个可微增强层,它可以精确地融合来自图像及其水平转换的预测,从而减少由于遮挡而在视差图中生成的左右阴影区域的影响。这两项贡献在自我监督的深度和姿势估计方面都比最先进的KITTI基准提供了显著的性能提升。

贡献
1.使用亚像素卷积层来有效且准确地从较低分辨率的输出中超分辨差异,从而取代通常在视差解码器网络中使用的反卷积或调整卷积的大小。
2.引入了一个可微翻转增强层,使得视差模型能够以端到端的方式学习图像边界上的差异的改进先验。这导致在减少伪影和遮挡区域的情况下改进了测试时间深度预测,有效地消除了通常在其他方法中使用的额外后处理步骤的需要[6],[13]。
3.使用同步的立体图像流以自监督的方式训练我们的单目视差估计网络,从而消除了对地面真实深度标签的需要。我们的结果显示,我们提出的层对整体的单目视差估计精度有显著的效能提升.
[6]C. Godard, O. Mac Aodha, and G. J. Brostow, “Unsupervised monocular depth estimation with left-right consistency,” in CVPR, vol. 2,
no. 6, 2017, p. 7.
[13]Z. Yin and J. Shi, “Geonet: Unsupervised learning of dense depth, optical flow and camera pose,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, 2018.
方法
与传统的深度估计方法一样,本文的方法还是用图像复原的方法

本文在 ESPCN基础上提出的超分辨率网络
ESPCN介绍
ESPCN原文
本文的超分辨率网络为Real-time single image and video superresolution using an efficient sub-pixel convolutional neural network,”
这有效地代替了视差插值层,同时学习了相关的低分辨率卷积特征,可以进行高质量的视差合成。我们将视差网络中四个金字塔尺度的卷积分支与子像素卷积分支交换,子像素卷积分支由4个连续的2D卷积层组成,每个卷积层具有32、32、32、16个层,每个层具有1个像素步长,然后再进行ReLu激活。最后的卷积输出然后通过像素重新排列操作被重新映射到目标深度分辨率,从而产生有效的亚像素卷积操作,如[9]所述。
Differentiable Flip Augmentation
在立体视觉中,由于右图中缺少可观察的左图像边界场景点,视差模型不可避免地会在边界像素上学习到一个很差的先验值。为了避免这种行为,以前的方法[6],[8]包括一个后处理步骤,alpha将图像中的视差图像与其水平翻转的版本进行混合。虽然这显著减少了图像边界周围的视觉伪影并提高了整体精度,但它将最终的视差估计与训练分离。为此,我们将此步骤替换为视差估计模型中的可微翻转增强层,从而允许我们以端到端的方式微调视差。通过利用[10]中的可微图像渲染来还原翻转的视差,该模型对原始和水平翻转的图像使用相同的模型执行前向传递。在处理类似于[6]的边界时,输出以可微的方式与像素级平均操作融合在一起。
LOSS 设置

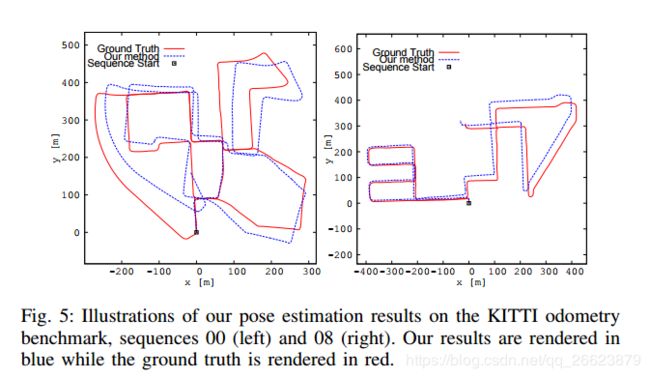
结果

对比