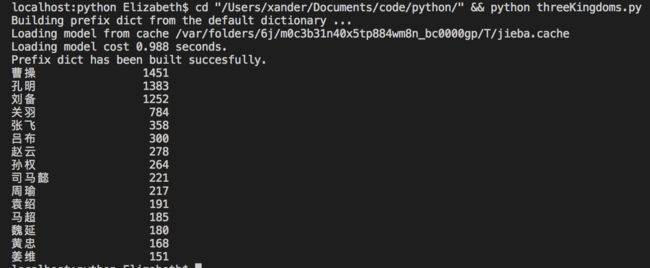
统计《三国演义》前15个人名
在课堂代码的基础上,用循环做了一个更深的去噪的处理。具体就是首先每个词输出的时候问(y/n)来判断是不是人名,攒够15个人名后输出统计的exclude,然后第二次再除去那些exclude,最后得到完整的前15的人名。(其实就是人工去噪。。。)
#threeKingdoms.py
import jieba
with open("text//threekingdoms.txt","r",encoding = 'utf-8') as f:
text = f.read()
words = jieba.lcut(text) #分词
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
exclude = ['大军', '荆州', '将军', '却说', '二人', '不可', '不能', '如此', '商议', '如何', '主公', '军士', '左右', '军马', '引兵', '次日', '大喜', '天下', '东吴', '于是', '今日', '不敢', '魏兵', '陛下', '一人', '都督', '人马', '不知', '汉中', '只见', '众将', '后主', '蜀兵', '上马', '大叫', '太守', '此人', '夫人', '先主', '后人', '背后', '城中', '天子', '一面', '何不', '忽报', '先生', '百姓', '何故', '然后', '先锋', '不如', '赶来']
for ch in exclude:
del counts[ch]
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
"""
# 人工去噪:去除非人名,保留前15人名
cnt = 13
i = 13
while(cnt<15):
word,count = items[i]
i += 1
ch = input("{:<10}{:>5} (y/n)".format(word, count))
if ch=='n':
exclude.append(word)
del counts[word]
else:
cnt+=1
print(exclude)
"""
# 输出结果
items = list(counts.items())
items.sort(key = lambda x:x[1], reverse = True)
for i in range(15):
word,count = items[i]
print("{:\u3000<8}{:>8}".format(word, count))