BN、LN、IN、GN、SN归一化
作者:泛音
公众号:知识交点
该小伙子文章写得不错,感兴趣的大家可以关注下:

公众号:知识交点
内容包含:BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm、SwitchableNorm
1.简述
1.1 论文链接
(1)、Batch Normalization
https://arxiv.org/pdf/1502.03167.pdf
(2)、Layer Normalizaiton
https://arxiv.org/pdf/1607.06450v1.pdf
(3)、Instance Normalization
https://arxiv.org/pdf/1607.08022.pdf
https://github.com/DmitryUlyanov/texture_nets
(4)、Group Normalization
https://arxiv.org/pdf/1803.08494.pdf
(5)、Switchable Normalization
https://arxiv.org/pdf/1806.10779.pdf
https://github.com/switchablenorms/Switchable-Normalization
1.2 整体介绍
归一化层,目前主要有这几个方法,Batch Normalization(2015年)、Layer Normalization(2016年)、Instance Normalization(2017年)、Group Normalization(2018年)、Switchable Normalization(2018年);
将输入的图像shape记为[N, C, H, W],这几个方法主要的区别就是在:
batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
GroupNorm将channel分组,然后再做归一化;
SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。

2.详细解说
2.1 Batch Normalization

算法过程:
(1)、沿着通道计算每个batch的均值u
(2)、沿着通道计算每个batch的方差σ^2
(3)、对x做归一化,x’=(x-u)/开根号(σ^2+ε)
(4)、加入缩放和平移变量γ和β ,归一化后的值,y=γx’+β
加入缩放平移变量的原因是: 不一定每次都是标准正态分布,也许需要偏移或者拉伸。保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。这两个参数是用来学习的参数。
整体公式:

向传播CODE:
import numpy as np
def Batchnorm(x, gamma, beta, bn_param):
# x_shape:[B, C, H, W]
running_mean = bn_param['running_mean']
running_var = bn_param['running_var']
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(0, 2, 3), keepdims=True)
x_var = np.var(x, axis=(0, 2, 3), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
# 因为在测试时是单个图片测试,这里保留训练时的均值和方差,用在后面测试时用
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return results, bn_param
pytorch中的API:
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
torch.nn.BatchNorm3d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
# num_features:来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
# eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# momentum:动态均值和动态方差所使用的动量。默认为0.1。
# affine:布尔值,当设为true,给该层添加可学习的仿射变换参数。
# track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差
2.2 Layer Normalizaiton
batch normalization存在以下缺点:
(1)、对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
(2)、BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作。
BN与LN的区别在于:
(1)、LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
(2)、BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
(3)、LN用于RNN效果比较明显,但是在CNN上,不如BN。
前向传播代码:
def Layernorm(x, gamma, beta):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(1, 2, 3), keepdims=True)
x_var = np.var(x, axis=(1, 2, 3), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results
Pytorch API:
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
# normalized_shape:输入尺寸[∗×normalized_shape[0]×normalized_shape[1]×…×normalized_shape[−1]]
# eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# elementwise_affine:布尔值,当设为true,给该层添加可学习的仿射变换参数。
2.3 Instance Normalization
BN注重对每个batch进行归一化,保证数据分布一致,因为判别模型中结果取决于数据整体分布。
但是图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
公式:
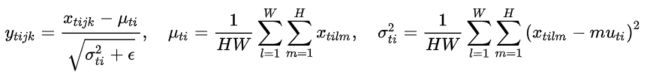
前向代码:
def Instancenorm(x, gamma, beta):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=(2, 3), keepdims=True)
x_var = np.var(x, axis=(2, 3), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results
Pytorch API:
torch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm2d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
torch.nn.InstanceNorm3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
# num_features:来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
# eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# momentum:动态均值和动态方差所使用的动量。默认为0.1。
# affine:布尔值,当设为true,给该层添加可学习的仿射变换参数。
# track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
2.4 Group Normalization
主要是针对Batch Normalization对小batchsize效果差,GN将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值,这样与batchsize无关,不受其约束。
前向code:
def GroupNorm(x, gamma, beta, G=16):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
x = np.reshape(x, (x.shape[0], G, x.shape[1]/16, x.shape[2], x.shape[3]))
x_mean = np.mean(x, axis=(2, 3, 4), keepdims=True)
x_var = np.var(x, axis=(2, 3, 4), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results
Pytorch API:
torch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True)
# num_groups:需要划分为的groups
# num_features:来自期望输入的特征数,该期望输入的大小为’batch_size x num_features [x width]’
# eps:为保证数值稳定性(分母不能趋近或取0),给分母加上的值。默认为1e-5。
# momentum:动态均值和动态方差所使用的动量。默认为0.1。
# affine:布尔值,当设为true,给该层添加可学习的仿射变换参数。
2.5 Switchable Normalization
本篇论文作者认为:
(1)、第一,归一化虽然提高模型泛化能力,然而归一化层的操作是人工设计的。在实际应用中,解决不同的问题原则上需要设计不同的归一化操作,并没有一个通用的归一化方法能够解决所有应用问题;
(2)、第二,一个深度神经网络往往包含几十个归一化层,通常这些归一化层都使用同样的归一化操作,因为手工为每一个归一化层设计操作需要进行大量的实验。
因此作者提出自适配归一化方法——Switchable Normalization(SN)来解决上述问题。与强化学习不同,SN使用可微分学习,为一个深度网络中的每一个归一化层确定合适的归一化操作。
公式:

前向传播CODE:
def SwitchableNorm(x, gamma, beta, w_mean, w_var):
# x_shape:[B, C, H, W]
results = 0.
eps = 1e-5
mean_in = np.mean(x, axis=(2, 3), keepdims=True)
var_in = np.var(x, axis=(2, 3), keepdims=True)
mean_ln = np.mean(x, axis=(1, 2, 3), keepdims=True)
var_ln = np.var(x, axis=(1, 2, 3), keepdims=True)
mean_bn = np.mean(x, axis=(0, 2, 3), keepdims=True)
var_bn = np.var(x, axis=(0, 2, 3), keepdims=True)
mean = w_mean[0] * mean_in + w_mean[1] * mean_ln + w_mean[2] * mean_bn
var = w_var[0] * var_in + w_var[1] * var_ln + w_var[2] * var_bn
x_normalized = (x - mean) / np.sqrt(var + eps)
results = gamma * x_normalized + beta
return results
3 结果比较

4 参考链接:
本篇大部分内容摘抄自https://blog.csdn.net/liuxiao214/article/details/81037416
推荐阅读:
【一分钟论文】IJCAI2019 | Self-attentive Biaffine Dependency Parsing
【一分钟论文】 NAACL2019-使用感知句法词表示的句法增强神经机器翻译
【一分钟论文】Semi-supervised Sequence Learning半监督序列学习
【一分钟论文】Deep Biaffine Attention for Neural Dependency Parsing
详解Transition-based Dependency parser基于转移的依存句法解析器
经验 | 初入NLP领域的一些小建议
学术 | 如何写一篇合格的NLP论文
干货 | 那些高产的学者都是怎样工作的?
一个简单有效的联合模型
近年来NLP在法律领域的相关研究工作

好文!好看