漫谈Java中的互斥同步
漫谈Java中的互斥同步
互斥同步(Mutual Exclusion & Synchronization)是最常见的一种并发正确性保证手段,同步是指在多个线程并发访问共享数据时,保证共享数据在同一时刻只被一条(或者是一些,使用信号量的时候)线程使用。而互斥是实现同步的一种手段,临界区(Critical Section)、互斥量(Mutex)和信号量(Sempahore)都是主要的互斥实现方式。因此,在这四个字里面,互斥是因,同步是果,互斥是方法,同步是目的。———《深入理解JAVA虚拟机》
一、从sychronized到ReentrantLock
Java代码在编译之后会变成Java字节码,字节码被类加载器加载到JVM里,JVM执行字节码,最终需要转化为汇编指令在CPU上执行,JAVA中所使用的并发机制依赖于JVM的实现和CPU的指令。——《Java并发编程的艺术》
1.1 重量级,阻塞同步:sychronized
public V put(K key, V value) {
synchronized (mutex) {
return m.put(key, value);
}
}下面是以上代码的字节码信息(javap查看):
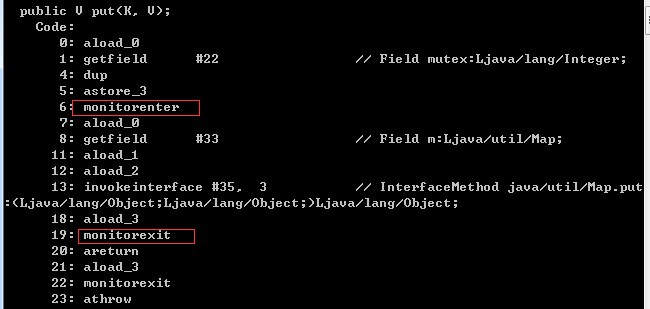
sychronized关键字是java中最基本的互斥同步手段,大括号中的部分就是加锁的同步块,而mutex参数,便是锁对象了。从JVM规范中可以看到Synchonized在JVM理的实现原理,JVM基于进入和退出Monitor对象来实现方法同步和代码块同步的。另外,Synchroized用的锁是存在Java对象Mark Word里的。任何一个对象都有一个monitor与之关联,当且一个monitor被持有只有,它将处于锁定状态。
根据虚拟机规范的要求,在执行monitorenter指令时,首先要去常事获取对象的锁。如果这个对象没被锁定,或者当前线程已经拥有了那个对象的锁,把锁的计数器+1,相应地,在执行monitorexit指令时会将锁计数器减一,当计数器为0时,锁就被释放了。如果获取对象锁失败了,那当前线程就要阻塞等待,知道对象锁被另外一个线程释放终止。
以上是《深入理解JAVA虚拟机》中的原文,从中可以看出,monitorenter就是操作系统中的P操作,而monitorexit则是V操作。而sychronized就是保证共享代码段或者数据段的PV操作指令集。但值得注意的是,当获取锁失败之后,当前线程会阻塞等待,这就涉及到了线程的切换了,是需要操作系统核心态去完成的。这就将大量的资源耗费在了线程切换上了,这也是sychronized属于重量级(Heavyweight)操作的原因了。
1.2 原子操作:CAS
互斥同步最主要的问题就是进行线程阻塞和唤醒所带来的性能问题,因此这种同步也被称为阻塞同步(Blocking Synchronization)。另外,它属于一种悲观的并发策略,无论共享数据是否真的会出现竞争,它都进行加锁、用户态核心态的转换、维护锁计数器和检查是否被阻塞的线程需要被唤醒等操作。
了解了操作系统的pv操作,我们可以很清楚的知道,之所以pv操作可以实现锁的互斥功能,达到同步效果,是因为PV两个操作是原子性的。那么编程语言的底层其实是运行在硬件上的处理器指令集,具备从语意上看起来需要多次操作的行为只通过一条处理器指令就能完成的指令常用的有:
- [ ] 测试并设置(Test-and-Set);
- [ ] 获取并增加(Fetch-and-Increment);
- [ ] 交换(Swap);
- [x] 比较并交换(Compare-and-Swap,简称CAS);
- [x] 加载链接/条件存储(Load-Linked/Store-Conditional,简称LL/SC)。
前三条指令是上个世纪就已经存在于大多数指令集之中的处理器指令。后面两条打勾的指令是现代处理器新增的,而且这两条指令的目的和功能是相似的。在IA64、x86指令集中通过cmpxchg指令完成CAS功能,在sparc-TSO中也有casa指令实现,而在ARM和PowerPC架构下,则需要使用一对Idre/strex指令来完成LL/SC的功能。
那么,处理器是如何实现原子操作的呢?首先我们先看一下什么叫缓冲行(cache line)。
“缓冲中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期。”这是对缓冲行的官方定义。从定义中我们可以看出,既然是最小存储单位,那么必然是原子性的,它也是每个线程读取主存变量的必要阶段。
32为IA-32处理器使用基于对缓存加锁或者总线加锁的方式来实现多处理器之间的原子操作。首先处理器会自动保存基本的内存操作的原子性。处理器保证从系统内存中读取或者写入一个字节是原子的,意思是当一个处理器夺取一个字节时,其他处理器不能访问这个字节的内存地址。Pentium6和最新的处理器能自动保存但处理器对同一个缓存行里进行16/32/64位的操作是原子的,但复杂的内存操作处理器是不能自动保证其原子性的,如果跨总线宽度、跨多个缓存行和跨页表的访问。但是,处理器提供总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
正是因为原子性的指令集的发展,Java才有了另一种并发策略就是,基于冲突检测的乐观并发策略。简单的说就是先进行操作,如果有其他线程争用则进行其他的补偿措施,一般的补偿就是不断的重试,知道成功。那么在没有并发冲突的时候,其实是没有锁的。这很大程度上节省了锁的开支,另外线程也没有了阻塞等待,减少了大量的时间。这种乐观的并发策略称为非阻塞同步(Non-Blocking Synchronization)。那么下面我们来看一下Java是如何利用CAS原子操作的。
1.3 Java提供原子操作的Unsafe类
在JDK1.5之后,Java程序中才可以使用CAS操作,该操作由sun.misc.Unsafe类封装。
另外该类属于比较底层的操作,并不提供给用户程序调用。Unsafe.getUnsafe()的代码中限制了只有启动类加载器(Bootstrap ClassLoader)加载的Class才能访问它,如果不采取反射手段,我们只能通过其他的Java API来间接获得它。
首先我们先看一下Unsafe的部分源码。Unsafe全部的源码请点击。

可以看到它们均是本地方法,其中objectFieldOffset方法,是通过一个属性对象得到在内存中相对于Object对象的偏移量。另外,三个compareAnd*方法,底层均是调用了CAS原子操作,其中CAS操作其实是需要三个参数的,分别是内存地址、旧的预期值和新的值。内存地址是会通过Object对象计算出Object的内存首地址,然后加上offset的偏移地址。CAS指令执行时,当且仅当内存地址内的值和旧址相等时,才将内存中的值替换为新的值。整个过程是保证原则性的。
我们可以看一看AbstractQueuedSynchronizer是如何实现调用CAS操作的。
/**
* Head of the wait queue, lazily initialized. Except for
* initialization, it is modified only via method setHead. Note:
* If head exists, its waitStatus is guaranteed not to be
* CANCELLED.
*/
private transient volatile Node head;//需要保证原子操作的属性
...
private static final long headOffset;//记录head的对象内偏移量
static {
try {
...
// 在对象初始化的时候,通过unsage的objectFieldOffset计算出属性的偏移量
headOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
...
} catch (Exception ex) { throw new Error(ex); }
}
...
/**
* CAS head field. Used only by enq.
*/
private final boolean compareAndSetHead(Node update) {
// 调用unsafe的CAS操作,内部会根据this对象和偏移量计算出内存真实地址
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}细心的读者可能会疑问,CAS操作具有原子性,怎么保证Unsafe到CAS操作的调用过程也具有原子性呢?
其实这几个重要的方法(类似的方法还有Math.sin())被虚拟机做了特殊处理,即使编译出的结果就是一条平台相关的处理器CAS指令,没有方法调用的过程,或者可以认为是无条件的内联进去了。这种特殊处理的方法叫做——固有函数(Intrinsics)。
1.3 Unsafe之上的非阻塞同步实现
至此,利用CAS操作,就可以在很多情况下简单高效地替代sychronized。比如,java.util.concurrent.atomic下的很多原子性变量,就可以实现变量有关的同步了。下面举个《深入理解JAVA虚拟机》中的例子,代码如下:
/**
* Atomic 变量自增运算测试
* AtomicTest.java
* @time 2016年8月19日
*/
public class AtomicTest {
public static AtomicInteger race = new AtomicInteger(0);
public static void increase() {
race.incrementAndGet();
}
private static final int THREADS_COUNT = 20;
public static void main(String[] args) {
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(new Runnable() {
@Override
public void run() {
for (int j = 0; j < 10000; j++) {
increase();
}
}
});
threads[i].start();
}
while (Thread.activeCount() > 1) {
Thread.yield();
}
System.out.println(race);
}
}
运行结果如下:200000。 如果将AtomicInteger换成int,输出的结果就不唯一了。这一切都归功于incrementAndGet()方法的原子性。它的实现其实非常简单,原代码如下:
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}这就是一个简单的非阻塞同步的应用场景。改方法在无限循环中,不断尝试if语句中的compareAndSet方法,很显然该方法内就是调用的Unsafe中的CAS操作,其内部会有一个int属性专门存放保存的数据。在调用CAS操作前,先获取到旧值,然后计算出加一后的新值,并将该对象和实现算好的属性偏移量,外加旧值、新值一并传递给CAS操作。如果成功则返回新值,否则继续操作。
值得注意的是,我们熟悉的volatile并不具有操作的原子性,它只是保证了我们volatile的数据是最新的。另外CAS看起来很美,其实也是有缺陷的:
1. 它无法避免”ABA”问题。尽管”ABA”问题很多情况下并会显现出来。
2. 循环时间长开销大。解决办法很有多,可以使用回旋或者自回旋减少尝试时间。如果JVM能支持处理器提供的pause指令,也可以提升一下效率。
3. 只能保证一个共享变量的原子操作。原因是CAS只是对于一个变量的原子操作,但是从Java1.5开始,JDK提供了AtomicReference类来保证引用对象之间的原子性,那么我们就可以把多个变量放在一个类里面,对这个类进行CAS操作了。
1.4 volatile的定义与实现
Java语言规范第三版中的对volatile的定义如下:Java编译语言允许线程访问共享变量,为了确保共享变量能被准确和一致地更新,线程应该确保通过排它锁单独获得这个变量。
从微观上讲,volatile只是在不同线程之间提供了变量可见性(一个线程对主存变量写,都会被其他线程所看到),从而实现一致性的效果。从宏观上讲,正是因为volatile和CAS操作,才有了现在的包。可以说,volatile和CAS操作,是现代并发包的基石。
那么volatile是如何来保证可见性的呢?根据《JAVA并发编程的艺术》中的描述,
instance = new Singleton(); //instance是volatile变量这句Java代码会转变成汇编代码如下:
0x01a3de1d: movb $0x0,0x1104800(%esi);0x01a3de24:lock add1 $0x0,(%esp);
通过IA-32架构软件开发者手册可知,Lock前缀的指令在多核处理器下会引发两件事情:
- 将当前处理器缓存行的数据协会到系统内存。
- 这个协会内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
从Java内存模型(JMM)角度考虑,volatile写-读建立的是happens-defore关系,会在编译器在生成字节码时,在指令序列中插入内存屏障来禁止特定类型的处理器重排序,达到happens-defore的内存语义。为此,JMM采取保守策略,下面是基于保守策略的JMM内存屏障插入策略:
- [ ] 在每个volatile写操作的前面插入一个StoreStore屏障。
- [ ] 在每个volatile写操作的后面插入一个StoreLoad屏障。
- [ ] 在每个volatile读操作的后面插入一个LoadLoad屏障。
- [ ] 在每个volatile读操作的后面插入一个LoadLoad屏障。
所以,volatile的两个特性:单步原子性,可见性。其中单步原子性是通过在字节码中加入特殊指令,使用内存屏障在实现禁止一些处理器重排从而达到的。而可见性,也是通过在字节码中加入一个Lock前缀指令,实现将使用该变量的其他线程中的缓存行失效,使其必须从内存中读,从而达到的。
注:具体的JMM处理,详见关于volatile的Java内存模型
1.5 ReentrantLock锁的实现
提到ReentrantLock,就不得不提到Doug Lea。
“如果IT的历史,是以人为主体串接起来的话,那么肯定少不了Doug Lea。这个鼻梁挂着眼镜,留着德王威廉二世的胡子,脸上永远挂着谦逊腼腆笑容,服务于纽约州立大学Oswego分校计算机科学系的老大爷。” 这是百度百科对他的描述。他便是Java并发包(util.concurrent,简称J.U.C)的作者。在Java并发包中,我们可以看见大量volatile修饰的变量和Unsafe的原子性操作CAS。可以说正是因为这两项技术的成熟,才成就了Doug Lea的并发包。
在基本用法上,ReentranLock与synchronized很相似,他们都具备一样的线程重入特性,只是代码上有点区别,一个表现为API层面的互斥锁(lock()和unlock方法配合try/finally语句块来完成),一个表现为原生语法层面的互斥锁。不过ReentrantLock比synchronized增加了一些高级功能,主要有以下三项:等待可中断、可实现公平锁,一级锁可以绑定多个条件。
- [ ] 等待可中断是指当持有锁的线程长期不是放锁的时候,正在等待的线程可以选择放弃等待,改为处理其他事情,可中断特性对处理执行时间非常长的同步块很有帮助。
- [ ] 公平锁是指多个线程在等待同一锁时,必须按照申请锁的时间顺序来依次获得锁;而非公平锁则不保证这一点,在锁被释放的时,任何一个等待锁的线程都有机会获得锁。synchronized中的锁是非公平的,ReentrantLock默认情况下也是非公平的,但可以通过带布尔值的构造函数要求使用公平锁。
- [ ] 锁绑定多个条件是指一个ReentrantLock对象可以同时绑定多个Condition对象,而在sychronized中,锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含的条件,如果要和多余一个的条件关联的时候,就不得不额外地添加一个锁,而ReentrantLock则无须这样做,只需要多次调用newCondition()方法即可。
1.5.1 ReentrantLock的结构
ReentrantLock的实现依赖于Java同步器框架AbstractQueueSynchronizer(简称AQS)。AQS使用一个整形的volatile变量(命名为state)来维护同步状态,这个volatile变量是ReentrantLock锁实现的关键。下面我们先看一下ReentrantLock的类结构:
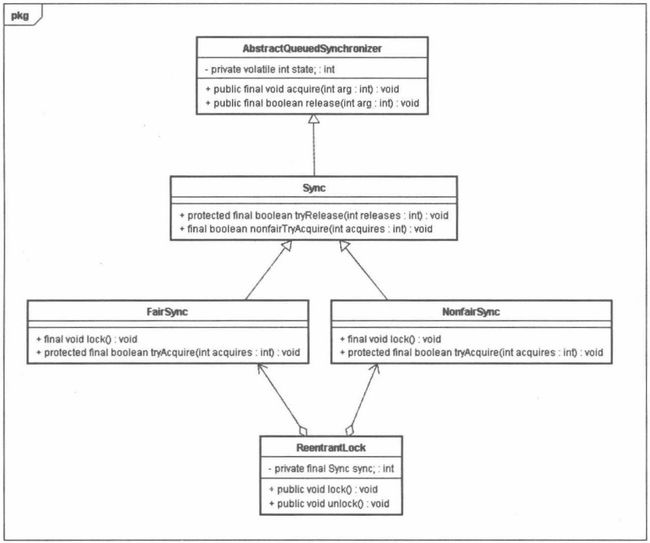
ReentrantLock的类图
1.5.2 公平锁-FairSync
ReentrantLock分为公平锁和非公平锁,我们首先分析公平锁。
使用公平锁时,加锁方法lock()调用轨迹如下:
1) ReentrantLock:lock().
2) FairSync:lock().
3) FairSync:acquire(int arg).
4) FairSync:tryAcquire(int arg).
在第四步真正开始加锁,下面是该方法的源代码。
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
// 判断临界区的情况
if (c == 0) {
// 判断当前线程是否在队首
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
// 如果在队首,就立即使用unsafe的CAS操作将state置为acquire
// 并将拥有线程置为当前线程
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
// 如果当前线程仍然是拥有线程,表示该线程是拥有锁的
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
// 直接修改state,并返回true
setState(nextc);
return true;
}
return false;
}以上代码可以看出中调用的方法其实都是ASQ中提供的方法,所以具体实现其实是同步器ASQ来实现的,不过从该方法中我们可以看到,整个过程其实就是在维护ASQ中的State整型变量。
state相当于操作系统中的互斥变量mutex。当state等于0时,表示当前没有线程在临界区,此时可以进入临界区。为了保证公平,ASQ需要判断当前等待队列中的第一个线程是否是当前线程,如果是才会允许进入(hasQueuedPredecessors()方法)。进入之后有两步操作,第一是使用CAS操作将state置为参数acquires,该参数表示当前占用的临近资源数,第二是将ASQ中的exclusiveOwnerThread置为当前线程,用于记录临界区中的占用线程。
当state不等于0,而临界区中的占用线程是当前线程,表示该线程是再次进入临界区,则需要将占用资源数增加acquire。另外,根据第三步如果第四步以上两个条件均不满足,则将此线程加入等待队列并阻塞。第三步的源代码和整体流程图如下:
public final void acquire(int arg) {
// 如果没有获取锁并且已经加入了等待队列,则就阻塞自己
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
在使用公平锁时,解锁方法unlock()调用轨迹如下:
1) ReentrantLock:unlock().
2) AbstractQueueSynchronizer:release(int arg).
3) AbstractQueueSynchronizer:tyrRelease(int releases).
在第三步真正开始释放所,下面是该方法的源代码:
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
// 该返回值是用于第三步,以此来判断是否需要唤醒等待队列的线程
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
// 释放锁的最后,更新volatile变量state
setState(c);
return free;
}从上面的源代码可以看出,在释放锁的最后更行了volatile变量state。在获取锁时,首先读这个volatile变量。根据volatile的happens-before规则,释放锁的线程在更新volatile变量之前可见的共享变量,在获取锁的线程读取同一个volatile变量后将立即变得对获取锁的线程可见。根本原因是,volatile本更新之后,处理器会通知所有使用该变量的线程(嗅探方式),使得他们的缓存行失效,只能从主存中读取volatile变量,并进行缓存行填充。
另外,如果该方法返回的是ture,即c为0,表示此时没有线程拥有此锁,需要将AQS拥有线程置为null唤醒等待队列的线程。而如果是false,该线程还没有完全释放完所有的锁。此逻辑是在第二步实现的,具体源代码和流程图如下:
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
// 判断等待队列中是否还有在等待唤醒的线程
if (h != null && h.waitStatus != 0)
// 此方法最终调用的是Unsafe的unpark(Thread)方法,用于唤醒一个线程。
unparkSuccessor(h);
return true;
}
return false;
}
1.5.3 同步器AbstractQueuedSynchronizer
通过ReentrantLock的公平锁可以看出,同步是靠AbstractQueuedSynchronizer类来实现的。
ASQ在初始化的时候,会初始化得到unsafe对象,为一些关键步骤提供原子性操作,保证同步。
ASQ维护了一个volatile变量state来表示锁的状态,对state的操作和线程的唤醒使用了unsafe中的本地方法来保证原子性和异步性。
AQS的等待队列是采用了一个基于FIFO的双向链表(简称sync队列),每个节点为位内部类Node,其中有五个重要的成员分别表示等待状态、前驱、后继、存储condition队列中的后继节点、入队列时的当前线程。他们均为volatile修饰。
节点成为sync队列和condition队列构建的基础,在同步器中就包含了sync队列。并且拥有三个成员变量来维护这个队列:sync队列的头节点head、sync队列的尾节点tail和状态state。AQS的内部类Condition,实现一个Lock可以绑定多个条件。其中每个condition对象维护一个FIFO的条件队列,并有该队列的头尾节点。所以说,一个同步器拥有一个同步队列和多个等待队列。如果所示:
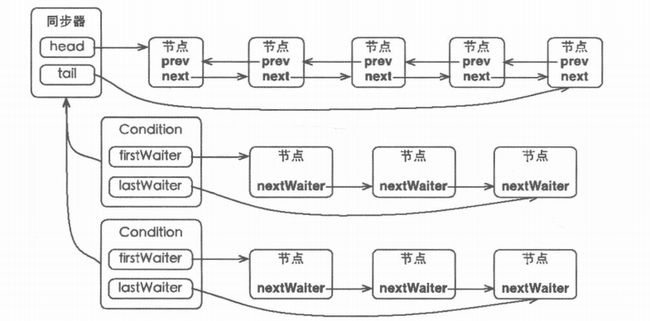
注:关于AbstractQueuedSynchronizer详细的介绍和原理分析,请点击这里。
另外,《JAVA并发编程的艺术》中的第五章详细的描述了ASQ各种API和实现原理。
1.5.4 总结
由于Java的CAS同事具有volatile读和colatile写的内存语义,因此Java线程之间的通信现在有了下面4中方式。
A线程写volatile变量,随后B线程读这个volatile变量。
A线程写volatile变量,随后B线程用CAS更新这个volatile变量。
A线程用CAS更新一个volatile变量,随后B线程用CAS更新这个volatile变量。
A线程用CAS更新一个volatile变量,随后B线程读这个volatile变量。
Java的CAS会使用现代处理器上提供的高效机器级别的原子指令,这些原子指令以原子方式对内存执行读-改-写操作,这是在多处理器中实现同步的关键(本质上来说,能够支持原子性读-改-写指令的计算机,是顺序计算图灵机的异步等价机器,因此任何现代的多处理器都会支持某种能对内存执行原子性读-改-写操作的原子指令)。同事,volatile变量的读/写和CAS可以实现线程之间的通信。把这些特性整合在一起,就形成了整个concurrent包得以实现的基石。如果我们仔细分析concurrent包的源代码实现,会发现一个通用化的实现模式。
首先,声明共享变量volatile。
然后,使用CAS的原子条件更新来实现线程之间的同步。
同时,配合以volatile的读/写和CAS所具有的volatile读和写的内存语义来实现线程之间的通信。AQS,非阻塞数据结构和原子变量类(java.util.concurrent.atomic包中的类),这些concurrent包中的基础类都是使用这种模式来实现的,而concurrent包中的高层类又是依赖于这些基础类来实现的。从整体来看,concurrent包的实现示意图如下:
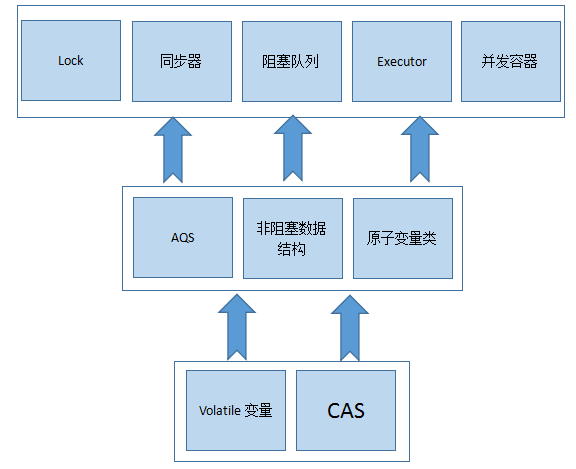
二、从ReentrantLock到ConcurrentHashMap
Java程序员进行并发编程时,相比于其他语言的程序员而言要倍感幸福,因为并发编程大师Doug Lea不遗余力地为Java开发者提供了非常多的并发容易和框架。接下来我们就以ConcurrentHashMap为例,见识一下大师的功力。
2.1 ConcurrentHashMap的结构
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。而Segment就是ReentrantLock,在ConcurrentHashMap里扮演者锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里面包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。具体的类图和结构图如下:
类图:
结构图:
不难看出,concurrentHashMap采用了二次hash的方式,第一次hash将key映射到对应的segment,而第二次hash则是映射到segment的不同桶中。这样就可以使得对于map的修改不会锁住整个容器,提高并发能力。
2.2 ConcurrentHashMap的初始化
如下是ConcurrentHashMap的初始化源码:
/**
* 初始化方法
* initialCapacity:初始化容量,默认16
* loadFactor:负载因子,默认0.75
* concurrencyLevel:并发量等级,默认16,最高65535。即为锁的数量,segment数组的大小(内部保证是不小于该数的2的幂次)
*/
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
// 保证ssize是2的幂次,为了能通过按位与实现散列算法
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// 初始化段偏移量和段掩码,需要在定位segment时的散列算法中使用
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 初始化segment
Segment s0 =
new Segment(loadFactor, (int)(cap * loadFactor),
(HashEntry[])new HashEntry[cap]);
Segment[] ss = (Segment[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
} CurrentHashMap的初始化一共有三个参数,一个initialCapacity,表示初始的容量,一个loadFactor,表示负载参数,最后一个是concurrentLevel,代表ConcurrentHashMap内部的Segment的数量,ConcurrentLevel一经指定,不可改变,后续如果ConcurrentHashMap的元素数量增加导致ConrruentHashMap需要扩容,ConcurrentHashMap不会增加Segment的数量,而只会增加Segment中链表数组的容量大小,这样的好处是扩容过程不需要对整个ConcurrentHashMap做rehash,而只需要对Segment里面的元素做一次rehash就可以了。
总的来说初始化过程是初始化了两个参数,加一个数组。两个参数分别是segmentShift(段偏移量)、segmentMask(段掩码),数组则是segments(concurrentHashMap的可重入锁)。而这三个都是有ssize变量间接得到的。
1. 首先通过并发等级,计算出不小于此数的最小2的次幂。这便是ssize。
2. segmentShift就是32与ssize幂次的差值。(这里的32是因为hash算法将每个对象的hashcode进行在hash得到的值最大是32二进制)
3. segmentMask就是ssize-1。
4. segments的大小便是ssize。默认情况下segmentShift是28,segmentMask是15,他们均是散列算法定位segment的两个参数。具体代码如下:
// Hash-based segment and entry accesses
/**
* Get the segment for the given hash
*/
@SuppressWarnings("unchecked")
private Segment segmentForHash(int h) {
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
return (Segment) UNSAFE.getObjectVolatile(segments, u);
} 另外,为什么ssize必须是2的次幂呢?因为这里用了一个很巧妙的位运算来定位segment下的hashentry数组的位置。其实两次定位用到的hash算法均是利用了2的幂次数这一个特点。我们可以从get方法看到,如下:
public V get(Object key) {
Segment s; // manually integrate access methods to reduce overhead
HashEntry[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// 取segments中的锁
if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
// 便利segment中的hashEntry
for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
} 分析第5行和第11行,这两行分别是定位segment的hash算法和在segment中的hashEntry数组定位entry的hash算法。他们的算法其实都是一样的,都是用再哈希的值和总长度-1的值按位与(segmentMask其实是ssize-1)。其中,只有当tab.length和ssize为2的幂次的时候,这个运算就相当于h%tabn.length(h%ssize)。另外,定位HashEntry和定位Segment的散列算法虽然一样,都是与数组的长度-1再相“&”,但是&的值不一样,定位Segment使用的是元素的hashcode通过再散列后得到的值的高位,而定位HashEntry直接使用的是再散列后的值。其目的是避免两次散列后的值一样,虽然元素在segment里散列开了,但是却没有再HashEntry里散列看。
2.3 ConcurrentHashMap的关键操作
2.3.1 get操作
Segment的get操作实现非常简单和高效。先经过一次对hashcode的再散列,然后使用这个散列值通过第一次的segmentForHash散列运算定位到Segment,再通过第二次的entryForHash散列算法定位到具体的元素。具体的get操作代码已经在上面列出了。
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。原因是它的get方法里将要使用的共享变量都定义成了volatile类型,如用于统计当前segement大小的count字段和用于存储值的HashEntry的value。而在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。像我们之前说的,加了volatile的value也不会读到过期的值了。这便是使用volatile替换锁的经典应用场景。
2.3.2 put操作
put操作涉及到内存的写,为了保证线程安全,则需要加锁。ConcurrentHashMap是分段锁,在运行下面关键代码之前,需要先散列算出segment数组中的位置,然后调用segment的ensureSegment方法。具体方法也很简单循环遍历判断key值,有责改并退出,无责增加,并考虑扩容。相比于hashmap的put方法无非就是在前后增加了lock锁,另外扩容不是整体扩容而是针对segment下的hashEntry扩容。下面便是ensureSegment的源代码:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry first = entryAt(tab, index);
for (HashEntry e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
if (node != null)
node.setNext(first);
else
node = new HashEntry(hash, key, value, first);
int c = count + 1;
// 是否扩容是看tab的大小是否超过了设定的值
// 设定的值是通过散列因子和初始化决定的,是在初始化的时候设置的
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
} 值得注意的是第17行和第35行的modCount变量,此变量是所有桶公用的变量,是用来统计变化数的,所以put、remove和clean方法里才做元素后都会将变量modeCount进行加1。这是为了统计size的时候用的,具体用法请看下一节。
另外在扩容的时候,首先会创建一个容量为原来容量两倍的数组,然后将原数组里的元素进行再散列后插入到新的数组里。下面是扩容的源代码:
private void rehash(HashEntry node) {
HashEntry[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry[] newTable =
(HashEntry[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry e = oldTable[i];
if (e != null) {
HashEntry next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry lastRun = e;
int lastIdx = idx;
for (HashEntry last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry n = newTable[k];
newTable[k] = new HashEntry(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
} 2.3.3 size操作
在前面的操作里,我们设计到的操作都是单个Segment中进行的,但是ConcurrentHashMap有一些操作是在多个Segment中进行,比如size操作,ConcurrentHashMap的size操作也采用了一种比较巧的方式,来尽量避免对所有Segment都加锁。
前面我们提到了一个modCount变量,代表的是对Segment中元素的数量造成影响的操作的次数,这个值只增不减,size操作就是遍历了两次Segment,每次记录Segment的modCount值,然后将两次的modCount进行比较,如果相同,则表示期间没有发生过写入操作,就将原先遍历的结果返回,如果不相同,则把这个过程在重复做一次,如果再不相同,则就需要将所有的Segment都锁住,然后一个一个遍历了。具体代码如下:
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
// 计算次数如果大于RETRIES_BEFORE_LOCK,就用锁
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
// 两次计算的相等,说明期间没有变化,直接返回
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
} 三、无需用锁的情况与单例模式的双重检验
要保证线程安全,并不是一定就要进行同步,两者没有因果关系。同步只是保障共享数据争用时的正确信的手段,如果一个方法本身就不涉及共享数据,那他自然局无须任何同步措施去保证正确性,因此会有一些代码天生就是线程安全的,下面简单的介绍其中的两类。
3.1 可重入代码(Reentrant Code)
这种代码也叫纯代码(Pure Code),可以在代码执行的任何时刻中断它,转而去执行另外一段代码(包括递归调用它本身),而在控制权返回后,原来的程序不会出现任何错误。相对线程安全来说,可重入性是更基本的特性,他可以保证线程安全,即所有的可重入代码都是现成安全的,但是并非所有的线程安全的代码都是可重入的。
可重入代码有一些共同的特征:例如不依赖存储在堆上的数据和公用的系统资源、用到的状态量都是由参数中传入、不调用非可重入的方法等。我们可以通过一个简单一些的原则来判断代码是否具备可重入性:如果一个方法,它的返回结果是可以预测的,只要输入了相同的数据,就都能返回相同的结果,那它就是满足可重入性的要求,当然也就是线程安全的。
3.2 线程本地存储(Thread Local Storage)
如果一段代码中所需要的数据必须与其他代码共享,那就看看这些共享数据的代码是否能保证在同一个线程中执行?如果能保证,我们就可以把共享数据的可见范围限制在同一个线程之内,这样,无须同步也能保证线程之间不出现数据争用的问题。
符合这种特点的应用并不少见,大部分使用消息队列的架构模式(如“生产者-消费者”模式)都会将产品的消费过程尽量在一个线程中消费完,其中最重要的一个应用实例就是经典Web交互模型中的“一个请求对应一个服务器线程”(Thread-per-Request)的处理方式。在Tomcat源码中我们可以发现每一个请求来的时候都会用一个单独的线程进行处理,这种处理方式的广泛引用使得Web服务端的很多应用都可以使用线程本地存储来解决线程的安全问题。如下图:
另外,Java语言中,如果一个变量要被多个线程访问,可以使用volatile关键字声明它为“易变的”;如果一个变量被某个线程独享,因为Java中没有类似C++中_declspec(thread)这样的关键字,不过可以通过java.lang.ThreadLocal类来实现线程本地存储的功能。每一个线程的Thread对象中都有一个ThreadLoaclMap对象,这个对象存储了一组以ThreadLocal.threadLocalHashCode为键,以本地线程变量为值的K-V值对,ThreadLocal对象就是当前线程的ThreadLocalMap的访问入口,每一个ThreadLocal对象都包含了一个独一无二的threadLocalHashCode值,使用这个值就可以在县城K-V值对中找回对应的本地线程变量。
3.3 单例模式的双重检验
首先来看一下一个正确的最简单的饿汉式单例模式
/**
* 饿汉式单例模式Demo
* com.xiaocao Singleton.java
* @author muxiaocao {http://www.muxiaocao.me}
* @github {https://github.com/MuXiaoCao}
* @time 2016年8月24日
*/
public class SingletonDemo {
/**
* 必须为volatile
*/
private static volatile SingletonDemo instance;
private SingletonDemo() { }
public static SingletonDemo getInstance() {
/**
* 第一重检验:可去掉
*/
if (instance == null) {
/**
* 必须上锁
*/
synchronized (instance) {
/**
* 第二重检验:必须加
*/
if (instance == null) {
instance = new SingletonDemo();
}
}
}
return instance;
}
}需要注意的地方有三个:
1. 双重检验的第二重必须有。
假设有两个并发线程A和B执行getInstance(),最开始的时候instance为null,最在一个线程初始化之前AB线程均可以通过第一重检验进入if语句,等待instance锁。那么当A现成初始化完,B继续执行还会进行一遍初始化,这就违反了单例模式。
2. instance的volatile关键字必须有。
因为SingletonDemo的初始化动作并非是一个原子性的,至少需要开辟内存、执行初始化方法、引用指向三步操作。假设AB两个线程并发执行,当A执行初始化的时候,由于处理器重排,先执行了引用指向,还没来得及执行初始化方法的时候,执行B。这时候对于B来说instance不为null,所以直接返回。那么当B再调用方法的时候,就会出现错误了,因为这时候还没有初始化完成。而当加了volatile,就会使用内存屏障机-StoreLoad,禁止了这种处理器重排,那就不会出现上述情况了。
3. 第一重检验理论上是可以去掉的,但是处于性能的考虑最好加上。
四、一个有趣的Java多线程题目
public class ThreadTest {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
thread.stopThread();
}
public static class MyThread extends Thread{
private boolean isStop = false;
@Override
public void run() {
int i = 0;
for(;;) {
i++;
if (isStop) {
break;
}
}
System.out.println("stop thread");
}
public void stopThread() {
isStop = true;
}
}
}- 此程序会正常终止吗?
- 在for循环里增加一个System.out.println()就会停止,为什么呢?
- 将isStop改为volatile变量,程序也会正常终止,为什么呢?
注意:转载请标明,转自itboy-木小草。
尊重原创,尊重技术。