什么是大数据?如何成为大数据开发工程师技术大牛?
其实大数据并不是一种概念,而是一种方法论。简单来说,就是通过分析和挖掘全量的非抽样的数据辅助决策。大数据可以实现
的应用可以概括为两个方向,一个是精准化定制,第二个是预测。比如像通过搜索引擎搜索同样的内容,每个人的结果却是大不
相同的。再比如精准营销、百度的推广、淘宝的喜欢推荐,或者你到了一个地方,自动给你推荐周边的消费设施等等。
目前市场对大数据相关人才的需求与日俱增,岗位的增多,也导致了大数据相关人才出现了供不应求的状况,从而引发了一波大
数据学习的浪潮。大家可以先了解一下关于大数据相关的岗位分类,以及各个岗位需要掌握那些相对应的技能,并想清楚自己未
来的发展方向,再开始着手针对岗位所需的技术进行学习与研究。所谓知己知彼,才能更好的达成目标嘛。

大数据处理技术怎么学习呢?在做大数据开发之前,因为Hadoop是高层次的语言开发,需要懂得Java或者Python,很快的就能上
手。所有的大数据生态架构都是基于linux系统的基础上的,所以你要有Linux系统的基本知识。如果你不懂Java或者Python还有
Linux系统,那么这都是你必学的知识(Java或者Python可二选其一)。
很多初学者,对大数据的概念都是模糊不清的,大数据是什么,能做什么,学的时候,该按照什么线路去学习,学完往哪方面发展,想深入了解,想学习的同学欢迎加入大数据学习qq群:199427210,有大量干货(零基础以及进阶的经典实战)分享给大家,并且有清华大学毕业的资深大数据讲师给大家免费授课,给大家分享目前国内最完整的大数据高端实战实用学习流程体系
第一阶段
Linux系统:因为大数据相关软件都是在Linux系统上运行的,所以Linux要学习的扎实一些,学好Linux对你快速掌握大数据相关技术会有很大的帮助,能让你更好的理解hadoop、hive、hbase、spark等大数据软件的运行环境和网络环境配置,能少踩很多坑,学会shell就能看懂脚本这样能更容易理解和配置大数据集群。还能让你对以后新出的大数据技术学习起来更快。
鸟哥的Linux私房菜 是一本公认的Linux的入门书籍。

第二阶段
Python:Python 的排名从去年开始就借着人工智能持续上升,现在它已经成为了语言排行第一名。
从学习难易度来看,作为一个为“优雅”而生的语言,Python语法简捷而清晰,对底层做了很好的封装,是一种很容易上手的高级语言。在一些习惯于底层程序开发的“硬核”程序员眼里,Python简直就是一种“伪代码”。
在大数据和数据科学领域,Python几乎是万能的,任何集群架构软件都支持Python,Python也有很丰富的数据科学库,所以Python不得不学。

第三阶段
Hadoop:几乎已经成为大数据的代名词,所以这个是必学的。 Hadoop里面包括几个重要组件HDFS、MapReduce和YARN。
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。当然怎么分块分析,怎么做Reduce操作非常复杂,Hadoop已经提供了数据分析的实现,我们只需要编写简单的需求命令即可达成我们想要的数据。
记住学到这里可以作为你学大数据的一个节点。
Zookeeper:是一个分布式的,开放源码的分布式应用程序协调服务,也是个万金油,安装Hadoop的HA的时候就会用到它,以后的Hbase也会用到它。它一般用来存放一些相互协作的信息,这些信息比较小一般不会超过1M,都是使用它的软件对它有依赖,对于我们来讲只需要把它安装正确,让它正常的跑起来就可以了。
Mysql:大数据的处理学完了,那么接下来要学习小数据的处理工具Mysql数据库,因为装hive的时候要用到,Mysql需要掌握到什么层度呢?你能在Linux上把它安装好,运行起来,会配置简单的权限,修改root的密码,创建数据库就可以了。这里主要的是学习SQL的语法,因为hive的语法和这个非常相似。
Sqoop:这个是用于把Mysql里的数据导入到Hadoop里的。当然你也可以直接把Mysql数据表导出成文件再放到HDFS上也是可以的,但是生产环境中使用要注意Mysql的压力。
Hive:这个东西对于会SQL语法的同学们来说就是神器,它能让你处理大数据变的很简单、明了,不会再费劲的编写MapReduce程序。有的人说Pig那?它和Pig相似掌握一个就可以了。
Oozie:既然学会Hive了,我相信你一定需要这个,它可以帮你管理你的Hive或者MapReduce、Spark脚本,还能检查你的程序是否执行正确,如果出错给你发出报警并能帮你重试程序,最重要的是还能帮你配置任务的依赖关系。我相信你一定会喜欢它的,不然你看着那一大堆脚本,和密密麻麻的crond是不是有种“即将崩溃”的感觉。
Hbase:这是Hadoop生态体系中的NOSQL数据库,他的数据是按照key和value的形式存储的并且key是唯一的,所以它能用来做数据的排重,它与MYSQL相比能存储的数据量大很多。所以他常被用于大数据处理完成之后的存储目的地。
Kafka:这是个比较好用的队列工具,队列是干什么的?排队买票你知道不?数据多了同样也需要排队处理,我们可以利用这个工具来做线上实时数据的入库或入HDFS,这时你可以与一个叫Flume的工具配合使用,它是专门用来提供对数据进行简单处理,并写到各种数据接受方的。
Spark:它是用来弥补基于MapReduce处理数据速度上的缺点,它的特点是把数据装载到内存中计算而不是去读硬盘。特别适合做迭代运算,所以算法流们特别喜欢它。它是用scala编写的。Java语言或者Scala都可以操作它,因为它们都是用JVM的。
这些东西你都会了就成为一个专业的大数据开发工程师了,月薪3W都是毛毛雨啦。
后续提高
大数据结合人工智能达到真正的数据科学家,打通了数据科学的任督二脉,在公司是技术专家级别,这时候月薪再次翻倍且成为公司核心骨干。
机器学习:是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域,它主要使用归纳、综合而不是演绎。机器学习的算法基本比较固定了,学习起来相对容易。
深度学习:深度学习的概念源于人工神经网络的研究,最近几年发展迅猛。深度学习应用的实例有AlphaGo、人脸识别、图像检测等。是国内外稀缺人才,但是深度学习相对比较难,算法更新也比较快,需要跟随有经验的老师学习。
最快的学习方法,就是师从行业专家,学习老师多年积累的经验,自己少走弯路达到事半功倍的效果。自古以来,名师出高徒。
想要学好大数据需掌握以下技术:
1. Java编程技术
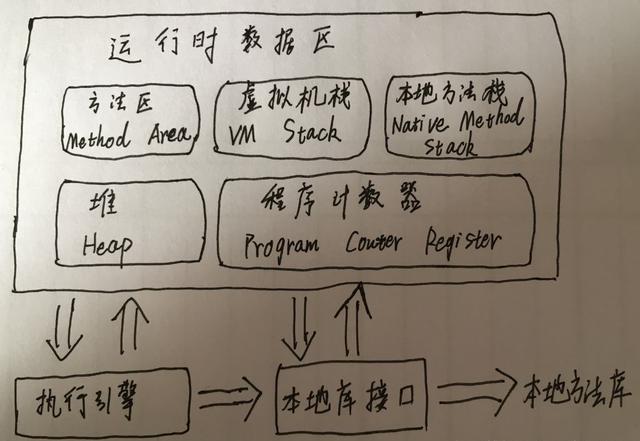
Java编程技术是大数据学习的基础,Java是一种强类型语言,拥有极高的跨平台能力,可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等,是大数据工程师最喜欢的编程工具,因此,想学好大数据,掌握Java基础是必不可少的!
2.Linux命令
对于大数据开发通常是在Linux环境下进行的,相比Linux操作系统,Windows操作系统是封闭的操作系统,开源的大数据软件很受限制,因此,想从事大数据开发相关工作,还需掌握Linux基础操作命令。
3. Hadoop


Hadoop是大数据开发的重要框架,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,因此,需要重点掌握,除此之外,还需要掌握Hadoop集群、Hadoop集群管理、YARN以及Hadoop高级管理等相关技术与操作!
4. Hive

Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,十分适合数据仓库的统计分析。对于Hive需掌握其安装、应用及高级操作等。
5. Avro与Protobuf
Avro与Protobuf均是数据序列化系统,可以提供丰富的数据结构类型,十分适合做数据存储,还可进行不同语言之间相互通信的数据交换格式,学习大数据,需掌握其具体用法。
6. HBase
HBase是一个分布式的、面向列的开源数据库,它不同于一般的关系数据库,更适合于非结构化数据存储的数据库,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,大数据开发需掌握HBase基础知识、应用、架构以及高级用法等。
7. Flume

Flume是一款高可用、高可靠、分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。大数据开发需掌握其安装、配置以及相关使用方法。
8. SSM
SSM框架是由Spring、SpringMVC、MyBatis三个开源框架整合而成,常作为数据源较简单的web项目的框架。大数据开发需分别掌握Spring、SpringMVC、MyBatis三种框架的同时,再使用SSM进行整合操作。
9.Kafka

Kafka是一种高吞吐量的分布式发布订阅消息系统,其在大数据开发应用上的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。大数据开发需掌握Kafka架构原理及各组件的作用和使用方法及相关功能的实现!
10.Scala

Scala是一门多范式的编程语言,大数据开发重要框架Spark是采用Scala语言设计的,想要学好Spark框架,拥有Scala基础是必不可少的,因此,大数据开发需掌握Scala编程基础知识!
11.Spark

Spark是专为大规模数据处理而设计的快速通用的计算引擎,其提供了一个全面、统一的框架用于管理各种不同性质的数据集和数据源的大数据处理的需求,大数据开发需掌握Spark基础、SparkJob、Spark RDD、spark job部署与资源分配、Spark shuffle、Spark内存管理、Spark广播变量、Spark SQL、Spark Streaming以及Spark ML等相关知识。我这有Spark的学习资料,需要的加QQ群:199427210,免费领取。
12.Azkaban
Azkaban是一个批量工作流任务调度器,可用于在一个工作流内以一个特定的顺序运行一组工作和流程,可以利用Azkaban来完成大数据的任务调度,大数据开发需掌握Azkaban的相关配置及语法规则。
13.Python与数据分析

Python是面向对象的编程语言,拥有丰富的库,使用简单,应用广泛,在大数据领域也有所应用,主要可用于数据采集、数据分析以及数据可视化等,因此,大数据开发需学习一定的Python知识。
互联网行业每隔5、6年就是一次"改朝换代"。Web1.0时代用户通过浏览器获取信息,网站凭借巨大的点击流量获利,信息的传递是单向的。到了Web2.0时代,Facebook、Twitter等掀起社会化浪潮,对传统的在线数字营销产业链三方角色进行了重构。你或许有过这样的经历,周一早上打开电脑,上百封新邮件在等待处理;在地铁上看看四周的人群大多数都在捧着手机、ipad聊天、处理工作、体验各种应用、看视频,工作和娱乐场所跟随他们"移动"起来;之前我们是被动的接受网络上挂出来的信息,现在我们越来越多地通过微博、SNS等社交工具参与互动甚至自己发布信息…这些细节都在告诉你,你已经不知不觉进入了大数据时代!据预测,以目前的速度发展,到2020年大数据的市场规模将超过2030亿美元。
2018年即将结束,随着需求的增长,数据的重点也在以同样的速度增长。今年以来,大数据的主要趋势围绕企业的大数据能力发展。移动应用程序开发人员正在寻找以更快的速度精确分析更多数据的最佳方法。大数据已经成为在最初投资中获得成功的技术。因此,许多移动应用程序开发商和大公司都期待着扩大他们的大数据项目。大数据实施的目标是在不久的将来取得更大的财务业绩。
只有完整的学完以上技术,才能算得上大数据开发人才,真正从事大数据开发相关工作,工作才更有底气,升职加薪不成问题!